
深度学习基本概念
【什么是深度学习】
通过 多层 非线性 变换对高复杂度数据建模的算法的合集。
【什么是神经网络】
【前馈神经网络】:分为两种
【反向传播网络(BP)】:
【径向基函数神经网络(RBF)】
【神经网络的训练】
【epoch】:完整迭代一遍数据即为一个 epoch
【batchsize】:在内存效率和内存容量之间寻找的最佳平衡。
【为甚么要有多个epoch】:因为不是迭代一次所有数据参数就达到最优了,需要不断迭代更新。
我们在寻找波谷,先说每次迭代使用全体数据的情况:
迭代一次更新一次参数信息,当被更新的参数仍然没有找到波谷时,即我们没有看到一个明显的拉升拐点,仍需要再次使用全体数据进行迭代,更新参数,这就进入了第二个epoch。
一般在全体数据更新时也需要多轮迭代
在使用batchsize进行参数更新时,同理也需要多个epoch。
参数更新过程如下图所示:每一个点代表一个epoch。
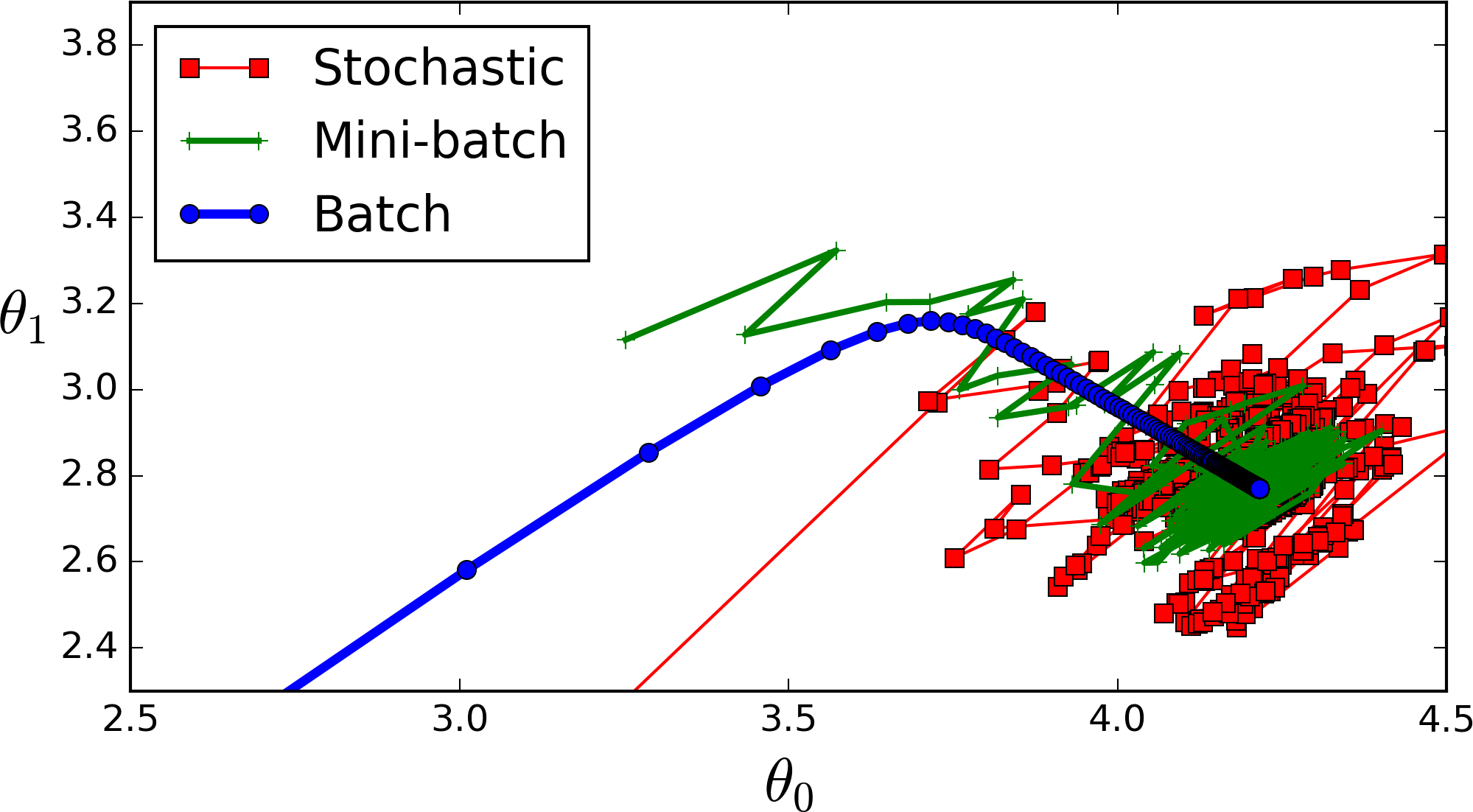
【线性模型的局限性】
1 多层线性模型/线性网络的组合,仍然是线性的——只通过线性变换,多层的全连接线性神经网络与单层神经网络的作用是相同的。如果一个问题可以用一条直线划分,那么这个问题可以用线性模型解决。对于线性不可分问题无法处理。
2 异或问题 本质上是线性不可分问题,感知机(单层神经网络-线性分类器),无法解决线性问题。同样多层的线性网络组合也不能解决异或问题。
3 通过激活函数可以实现与或非运算,实现异或运算则需要在使用激活函数实现与或非运算的的基础上加深网络深度。【自己的理解】
【激活函数实现去线性化】:实质上是对线性模型的结果再进行变换处理
激活函数可以曲线型
【多层网络解决异或问题】
多层网络,去线性后可以解决异或问题。可在TensorFlow游乐场中测试。
【疑问】x1*x2 引入,单层神经网络也可解决异或问题?- 参考《机器学习》
【常用激活函数】
【自定义激活函数】
【损失函数】:神经网络的训练过程即是寻找使损失函数最小的参数组的过程!
【经典损失函数】
【分类问题-交叉熵】:神经网络解决分类问题输出为一个 n维向量,n为类别数。理想的分类结果为 【0,1,0,0,0】,实际预测结果为【0.1,0.8,0.05,0.05,0】
评估实际预测结果与理想结果之间的接近程度的方法:交叉熵。交叉熵刻画两个概率分布之间的距离。
SoftMax函数,将神经网络前向传输结果转换为概率分布,即【0.1,0.8,0.05,0.05,0】
【回归问题-MSE】
【自定义损失函数】
3【网络优化】
【反向传播与梯度下降算法】
梯度下降算法:用于优化单个参数的取值。梯度下降算法会的带式更新参数,沿着梯度的反方向让参数最小。
反向传播:【疑问】所有参数上使用梯度下降算法。最终是一个多变量函数凸优化问题。
损失函数一般表现为不规则形式,没法直接求导,通过求偏导数的大概值,更新参数信息。
【网络层数与损失函数】:
后一层是对前一层的输出进行处理,实际上就是函数的嵌套。层数越多,求偏导时连成越长,容易引发梯度消失与梯度爆炸。
梯度消失、梯度爆炸:
【基础优化方法】
【学习率】:每完整的迭代一遍训练数据,学习率就减少一次。训练过程中会对数据完整迭代多轮。
初始学习率:初始值
衰减系数:系数
衰减速度:步长
【优化方法选择】
4 【过拟合】
【过拟合的原因】:
1 样本少,不足以反应共性,
2 模型过于复杂,参数过多,拟合能力过强
【正则化】:在损失函数中加入权重项
【滑动平均模型】:模型参数更新过程中会维护一个影子参数组。每一轮迭代时更新影子参数组,当前参数值与影子参数相同。
衰减率:一般会设置成非常接近1,例如:0.999
【Droupout原理】
【验证集、测试集】
【验证集】的目的是为了防止过拟合,寻找过拟合的拐点:在深度学习训练工程中,训练集的损失会不断减小,验证集的损失会先减小,后增大。这个拐点的位置就是过拟合的开始,训练到这里就不要训练了。
【测试集】用于训练模型参数:对于超参数的选择,我们没有一个固定的方法,只能不断尝试。测试用于比较不同超参数条件下模型的效果。或者比较不同模型,做模型选择?
【超参数】:需要有深度学习程序开发者手动设置的参数被称为超参数
【有了验证集为什么还需要测试集】
【模型评估】- 做到什么程度算是可以。
【梯度问题】
【梯度消失】:
【梯度消失的表现形式】:参数更新过慢,训练不再收敛
【引发原因】:层次越多,小于1的梯度连成造成最终得到的导数近似值很小,参数更新极为缓慢!
早期 神经网络使用了Sigmoid激活函数,对Sigmod激活函数进行求导会产生一个常数项 1/4,在层数较深情况下容易发生梯度消失
【解决办法】
引用自:https://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650324619&idx=1&sn=ca1aed9e42d8f020d0971e62148e13be&scene=1&srcid=0503De6zpYN01gagUvn0Ht8D#wechat_redirect

【梯度爆炸】梯度溢出导致网络参数NAN。梯度溢出的根本原因是网络参数初始化的尺度不平衡问题。
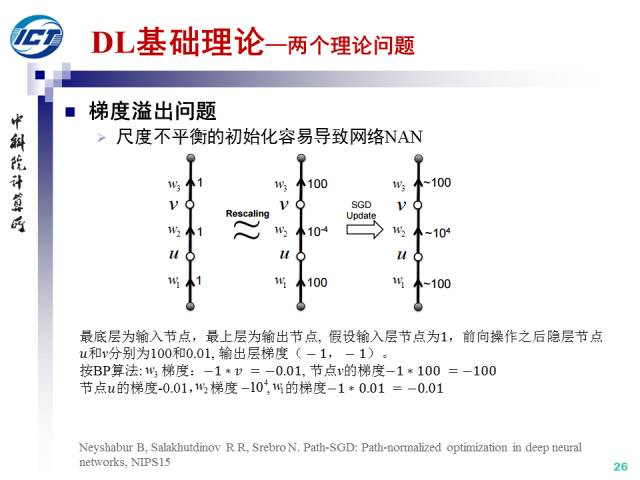
【解决办法】: 为了解决这个问题,Bengio等人提出了Xavier初始化策略,其基本思想是保持网络的尺度不变。
5【经验风险最小化与结构风险最小化】
经验风险最小化对应-交叉熵,MSE
结构风险最小化对应-正则化-在损失函数值增加结构参数项

 浙公网安备 33010602011771号
浙公网安备 33010602011771号