
谈谈交叉熵损失函数
一.交叉熵损失函数形式
现在给出三种交叉熵损失函数的形式,来思考下分别表示的的什么含义。
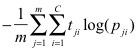
--式子1
--式子2

--式子3
解释下符号,m为样本的个数,C为类别个数。上面三个式子都可以作为神经网络的损失函数作为训练,那么区别是什么?
■1》式子1,用于那些类别之间互斥(如:一张图片中只能保护猫或者狗的其中一个)的单任务分类中。连接的 softmax层之后的概率分布。
tensorflow中的函数为: tf.nn.softmax_cross_entropy_with_logits
■2》式子2,用于那些类别之间不存在互斥关系(如:一张图片中可有猫和狗两种以上的类别同时存在)的多任务学习分类中。最后一层的每个节点不在是softmax函数的输出了,而是sigmoid。把每个节点当成一个完整的分布,而式子1是所有节点组合程一个完整分布。
tensorflow中的函数为:tf.nn.sigmoid_cross_entropy_with_logits
■3》式子3,用于最后一层只有一个节点的二分类任务
二.交叉熵损失意义
要解释交叉熵损失函数的意义,我认为应该从熵的根源说起。这里我不介绍熵作者呀,来源呀什么的不再介绍了(主要是懒),哈哈!)这里讲的顺序是:信息量--》信息熵--》交叉熵
1.信息量
意义:
如果一个事件发生的概率为p,那么获知该信息发生能给到我们 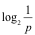 的信息量(可以理解为意外程度)
的信息量(可以理解为意外程度)
例子:巴西跟中国乒乓球比赛,历史上交手64次,其中中国获胜63次,那么63/64是赛前普遍认为中国队获胜的概率,那么这次中国获胜的信息量有多大?
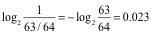
如果这次是巴西获胜,那么带给我们的信息量为:
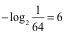
单位:bit
如果一件事件的发生概率为:100%,带给我们的信息量为:0
通俗点讲就是,如果一件事情,本身发生的概率很大,如果再次发生,我们并没有觉得有什么好奇的。但是一件发生概率很小的事情发生了,我们就会非常惊讶,它能给到我们的信息就越有价值。例如:太阳每天都是从东边出来,这个概率几乎是1,所以我们都其以为常,没什么好惊讶的,但是某天太阳从西边出来了,这个时候,打破了我们的常识,这个概率非常小的事件居然发生了,我们就会非常惊讶,它给我们信息量是非常大的,也许我们可以根据这个现象发现一种新的东西。
2.信息熵
意义:
用来做信息的杂乱程度的量化描述。
定义:
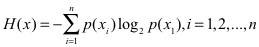
1.中国队获胜概率: 63/64,巴西获胜概率:1/64,那么信息熵为:
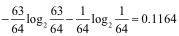
2.中国队获胜概率: 1/2,巴西获胜概率:1/2,那么信息熵为:
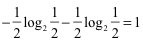
3.中国队获胜概率: 1,巴西获胜概率:0,那么信息熵为:
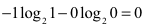
结论:
信息越确定,越单一,信息熵就越小,
信息越不确定,越混乱,信息熵就越大。
注意:这里的log以2为底,实际上可以与e,10等其他为底,主要对比的时候统一就好。从计算机角度来看,计算机只有0,1两位,用2比较符合。
3.交叉熵
意义:
衡量真实分布和预测的分布的差异情况
离散形式为:
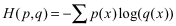
其中,p(x)为真实概率,q(x)为预测概率
从信息量的角度,如果是真是真实的概率,那么给到我们的信息熵为:
如果是预测分布,改到我们信息熵(可以简单理解为信息量)为:
信息熵的差异为:
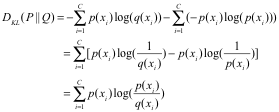
这也叫:K-L散度
可以看出,只有当q(x)=p(x)时候差异为:0
K-L散度始终是>=0,但是不知道怎么证明(我还没推导出来惭愧,以后推导出来再补充,如果有读者推出来,麻烦评论,非常感谢!)
问题:
为什么大多数情况,我们都用交叉熵而不是K-L散度作为损失函数?
我来分析下:仔细观察k-l散度,如果是多分类时候,one-hot形式【0,1,0,0】,那么把p(x)=0,1,0,0,带入K-L散度函数,那么其实跟交叉熵形式是一样的。
例如:在多一个4分类任务时候,计算其中一个样本的第2个类别损失,其one-hot形式,【0,1,0,1】,模型预测出来的概率分布为:【0.1,0.6,0.2,0.1】
那么如果是K-L散度作为损失,那么:
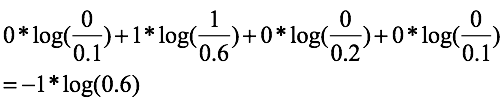
实际就是:-p(x)*log(q(x))
这下明白了吧。
参考:
2.https://www.reddit.com/r/MachineLearning/comments/4mebvf/why_train_with_crossentropy_instead_of_kl/
3.书籍《白话大数据》第六章信息论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号