

Caffe实战(十一):caffe单个图像分类测试的方法总结
对于训练好的模型,通常需要输入一些其它图像进行测试,用来判断训练好的模型的准确率。由于是单幅图像,或者少数图像的分类测试,转换为lmdb或leveldb格式,再利用caffe工具进行测试比较麻烦。这里总结一些测试图像分类结果的方法,方便今后使用。
方法一:利用caffe自带的classification工具(C++)
caffe中自带图像分类工具classfication.exe,对输入一张图片,输出分类结果。源码在caffe\examples\cpp_classification\classification.cpp rem 分类工具 rem 参数(1)网络模型定义文件 rem 参数(2)权值文件 rem 参数(3)均值文件 rem 参数(4)同义词词集文件(标签类别) rem 参数(5)输入图像 ..\\..\\Build\\x64\\Release\\classification.exe ..\\..\\models\\bvlc_reference_caffenet\\deploy.prototxt ..\\..\\models\\bvlc_reference_caffenet\\bvlc_reference_caffenet.caffemodel ..\\..\\data\\ilsvrc12\\imagenet_mean.binaryproto ..\\..\\data\\ilsvrc12\\synset_words.txt ..\\..\\examples\\images\\cat.jpg
分类结果如下所示:
方法二:利用caffe自带的classify.py工具(python)
caffe开发团队实际上也编写了一个python版本的分类文件,路径为 python/classify.py
运行这个文件必需两个参数,一个输入图片文件,一个输出结果文件。分类的结果保存为当前目录下的xxx.npy文件里面,是看不见的。而且这个文件有错误,运行的时候,会提示“Mean shape incompatible with input shape”的错误。因此,要使用这个文件,我们还得进行修改:
(1)修改均值计算:
定位到 mean = np.load(args.mean_file) 这一行,在下面加上一行: mean=mean.mean(1).mean(1) 则可以解决报错的问题。
(2)修改文件,使得结果显示出来:
定位到 # Classify. start = time.time() predictions = classifier.predict(inputs, not args.center_only) print("Done in %.2f s." % (time.time() - start)) 这个地方,在后面加上几行,如下所示: # Classify. start = time.time() predictions = classifier.predict(inputs, not args.center_only) print("Done in %.2f s." % (time.time() - start)) imagenet_labels_filename = '../data/ilsvrc12/synset_words.txt' labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') top_k = predictions.flatten().argsort()[-1:-6:-1] for i in np.arange(top_k.size): print top_k[i], labels[top_k[i]]
修改完成之后,调用指令:
rem 测试ilsvrc12训练后的分类结果 rem 参数(1)--model_def 模型文件 rem 参数(2)--pretrained_model 训练权值参数 rem 参数(3)--center_only 中心裁剪(可能??) rem 参数(4)cat.jpg 输入图像 rem 参数(5)foo 测试结果存放文件 cd E: cd E:\Learning\caffe\Microsoft\caffe python2 tools-my\\classify_python\\classify_ilsvrc12.py --model_def models/bvlc_reference_caffenet/deploy.prototxt --pretrained_model models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel --mean_file data/ilsvrc12/ilsvrc_2012_mean.npy --center_only examples/images/cat.jpg tools-my\\classify_python\\result.npy
测试结果如下:
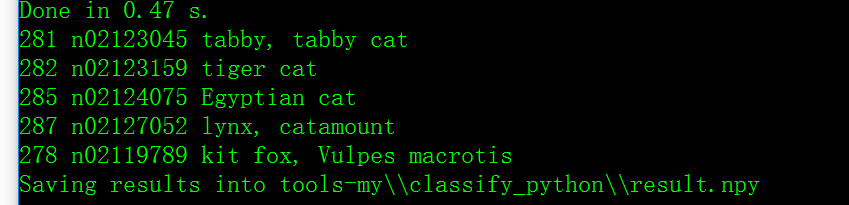
特别注意:这里使用的是ilsvrc_2012_mean.npy均值文件(caffe/python中自带的),可以通过“ numpy.load(args.mean_file)”加载该文件;不能使用caffe自带的计算均值工具“compute_image_mean.exe”输出的“imagenet_mean.binaryproto”文件。否则,会提示“ValueError: Object arrays cannot be loaded when allow_pickle=False”之类的错误。
因此,在进行cifar10测试过程中,由于使用的是“mean.binaryproto”文件,利用“ numpy.load(args.mean_file)”加载总是失败(不符合类型要求),需要修改成cifar_mean.npy格式的均值文件或者修改相应的python代码使之能够加载二进制文件。(Python还不是很熟,有时间了研究下)
将mean.binaryproto转换为mean.npy过程如下所示:
# 编写一个函数,将二进制的均值转换为Python的均值 def convert_mean(binMean, npyMean): blob = caffe.proto.caffe_pb2.BlobProto() # 声明一个blob bin_mean = open(binMean,'rb').read() # 打开二进制均值文件 blob.ParseFromString(bin_mean) # 将二进制均值文件读入blob arr = np.array(caffe.io.blobproto_to_array(blob)) # 将blob转换为numpy array npy_mean = arr[0] print arr.shape # arr是四维array,第一维表示第一图,其实就是唯一一张均值图 np.save(npyMean, npy_mean) binMean = caffe_root + 'data\\cifar10\\mean.binaryproto' npyMean = caffe_root + 'data\\cifar10\\mean.npy' convert_mean(binMean, npyMean)
(3)改进显示结果
上面的方式存在不足之处:
- 标签文件的路径写死在代码中;
- 只显示的分类的结果,没有显示对应的分类概率值。
【添加pandas库】 import pandas as pd 【增加命令行参数】 将标签文件路径作为参数传入进来,定义为"--labels_file";另外,添加参数"--print_results"用来选择是否显示结果信息。 parser.add_argument( "--print_results", action='store_true', help="show classify result." ) parser.add_argument( "--labels_file", default='data/ilsvrc12/synset_words.txt', help="labels file." ) 【添加显示结果信息】 # show classify result by caisenchuan 2019.11.21 # define --print_results and --labels_file. if args.print_results: scores = predictions.flatten() with open(args.labels_file) as f: labels_df = pd.DataFrame([ { 'synset_id': l.strip().split(' ')[0], 'name': ' '.join(l.strip().split(' ')[1:]).split(',')[0] } for l in f.readlines() ]) labels = labels_df.sort_values('synset_id')['name'].values indices = (-scores).argsort()[:5] ps = labels[indices] meta = [ ( p, '%.5f' % scores[i]) for i,p in zip(indices, ps) ] print(meta)
调用方式:
rem 测试ilsvrc12训练后的分类结果 rem 参数(1)--model_def 模型文件 rem 参数(2)--pretrained_model 训练权值参数 rem 参数(3)--center_only 中心裁剪(可能??) rem 参数(4)--print_results 打印分类结果信息 (自定义) rem 参数(5)--labels_file 标签文件 (自定义) rem 参数(6)cat.jpg 输入图像 rem 参数(7)foo 测试结果存放文件 cd E: cd E:\Learning\caffe\Microsoft\caffe python2 tools-my\\classify_python\\classify.py --model_def models/bvlc_reference_caffenet/deploy.prototxt --pretrained_model models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel --mean_file data/ilsvrc12/ilsvrc_2012_mean.npy --center_only --print_results --labels_file data\\ilsvrc12\\synset_words.txt examples\\images\\cat.jpg tools-my\\classify_python\\result.npy
显示结果如下:

注意:synset_words.txt需要在类别名称前加上标号,而且千万注意最后一行不能为空,如下所示:
0 airplane 1 automobile 2 bird 3 cat 4 deer 5 dog 6 frog 7 horse 8 ship 9 truck
后期可以进一步修改,输出类似classfication.exe工具结果样式。
方法三:python方法(网上的测试样例)
#coding=utf-8 import numpy as np import sys,os # 设置caffe根目录 caffe_root = 'E:\\Learning\\caffe\\Microsoft\\caffe\\' print(sys.path) sys.path.insert(0,caffe_root + 'Build\x64\Release\pycaffe') import caffe os.chdir(caffe_root) # 网络模型与权值文件路径 net_file = caffe_root + 'models\\bvlc_reference_caffenet\\deploy.prototxt' caffe_model = caffe_root + 'models\\bvlc_reference_caffenet\\bvlc_reference_caffenet.caffemodel' mean_file = caffe_root + 'data\\ilsvrc12\\ilsvrc_2012_mean.npy' # 初始化网络以及Transformer net = caffe.Net(net_file, caffe_model, caffe.TEST) transformer = caffe.io.Transformer({'data':net.blobs['data'].data.shape}) transformer.set_transpose('data',(2,0,1)) transformer.set_mean('data',np.load(mean_file).mean(1).mean(1)) transformer.set_raw_scale('data',255) transformer.set_channel_swap('data',(2,1,0)) # 加载测试图像,正向传播 im = caffe.io.load_image(caffe_root + 'examples\\images\\cat.jpg') net.blobs['data'].data[...] = transformer.preprocess('data',im) out = net.forward() # 加载类别标签文件 imagenet_labels_filename = caffe_root + 'data\\ilsvrc12\\synset_words.txt' labels = np.loadtxt(imagenet_labels_filename, str, delimiter = '\t') # 输出概率最大的前5组分类结果 top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1] for i in np.arange(top_k.size): print top_k[i], labels[top_k[i]]

