

Caffe实战(十):win-caffe训练和测试cifar10数据集
CNN训练Cifar-10技巧这篇文章中介绍了关于cifar10训练的一些常用技巧,可以提高训练精度以及速度,指的借鉴:
- 使用ReLu激活函数:ReLu为网络引入了大量的稀疏性,加速了复杂特征解离。非饱和的宽广映射空间,加速了特征学习;
- 卷积层w初始化逐层增大标准差:Alex选择了高斯分布生成零均值、小标准差的随机值作为初始化W,并且逐层加大标准差,使得W有弹性。(0.0001-0.01-0.01-0.1-0.1);
- 学习速率:Caffe和Alex给的Model基础都是0.001(W)/0.002(b);
- 数据集作均值归一化:Alex 和 Caffe中的初始化参数都是基于均值归一化的,如果不做归一化,会因为输入大了一半,导致训练失败;
- 池化中采用重叠结构:Alex在paper中还提到,重叠Pooling一定程度上减轻了过拟合;不重叠忽视了邻近像素的对特征的影响,会造成网络精度下降;
- 恰当使用均采样:重叠结构在提高精度的同时,可能引入噪声。而Alex则在Conv2、Conv3全使用了Avg Pooling;
- 最佳效果:Max+Avg+Avg;
- 基本没有用的LRN层。

获取cifar-10数据集
Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类(姊妹数据集Cifar-100达到100类,ILSVRC比赛则是1000类)。
cifar-10数据集和cifar-100数据集的官方网址都是:https://www.cs.toronto.edu/~kriz/cifar.html
cifar-10有三种版本
CIFAR-10 python version 163 MB c58f30108f718f92721af3b95e74349a
CIFAR-10 Matlab version 175 MB 70270af85842c9e89bb428ec9976c926
CIFAR-10 binary version (suitable for C programs) 162 MB c32a1d4ab5d03f1284b67883e8d8753
自己使用的是二进制版本,下载后解压即可;

batches.meta.txt:标签内容
data_batch_1.....5.bin为训练集,每个文件10000张图像;
test_batch.bin为测试集;
转换为lmdb或leveldb格式
caffe使用lmdb或leveldb数据格式作为DataLayer的输入形式,利用自带的转换数据格式工具进行转换:
convert_cifar10.cmd文件内容
rem 将cifar-10-binary格式转换为lmdb rem 参数(1)cifar-10-binary路径,包含data_batch_1(1-5).bin 5个训练数据(共50000),test_batch.bin测试数据(10000); rem 参数(2)输出lmdb格式路径 rem 参数(3)数据格式 lmdb或leveldb rem ..\\..\\Build\\x64\\Release\\convert_cifar_data.exe ..\\..\\data\\cifar10\\cifar-10-binary ..\\..\\data\\cifar10 lmdb ..\\..\\Build\\x64\\Release\\convert_cifar_data.exe ..\\..\\data\\cifar10\\cifar-10-binary ..\\..\\data\\cifar10 leveldb
计算训练数据集的均值
rem 计算均值 rem 参数(1)训练数据路径;--backend=lmdb 指的是数据格式 rem 参数(2)输出均值文件路径和名称 rem ..\\..\\Build\\x64\\Release\\compute_image_mean.exe --backend=lmdb ..\\..\\data\\cifar10\\cifar10_train_lmdb ..\\..\\data\\cifar10\\mean.binaryproto ..\\..\\Build\\x64\\Release\\compute_image_mean.exe --backend=leveldb ..\\..\\data\\cifar10\\cifar10_train_leveldb ..\\..\\data\\cifar10\\mean.binaryproto.leveldb
修改求解器配置文件以及网络模型文件
求解器文件主要修改选择CPU还是GPU模式,以及网络模型文件和快照输出文件的路径是否正确;(注意当前工作目录)
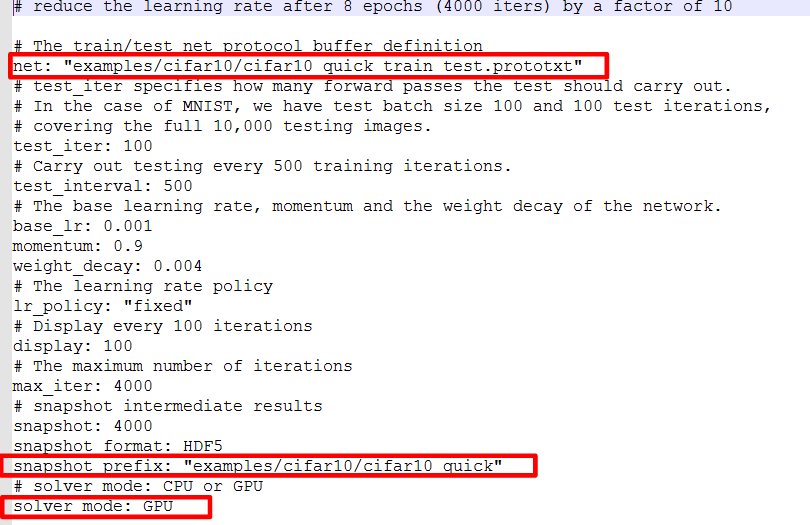
网络模型文件中主要修改输入层的数据来源路径以及数据格式;
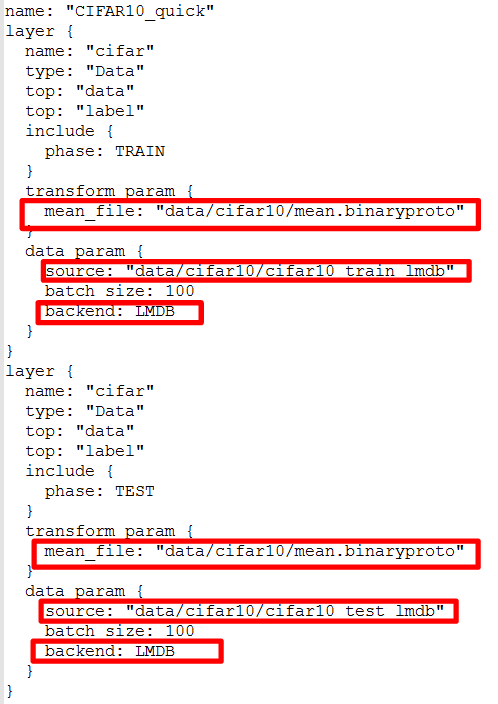
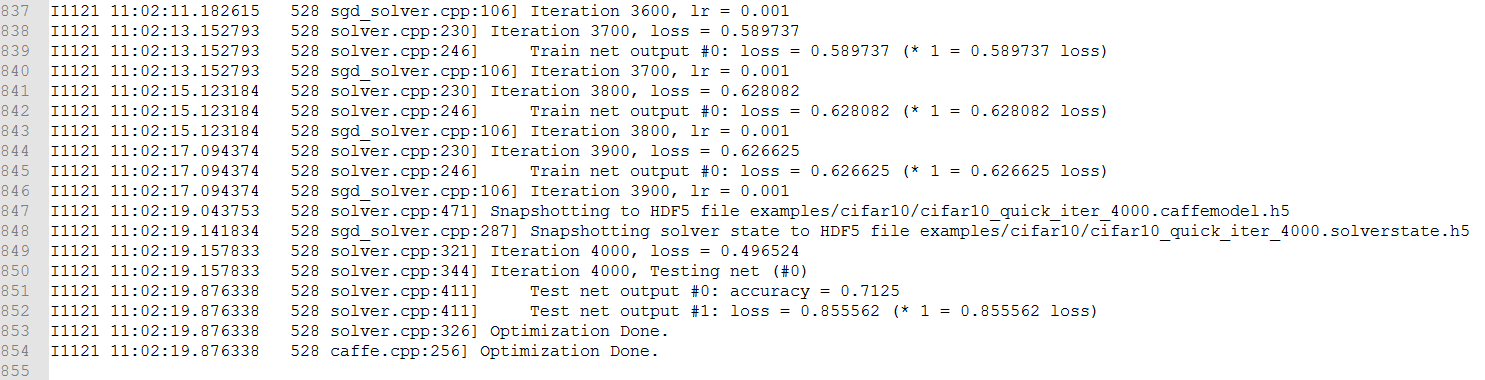
训练cifar10
caffe自带的例子中提供了几种网络模型以及训练参数可供参考。以训练cifar10_quick_train_test.prototxt网络模型为例:
rem 切换到caffe_root目录 cd E: cd E:\Learning\caffe\Microsoft\caffe rem 训练cifar10_quick_solver.prototxt Build\\x64\\Release\\caffe.exe train --solver=examples\\cifar10\\cifar10_quick_solver.prototxt > examples\\cifar10\\cifar10_quick_train.log 2>&1
训练完成后输出两个文件:xxx.caffemodel.h5为网络权值参数文件;xxx.solverstate.h5为网络模型状态文件,用恢复网络状态或者在此基础上进一步训练。

备注:这里采用数据流重导向的操作,输出到log文件中,便于查看训练过程的log日志信息。
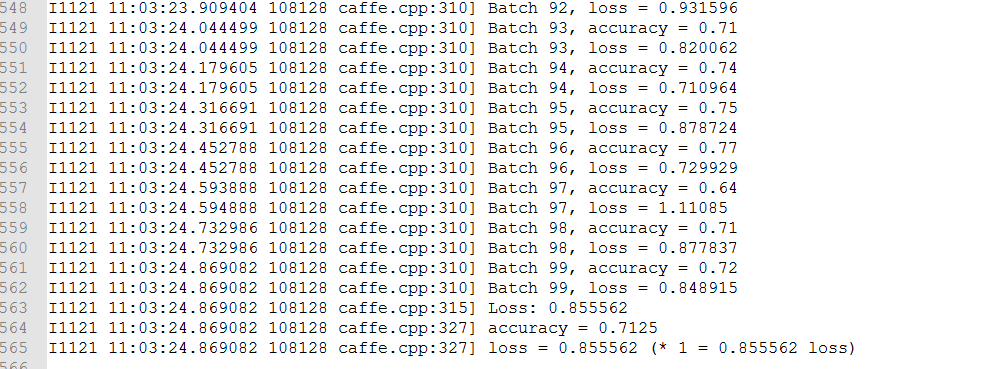
测试cifar10验证集
rem 切换到caffe_root目录 cd E: cd E:\Learning\caffe\Microsoft\caffe rem 测试cifar10_quick_solver.prototxt Build\\x64\\Release\\caffe.exe test -model examples\\cifar10\\cifar10_quick_train_test.prototxt -weights examples\\cifar10\\cifar10_quick_iter_4000.caffemodel.h5 -iterations 100 -gpu 0 > examples\\cifar10\\cifar10_quick_test.log 2>&1
利用训练好的模型(caffemodel)测试自己的图片
caffe自带分类器工具-classification,用于测试输入单张图片的分类结果。 rem 利用classification.exe对单图像进行分类测试 rem 参数(1)网络模型定义文件 rem 参数(2)权值文件 rem 参数(3)均值文件 rem 参数(4)同义词词集文件 rem 参数(5)输入图像 cd E: cd E:\Learning\caffe\Microsoft\caffe rem 测试cifar10_quick_solver.prototxt参数训练结果 Build\\x64\\Release\\classification.exe examples\\cifar10\\cifar10_quick.prototxt examples\\cifar10\\cifar10_quick_iter_4000.caffemodel.h5 data\\cifar10\\mean.binaryproto data\\cifar10\\cifar-10-binary\\synset_words.txt examples\\images\\cat.jpg
特别注意:synset_words.txt中最后一行不应有空格或回车,否则读取的label个数为11,与输出层个数不一致,会报错。
但是分类结果不正确

参考好多网上的测试过程以及结果,发现他们使用caffe自带的cat图像时,分类结果是正确的,而自己测试了很多模型,包括训练时的loss和accuracy基本上和网上的一致,但是为何测试另外一种图像时会不一致??(一直怀疑是自己注释caffe源文件时,修改了某些内容,导致有问题??)
从训练的结果来看,accuracy只有70%左右的正确率。自己又拿测试数据集中解析出的32*32图像进行识别测试,发现有些类别识别的准确率比较高,如airplane;有些识别的准确率比较低,如cat ,dog等。而且跟图像的光线明暗变化,背景等都有很大的关系。从这里可以看出,对原始图像的预处理确实很重要,否则严重影响模型识别的准确率。
参考:

