
XML
1. 什么是XML?
XML:可拓展标记语言(Extensible Markup Language)
本质上就是一个纯文本文件,内部采用:标记+数据的形式,使数据更加有层次感
<book>存储信息</book>
xml文件的设计宗旨是传输数据,常常用作配置文件,很少为了存储数据的目的而使用.
存储大量数据时,可读性可维护性非常好
2. 为什么xml
xml文件的设计宗旨是传输数据
xml存储大量数据时, 内部采用:标记+数据的形式,使数据更加有层次感,可读性可维护性非常好,
所以,xml在java中常常用作配置文件,很少为了存储数据的目的而使用. 1).做配置文件【以后常用】:Tomcat容器、SSM框架底层采用的都是xml做配置文件;
3. xml和html文件的区别
xml是w3c的推荐标准
先有鸡还是先有蛋?HTML是由SGML改进生成的,随后才有的XML,时至今日,XML仍然被广泛应用,纵使json的出现减少了xml的使用
借鉴别人的一句话,
json用20%的时间做了80%的事情,而它也就只能完成这80%的事情;xml用120%的时间做了100%的事情
HTML文件本质上也是xml文件(html文件去掉头文件,将单标签加上结束符号使得符合html5标准,就是一个正确的可以被dom4j解析” XML”文件)
html被设计用来显示数据,xml被设计用来传输数据
xml被设计为传输和存储数据,其焦点是数据的内容
4. XML语法概述
4.xml就是纯文本文件,<标签名>+数据+<标签名/>
4.2xml文档的整体结构包含
文档声明:声明文档版本和编码
1.1版本不兼容1.0,一般使用1.0版本
标签 : 是xml文件中的重要内容,其实就是给内容起个名字
属性: 任何标签都可以定义若干个属性
注释: 和html文档一样,注释使用<!-- -->
转义字符:对于在xml文件中有特殊语义的字符,需要进行转义才能显示
CDATA区:如果存储大量需要对字符进行转义的内容,一般放到CDATA区内,CDATA区内的内容不需要转义
5. xml文档声明
xml文档声明可有可无
一个xml文档建议编写文档声明
文档声明的作用:给xml的编辑器或者解析器看的,不会显示
3).语法说明:
1).<?xml 声明内容 ?>
2).只有两个属性:
1).version :xml版本号,只能写:"1.0"或者"1.1",目前使用"1.0";
2).encoding : 此xml文件中使用的编码,如果包含中文:UTF-8
4).其它说明:
1).文档声明不是必须的(建议写),如果没有,不影响显示和解析;
2).如果写文档声明,一个文档中只能有一个文档声明;
3).如果写文档声明,必须位于此文档的0行0列的位置,前面不能有空行、空格、注释
6. xml标签
1).元素(标签):是XML文档中重要的内容。它其实就是对数据起的一个“名字”。
2).元素名称:由程序员自由定义
3).元素的分类:
1).完整标签:<name>张三</name>
2).单标签:<br/>
4).元素的命名规则:
1).只能包含一些“字符(包括中文)”,“数字”,“_,-,:,.”
2).不能以:数字、-、.开头。
3).不能包含:空格
7.xml属性
1).任何的元素(完整标签,单标签)都可以定义“若干的属性”;
<property name="driverClass">com.mysql.jdbc.Driver</property>
2).属性定义格式:
1).必须定义在“开始标签”中。
2).每个属性:属性名 = “值”。"值"必须用一对单引号或者双引号括起来。
3).多个属性之间使用“空格”隔开。
4).多个属性,不能有同名的。
8.xml注释
1).跟HTML一样:<!-- 注释内容 -->
2).注意书写的位置:
1).不能“文档声明”前面;
2).不能写在标签内部:
<student <!--学员信息-->>
</student>
3).不能嵌套:
<!--
<!-- 内容 -->
-->
9.xml转义字符
1).为什么要用转义字符:
<code> a < b </code><!--编译错误-->
如果我们的数据中,包含了一些XML的格式符号,将会引起编译错误:
这时,可以使用“转义字符”:
2).转义字符:
< < 小于
> > 大于
" " 双引号
' ' 单引号
& & 和号
3).例如:
<code>
String str = "jfkw28392fjkls";
int count = 0;
for(int i = 0;i < str.length() ; i++){
char c = str.charAt(i);
if(c >= '0' && c <= '9'){
count++;
}
}
System.out.println("count = " + count);
</code>
需要转义:
<code>
String str = "jfkw28392fjkls";
int count = 0;
for(int i = 0;i < str.length() ; i++){
char c = str.charAt(i);
if(c >= '0' && c <= '9'){
count++;
}
}
System.out.println("count = " + count);
</code>
10.xml CDATA区
1).如果标签内容中包含了大量需要转义的字符,使用大量的转义字符后,会使可读性下降,也不容易编写,
所以可以使用:CDATA区:
2).例如:
<code>
<![CDATA[ <!--内部所有的内容全部作为数据解析 -->
String str = "jfkw28392fjkls";
int count = 0;
for(int i = 0;i < str.length() ; i++){
char c = str.charAt(i);
if(c >= '0' && c <= '9'){
count++;
}
}
System.out.println("count = " + count);
]]>
</code>
解析xml
1.XML_XML解析_DOM_SAX_PULL_三种解析方式介绍
1).DOM解析:将每个元素以及内容分别封装为“对象”,并且设置关联,最终在内存中保留了整个文档的结构。
好处:会在内存中保留整体文档的结构,可以对“元素”进行:删除、添加。
缺点:将文档的所有内容全部加装到内存,比较耗内存。
2).SAX解析:逐行解析,没有上下文的概念。
优点:快
缺点:内部没有结构的顺序关系,不能对元素进行:删除、添加。
3).PULL解析:Android内部使用解析方式。
2.XML_XML解析_几种解析工具介绍
1).JAXP:Java类库提供的对XML的最基本的解析类库,可以使用SAX,也可以使用DOM解析。操作起来比较困难。
2).JDom:跟dom4j相似,但不常用。
3).jsoup:对HTML解析。项目中会讲解;
4).Dom4j : 全世界比较出名的解析工具。内部采用:DOM + SAX。Hibernate框架内部采用的就是dom4j。
3.XML_XML解析_XML解析原理及DOM模型:
1).XML的解析工具如果DOM方式解析,会根据XML文档中的标签结构,生成:DOM树(dom模型).
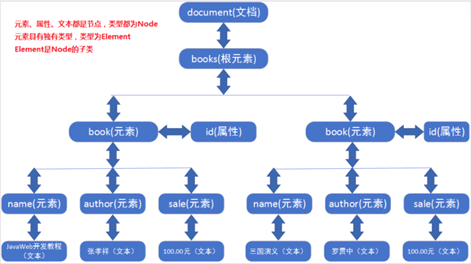
4.XML_XML解析_dom4j的使用步骤_常用类和方法【重点】
1).dom4j是第三方开发包,所以需要将第三方jar包复制到项目下。
2).常用类:
1).SAXReader
2).Document(dom树)
3).Element(元素)
3).常用方法:【Element的常用方法】
1).public List elements():获取当前元素下所有的“子元素”
2).public List elements(String tagName):获取当前元素下所有的tagName名称的“子元素”。
3).public String getName():获取“标签名”;
4).public String getText():获取“标签的值”;
5).public String elementText(String subTagName):获取当前元素的“subTagName”子元素的值。
6).public String attributeValue(String attName):获取当前元素的"attName"属性的值。
5.XML_XML解析_dom4j结合XPath解析XML
1).之前使用dom4j解析,必须从根节点开始,如果要解析多层(4-5层以上)的标记,就非常麻烦,所以又提出了XPath的解析方式:
2).使用步骤:dom4j也支持XPath解析。
1).创建SAXReader对象
2).读取XML文件,生成document对象;
3).两个常用方法:
List selectNodes("路径");获取多个元素
Node selectSingleNode("路径"):获取单个元素
4).路径:
1)."/根节点/子节点/孙节点":
2)."//任意节点/子节点"
3)."//节点[@属性名 = 值]
xml约束
1.XML_约束的概念_含义_作用【重点】
1).xml中的标记是由我们程序自己定义的,当我们为某个应用设计出一个xml文档时,这个文档中可以出现哪些标签,基本已经固定了。如果不做任何“限制”,是可以添加任何标签的,但这不符合我们的业务要求。
2).所以:XML又提出一个“概念”:对XML文档进行约束;
可以:
1).XML文档中可以出现哪些标签;
2).这些的标签的前后顺序;
3).这些标签的出现次数;
4).这些标签有哪些属性?哪些必须的?什么类型的值?
...
3).XML约束有两种:
1).DTD约束:比较简单,对中、小型的xml文件进行约束。
2).Schema约束:比较复杂,对大型的xml文件进行约束。可以详细的约束到“数据类型”
不添加任何约束
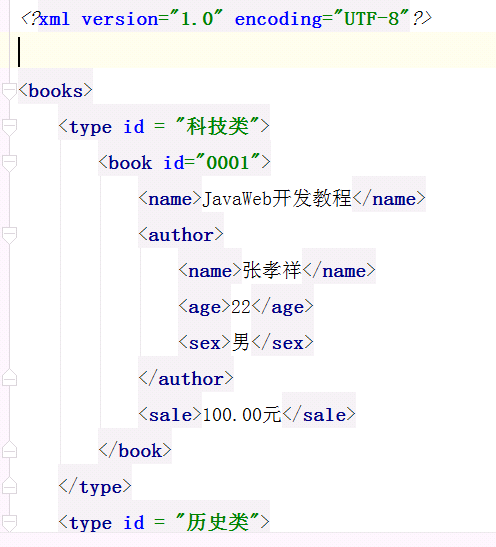
编写dtd约束
<?xml version="1.0" encoding="utf-8" ?> <!ELEMENT books (book+)> <!ELEMENT book (name,author,sale)> <!ELEMENT name (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT sale (#PCDATA)>
添加dtd约束结果:
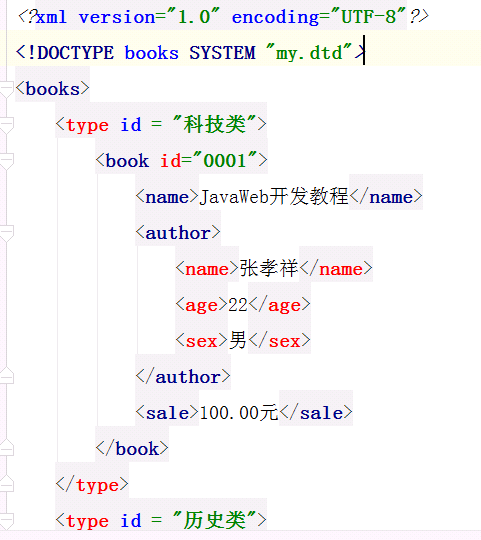
添加Schema约束
<?xml version="1.0" encoding="UTF-8" ?> <!-- 将注释中的以下内容复制到要编写的xml的声明下面 复制内容如下: <书架 xmlns="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.itcast.cn bookshelf.xsd" > --> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn" elementFormDefault="qualified"> <xs:element name='books' > <xs:complexType> <xs:sequence maxOccurs='unbounded' > <xs:element name='书' > <xs:complexType> <xs:sequence> <xs:element name='书名' type='xs:string' /> <xs:element name='作者' type='xs:string' /> <xs:element name='售价' type='xs:double' /> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
设置约束
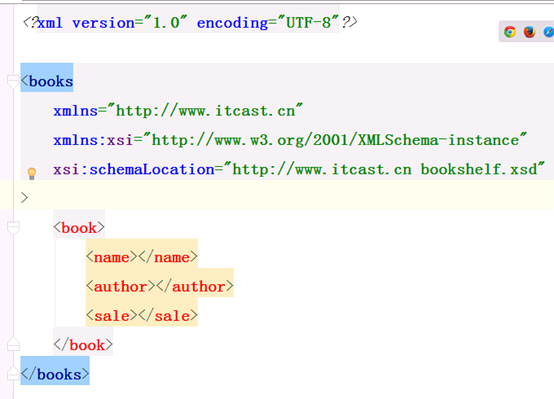
代码:
<?xml version="1.0" encoding="UTF-8"?> <books xmlns="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.itcast.cn bookshelf.xsd" > <book> <name></name> <author></author> <sale></sale> </book> </books>

