【redis】redis-windows安装+配置介绍
1.下载windows版本redis
官方下载地址:http://redis.io/download,不过官方没有64位的Windows下的可执行程序,目前有个开源的托管在github上, 地址:https://github.com/ServiceStack/redis-windows
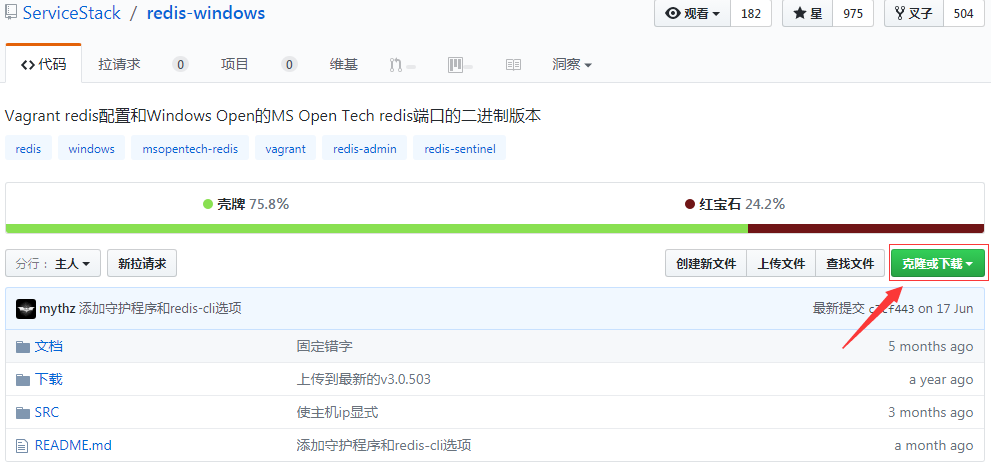
2.解压

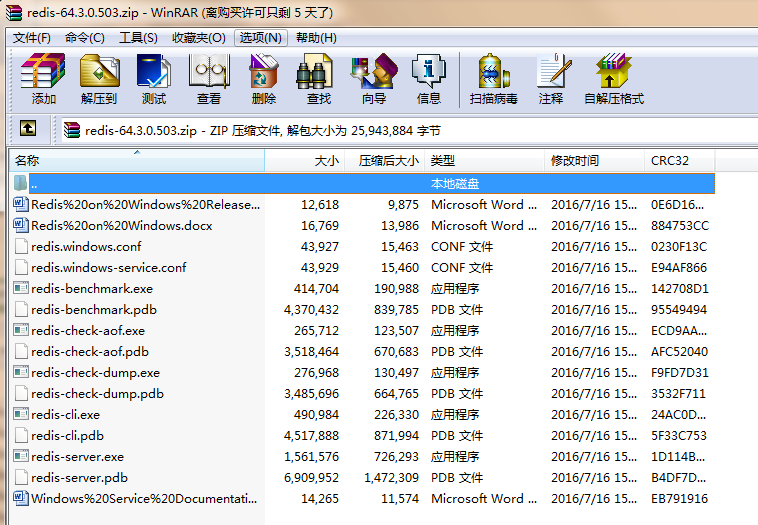
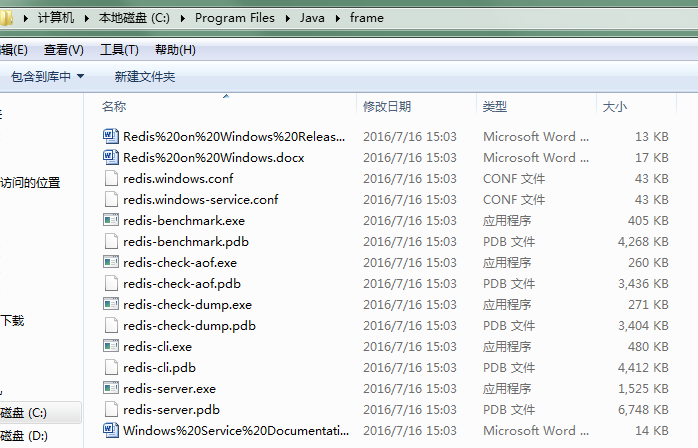
3.文件介绍
| 文件名 | 简要 |
| redis-benchmark.exe | 基准测试 redis-benchmark为redis性能测试工具 |
| redis-check-aof.exe | aof AOF是AppendOnly File的缩写,是Redis系统提供了一种记录Redis操作的持久化方案 |
| redischeck-dump.exe | dump redis的备份和还原,借助了第三方的工具,redis-dump |
| redis-cli.exe | 客户端 |
| redis-server.exe | 服务器 |
| redis.windows.conf | 配置文件 |
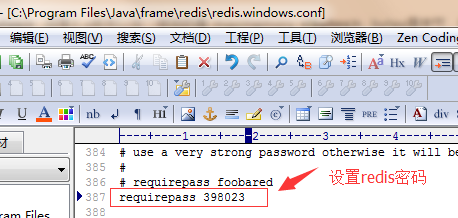
4.redis.windows.conf文件中设置redis密码
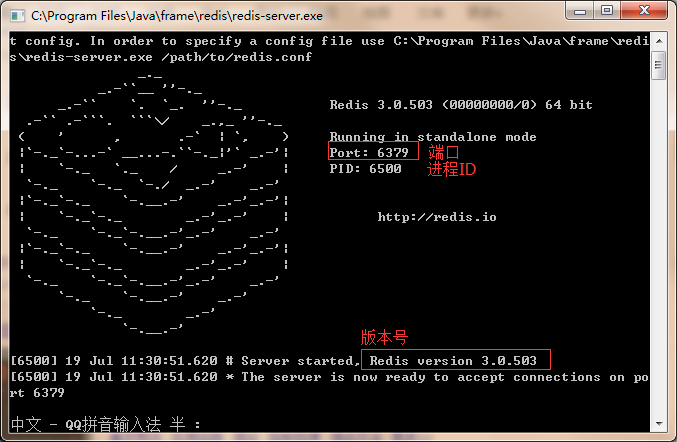
5.点击redis-server.exe 启动redis服务器端
如下,启动成功
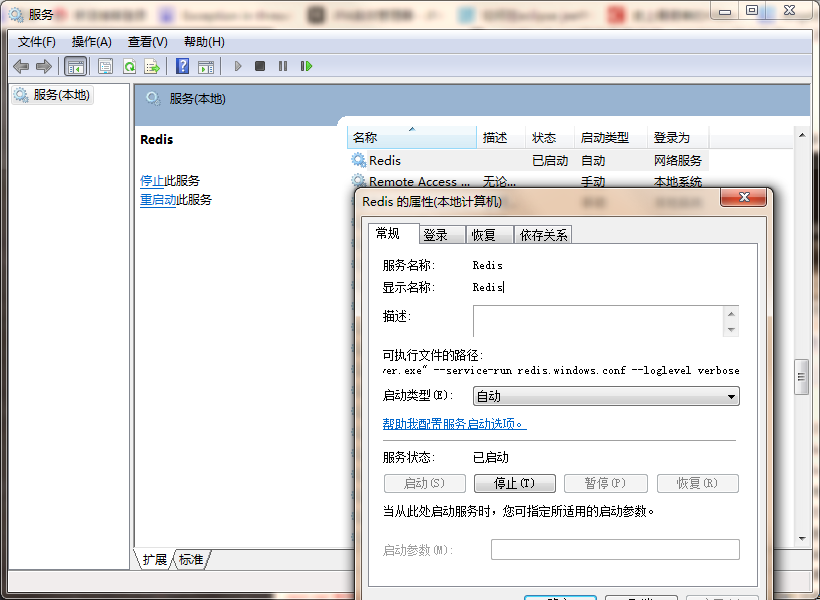
6.将redis注册为系统服务
cmd进入dos窗口
首先cd进入到redis目录下,然后注册为系统服务
命令行:
redis-server.exe --service-install redis.windows.conf --loglevel verbose redis-server --service-start

7.卸载服务, 可以保存为 uninstall-service.bat 文件
redis-server --service-stop redis-server --service-uninstall
-------------------------------------------------------------------------------------------------------------至此,redis-windows版本安装完成---------------------------------------------------------------------------------------------------
1.redis.windows.conf各项配置参数介绍


1 # 默认情况下,redis不是在后台模式运行的,如果需要在后台进程运行,把该项的值更改为yes,默认为no 2 3 daemonize:是否以后台daemon方式运行 4 5 # 如redis服务以后台进程运行的时候,Redis默认会把pid写入/run/redis.pid文件组,你可以配置到其他文件路径。 6 7 # 当运行多个redis服务时,需要指定不同的pid文件和端口 8 9 pidfile:pid文件位置 10 11 # 指定redis监听端口,默认为6379 12 13 # 如果端口设置为0,Redis就不会监听TCP套接字。 14 15 port:监听的端口号 16 17 # 指定redis只接收来自于该IP地址的请求,如果不进行设置,默认将处理所有请求, 18 19 # 在生产环境中最好设置该项 20 21 bind 127.0.0.1 22 23 # 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接 24 25 # 默认值:0代表禁用,永不关闭 26 27 timeout:请求超时时间 28 29 # 指定用来监听连接的unxi套接字的路径。这个没有默认值,所以如果不指定的话,Redis就不会通过unix套接字来监听。 30 31 # unixsocket /tmp/redis.sock 32 33 # unixsocketperm 755 34 35 # 指定日志记录级别 36 37 # Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose 38 39 # debug 记录很多信息,用于开发和测试 40 41 # varbose 很多精简的有用信息,不像debug会记录那么多 42 43 # notice 普通的verbose,常用于生产环境 44 45 # warning 只有非常重要或者严重的信息会记录到日志 46 47 loglevel:log信息级别 48 49 # 配置log文件名称和全路径地址 50 51 # 默认值为stdout,使用“标准输出”,默认后台模式会输出到/dev/null 52 53 logfile:log文件位置 54 55 # 可用数据库数,默认值为16,默认数据库存储在DB 0号ID库中,无特殊需求,建议仅设置一个数据库 databases 1 56 57 # 查询数据库使用 SELECT <dbid> 58 59 # dbid介于 0 到 'databases'-1 之间 60 61 databases:开启数据库的数量 62 63 save * *:保存快照的频率,第一个*表示多长时间,第三个*表示执行多少次写操作。在一定时间内执行一定数量的写操作时,自动保存快照。可设置多个条件。 64 65 rdbcompression:是否使用压缩 66 67 dbfilename:数据快照文件名(只是文件名,不包括目录) 68 69 dir:数据快照的保存目录(这个是目录) 70 71 appendonly:是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。 72 73 appendfsync:appendonlylog如何同步到磁盘(三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步) 74 75 ########## REPLICATION 同步 ########## 76 77 # 78 79 # 主从同步。通过 slaveof 配置来实现Redis实例的备份。 80 81 # 注意,这里是本地从远端复制数据。也就是说,本地可以有不同的数据库文件、绑定不同的IP、监听不同的端口。 82 83 # 当本机为从服务时,设置主服务的IP及端口,在Redis启动时,它会自动从主服务进行数据同步 84 85 # slaveof <masterip> <masterport> 86 87 # 如果主服务master设置了密码(通过下面的 "requirepass" 选项来配置),slave服务连接master的密码,那么slave在开始同步之前必须进行身份验证,否则它的同步请求会被拒绝。 88 89 #当本机为从服务时,设置主服务的连接密码 90 91 # masterauth <master-password> 92 93 # 当一个slave失去和master的连接,或者同步正在进行中,slave的行为有两种可能: 94 95 # 1) 如果 slave-serve-stale-data 设置为 "yes" (默认值),slave会继续响应客户端请求,可能是正常数据,也可能是还没获得值的空数据。 96 97 # 2) 如果 slave-serve-stale-data 设置为 "no",slave会回复"正在从master同步(SYNC with master in progress)"来处理各种请求,除了 INFO 和 SLAVEOF 命令。 98 99 slave-serve-stale-data yes 100 101 # slave根据指定的时间间隔向服务器发送ping请求。 102 103 # 时间间隔可以通过 repl_ping_slave_period 来设置。 104 105 # 默认10秒 106 107 # repl-ping-slave-period 10 108 109 # 下面的选项设置了大块数据I/O、向master请求数据和ping响应的过期时间。 110 111 # 默认值60秒。 112 113 # 一个很重要的事情是:确保这个值比 repl-ping-slave-period 大,否则master和slave之间的传输过期时间比预想的要短。 114 115 # repl-timeout 60 116 117 ########## SECURITY 安全 ########## 118 119 # 要求客户端在处理任何命令时都要验证身份和设置密码。 120 121 # 如果你不相信请求者,这个功能很有用。 122 123 # 为了向后兼容的话,这段应该注释掉。而且大多数人不需要身份验证(例如:它们运行在自己的服务器上。) 124 125 # 警告:外部使用者可以每秒尝试150k的密码来试图破解密码,这意味着你需要一个高强度的密码,否则破解太容易了。 126 127 # 设置连接密码 128 129 # requirepass foobared 130 131 # 命令重命名,可设置多个 132 133 # 在共享环境下,可以为危险命令改变名字。比如,你可以为 CONFIG 改个其他不太容易猜到的名字,这样你自己仍然可以使用,而别人却没法知道它。 134 135 # 例如: 136 137 # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 138 139 # rename-command info info_biran 140 141 # rename-command set set_biran 142 143 # 甚至也可以通过给命令赋值一个空字符串来完全禁用这条命令: 144 145 # rename-command CONFIG "" 146 147 ########## LIMITS 限制 ########## 148 149 # 设置最大同时连接客户端数量。 150 151 # 默认没有限制,这个关系到Redis进程能够打开的文件描述符数量。 152 153 # 特殊值"0"表示没有限制。 154 155 # 一旦达到这个限制,Redis会关闭所有新连接并发送错误"达到最大用户数上限(max number of clients reached)" 156 157 # maxclients 128 158 159 # 不要用比设置的上限更多的内存。一旦内存使用达到上限,Redis会根据选定的回收策略(参见:maxmemmory-policy:内存策略设置)删除key。 160 161 # 如果因为删除策略问题Redis无法删除key,或者策略设置为 "noeviction",Redis会回复需要更多内存的错误信息给命令。 162 163 # 例如,SET,LPUSH等等。但是会继续合理响应只读命令,比如:GET。 164 165 # 在使用Redis作为LRU缓存,或者为实例设置了硬性内存限制的时候(使用 "noeviction" 策略)的时候,这个选项还是满有用的。 166 167 # 警告:当一堆slave连上达到内存上限的实例的时候,响应slave需要的输出缓存所需内存不计算在使用内存当中。 168 169 # 这样当请求一个删除掉的key的时候就不会触发网络问题/重新同步的事件,然后slave就会收到一堆删除指令,直到数据库空了为止。 170 171 # 简而言之,如果你有slave连上一个master的话,那建议你把master内存限制设小点儿,确保有足够的系统内存用作输出缓存。 172 173 # (如果策略设置为"noeviction"的话就不无所谓了) 174 175 # 设置最大内存,达到最大内存设置后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理后,任到达最大内存设置,将无法再进行写入操作。 176 177 # maxmemory 256000000分配256M内存 178 179 # maxmemory <bytes> 180 181 # 内存策略:如果达到内存限制了,Redis如何删除key。你可以在下面五个策略里面选: 182 183 # 184 185 # volatile-lru -> 根据LRU算法生成的过期时间来删除。 186 187 # allkeys-lru -> 根据LRU算法删除任何key。 188 189 # volatile-random -> 根据过期设置来随机删除key。 190 191 # allkeys->random -> 无差别随机删。 192 193 # volatile-ttl -> 根据最近过期时间来删除(辅以TTL) 194 195 # noeviction -> 谁也不删,直接在写操作时返回错误。 196 197 # 198 199 # 注意:对所有策略来说,如果Redis找不到合适的可以删除的key都会在写操作时返回一个错误。 200 201 # 202 203 # 这里涉及的命令:set setnx setex append 204 205 # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd 206 207 # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby 208 209 # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby 210 211 # getset mset msetnx exec sort 212 213 # 214 215 # 默认值如下: 216 217 # maxmemory-policy volatile-lru 218 219 # LRU和最小TTL算法的实现都不是很精确,但是很接近(为了省内存),所以你可以用样例做测试。 220 221 # 例如:默认Redis会检查三个key然后取最旧的那个,你可以通过下面的配置项来设置样本的个数。 222 223 # maxmemory-samples 3 224 225 ########## APPEND ONLY MODE 纯累加模式 ########## 226 227 # 默认情况下,Redis是异步的把数据导出到磁盘上。因为redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中,这种情况下,当Redis宕机的时候,最新的数据就丢了。 228 229 # 如果不希望丢掉任何一条数据的话就该用纯累加模式:一旦开启这个模式,Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件。 230 231 # 每次启动时Redis都会把这个文件的数据读入内存里。 232 233 # 234 235 # 注意,异步导出的数据库文件和纯累加文件可以并存(此时需要把上面所有"save"设置都注释掉,关掉导出机制)。 236 237 # 如果纯累加模式开启了,那么Redis会在启动时载入日志文件而忽略导出的 dump.rdb 文件。 238 239 # 240 241 # 重要:查看 BGREWRITEAOF 来了解当累加日志文件太大了之后,怎么在后台重新处理这个日志文件。 242 243 # 设置:yes为纯累加模式 244 245 appendonly no 246 247 # 设置纯累加文件名字及保存路径,默认:"appendonly.aof" 248 249 # appendfilename appendonly.aof 250 251 # fsync() 请求操作系统马上把数据写到磁盘上,不要再等了。 252 253 # 有些操作系统会真的把数据马上刷到磁盘上;有些则要磨蹭一下,但是会尽快去做。 254 255 # Redis支持三种不同的模式: 256 257 # 258 259 # no:不要立刻刷,只有在操作系统需要刷的时候再刷。比较快。 260 261 # always:每次写操作都立刻写入到aof文件。慢,但是最安全。 262 263 # everysec:每秒写一次。折衷方案。 264 265 # 默认的 "everysec" 通常来说能在速度和数据安全性之间取得比较好的平衡。 266 267 # 如果你真的理解了这个意味着什么,那么设置"no"可以获得更好的性能表现(如果丢数据的话,则只能拿到一个不是很新的快照); 268 269 # 或者相反的,你选择 "always" 来牺牲速度确保数据安全、完整。 270 271 # 272 273 # 如果不确定这些模式的使用,建议使用 "everysec" 274 275 # 276 277 # appendfsync always 278 279 appendfsync everysec 280 281 # appendfsync no 282 283 # 如果AOF的同步策略设置成 "always" 或者 "everysec",那么后台的存储进程(后台存储或写入AOF日志)会产生很多磁盘I/O开销。 284 285 # 某些Linux的配置下会使Redis因为 fsync() 而阻塞很久。 286 287 # 注意,目前对这个情况还没有完美修正,甚至不同线程的 fsync() 会阻塞我们的 write(2) 请求。 288 289 # 290 291 # 为了缓解这个问题,可以用下面这个选项。它可以在 BGSAVE 或 BGREWRITEAOF 处理时阻止 fsync()。 292 293 # 294 295 # 这就意味着如果有子进程在进行保存操作,那么Redis就处于"不可同步"的状态。 296 297 # 这实际上是说,在最差的情况下可能会丢掉30秒钟的日志数据。(默认Linux设定) 298 299 # 300 301 # 如果你有延迟的问题那就把这个设为 "yes",否则就保持 "no",这是保存持久数据的最安全的方式。 302 303 no-appendfsync-on-rewrite no 304 305 # 自动重写AOF文件 306 307 # 如果AOF日志文件大到指定百分比,Redis能够通过 BGREWRITEAOF 自动重写AOF日志文件。 308 309 # 310 311 # 工作原理:Redis记住上次重写时AOF日志的大小(或者重启后没有写操作的话,那就直接用此时的AOF文件), 312 313 # 基准尺寸和当前尺寸做比较。如果当前尺寸超过指定比例,就会触发重写操作。 314 315 # 316 317 # 你还需要指定被重写日志的最小尺寸,这样避免了达到约定百分比但尺寸仍然很小的情况还要重写。 318 319 # 320 321 # 指定百分比为0会禁用AOF自动重写特性。 322 323 auto-aof-rewrite-percentage 100 324 325 auto-aof-rewrite-min-size 64mb 326 327 ########## SLOW LOG 慢查询日志 ########## 328 329 # Redis慢查询日志可以记录超过指定时间的查询。运行时间不包括各种I/O时间。 330 331 # 例如:连接客户端,发送响应数据等。只计算命令运行的实际时间(这是唯一一种命令运行线程阻塞而无法同时为其他请求服务的场景) 332 333 # 334 335 # 你可以为慢查询日志配置两个参数:一个是超标时间,单位为微妙,记录超过个时间的命令。 336 337 # 另一个是慢查询日志长度。当一个新的命令被写进日志的时候,最老的那个记录会被删掉。 338 339 # 340 341 # 下面的时间单位是微秒,所以1000000就是1秒。注意,负数时间会禁用慢查询日志,而0则会强制记录所有命令。 342 343 slowlog-log-slower-than 10000 344 345 # 这个长度没有限制。只要有足够的内存就行。你可以通过 SLOWLOG RESET 来释放内存。 346 347 slowlog-max-len 128 348 349 ########## VIRTUAL MEMORY 虚拟内存 ########## 350 351 ### 警告!虚拟内存在Redis 2.4是反对的,因性能问题,2.4版本 VM机制彻底废弃,不建议使用此配置!!!!!!!!!!! 352 353 # 虚拟内存可以使Redis在内存不够的情况下仍然可以将所有数据序列保存在内存里。 354 355 # 为了做到这一点,高频key会调到内存里,而低频key会转到交换文件里,就像操作系统使用内存页一样。 356 357 # 要使用虚拟内存,只要把 "vm-enabled" 设置为 "yes",并根据需要设置下面三个虚拟内存参数就可以了。 358 359 vm-enabled no 360 361 # 这是交换文件的路径。估计你猜到了,交换文件不能在多个Redis实例之间共享,所以确保每个Redis实例使用一个独立交换文件。 362 363 # 最好的保存交换文件(被随机访问)的介质是固态硬盘(SSD)。 364 365 # *** 警告 *** 如果你使用共享主机,那么默认的交换文件放到 /tmp 下是不安全的。 366 367 # 创建一个Redis用户可写的目录,并配置Redis在这里创建交换文件。 368 369 vm-swap-file /tmp/redis.swap 370 371 # "vm-max-memory" 配置虚拟内存可用的最大内存容量。 372 373 # 如果交换文件还有空间的话,所有超标部分都会放到交换文件里。 374 375 # "vm-max-memory" 设置为0表示系统会用掉所有可用内存,建议设置为剩余内存的60%-80%。 376 377 # 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0。 378 379 vm-max-memory 0 380 381 # Redis交换文件是分成多个数据页的。 382 383 # 一个可存储对象可以被保存在多个连续页里,但是一个数据页无法被多个对象共享。 384 385 # 所以,如果你的数据页太大,那么小对象就会浪费掉很多空间。 386 387 # 如果数据页太小,那用于存储的交换空间就会更少(假定你设置相同的数据页数量) 388 389 # 如果你使用很多小对象,建议分页尺寸为64或32个字节。 390 391 # 如果你使用很多大对象,那就用大一些的尺寸。 392 393 # 如果不确定,那就用默认值 :) 394 395 vm-page-size 32 396 397 # 交换文件里数据页总数。 398 399 # 根据内存中分页表(已用/未用的数据页分布情况),磁盘上每8个数据页会消耗内存里1个字节。 400 401 # 交换区容量 = vm-page-size * vm-pages 402 403 # 根据默认的32字节的数据页尺寸和134217728的数据页数来算,Redis的数据页文件会占4GB,而内存里的分页表会消耗16MB内存。 404 405 # 为你的应验程序设置最小且够用的数字比较好,下面这个默认值在大多数情况下都是偏大的。 406 407 vm-pages 134217728 408 409 # 同时可运行的虚拟内存I/O线程数,即访问swap文件的线程数。 410 411 # 这些线程可以完成从交换文件进行数据读写的操作,也可以处理数据在内存与磁盘间的交互和编码/解码处理。 412 413 # 多一些线程可以一定程度上提高处理效率,虽然I/O操作本身依赖于物理设备的限制,不会因为更多的线程而提高单次读写操作的效率。 414 415 # 特殊值0会关闭线程级I/O,并会开启阻塞虚拟内存机制。 416 417 # 设置最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的.可能会造成比较长时间的延迟,但是对数据完整性有很好的保证. 418 419 vm-max-threads 4 420 421 ########## ADVANCED CONFIG 高级配置 ########## 422 423 # 当有大量数据时,适合用哈希编码(这会需要更多的内存),元素数量上限不能超过给定限制。 424 425 # Redis Hash是value内部为一个HashMap,如果该Map的成员数比较少,则会采用类似一维线性的紧凑格式来存储该Map, 即省去了大量指针的内存开销,如下2个条件任意一个条件超过设置值都会转换成真正的HashMap, 426 427 # 当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值自动转成真正的HashMap。 428 429 hash-max-zipmap-entries 512 430 431 # 当 value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间。 432 433 hash-max-zipmap-value 64 434 435 # 与hash-max-zipmap-entries哈希相类似,数据元素较少的情况下,可以用另一种方式来编码从而节省大量空间。 436 437 # list数据类型多少节点以下会采用去指针的紧凑存储格式 438 439 list-max-ziplist-entries 512 440 441 # list数据类型节点值大小小于多少字节会采用紧凑存储格式 442 443 list-max-ziplist-value 64 444 445 # 还有这样一种特殊编码的情况:数据全是64位无符号整型数字构成的字符串。 446 447 # 下面这个配置项就是用来限制这种情况下使用这种编码的最大上限的。 448 449 set-max-intset-entries 512 450 451 # 与第一、第二种情况相似,有序序列也可以用一种特别的编码方式来处理,可节省大量空间。 452 453 # 这种编码只适合长度和元素都符合下面限制的有序序列: 454 455 zset-max-ziplist-entries 128 456 457 zset-max-ziplist-value 64 458 459 # 哈希刷新,每100个CPU毫秒会拿出1个毫秒来刷新Redis的主哈希表(顶级键值映射表)。 460 461 # redis所用的哈希表实现(见dict.c)采用延迟哈希刷新机制:你对一个哈希表操作越多,哈希刷新操作就越频繁; 462 463 # 反之,如果服务器非常不活跃那么也就是用点内存保存哈希表而已。 464 465 # 默认是每秒钟进行10次哈希表刷新,用来刷新字典,然后尽快释放内存。 466 467 # 建议: 468 469 # 如果你对延迟比较在意的话就用 "activerehashing no",每个请求延迟2毫秒不太好嘛。 470 471 # 如果你不太在意延迟而希望尽快释放内存的话就设置 "activerehashing yes"。 472 473 activerehashing yes 474 475 ########## INCLUDES 包含 ########## 476 477 # 包含一个或多个其他配置文件。 478 479 # 这在你有标准配置模板但是每个redis服务器又需要个性设置的时候很有用。 480 481 # 包含文件特性允许你引人其他配置文件,所以好好利用吧。 482 483 # include /path/to/local.conf 484 485 # include /path/to/other.conf
修改配置后,如果配置文件涉及到中文内容记得将文件存为UTF-8编码。
2.redis-cli.exe 客户端使用
点击redis-cli.exe
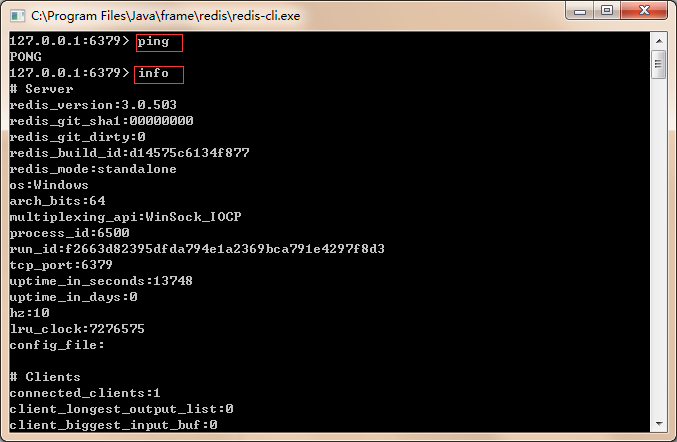
测试服务器启动连接情况
127.0.0.1:6379> ping PONG
查看服务器级别信息(测试服务器)
127.0.0.1:6379> info # Server redis_version:3.0.503 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:d14575c6134f877 redis_mode:standalone os:Windows arch_bits:64 multiplexing_api:WinSock_IOCP process_id:6500 run_id:f2663d82395dfda794e1a2369bca791e4297f8d3 tcp_port:6379 uptime_in_seconds:13748 uptime_in_days:0 hz:10 lru_clock:7276575 config_file: # Clients connected_clients:1 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 # Memory used_memory:692888 used_memory_human:676.65K used_memory_rss:655240 used_memory_peak:692888 used_memory_peak_human:676.65K used_memory_lua:36864 mem_fragmentation_ratio:0.95 mem_allocator:jemalloc-3.6.0 # Persistence loading:0 rdb_changes_since_last_save:0 rdb_bgsave_in_progress:0 rdb_last_save_time:1500435051 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:-1 rdb_current_bgsave_time_sec:-1 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok # Stats total_connections_received:1 total_commands_processed:1 instantaneous_ops_per_sec:0 total_net_input_bytes:28 total_net_output_bytes:7 instantaneous_input_kbps:0.00 instantaneous_output_kbps:0.00 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 evicted_keys:0 keyspace_hits:0 keyspace_misses:0 pubsub_channels:0 pubsub_patterns:0 latest_fork_usec:0 migrate_cached_sockets:0 # Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # CPU used_cpu_sys:0.02 used_cpu_user:0.02 used_cpu_sys_children:0.00 used_cpu_user_children:0.00 # Cluster cluster_enabled:0 # Keyspace
3.redis-benchmark 性能测试工具
默认双击打开是按照默认的测试参数进行测试,而且它自己测试跑完之后,就会自动关闭DOS窗口了。
输入如下命令后会看到如下信息,表明同时并发10个连接,总共100次操作。通俗易懂的说就是10个用户同时操作,总共每人操作10次的意思
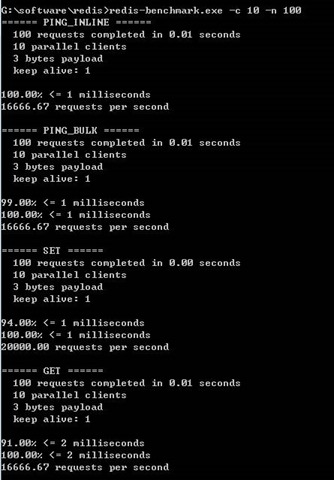
100 requests completed in 0.01 seconds (100个请求完成于0.01秒) 10 parallel clients (10个客户端并发) 3 bytes payload (每次写入3个字节) keep alive: 1 (保存一个链接数) 100.00% <= 1 milliseconds (100%的操作小于1秒完成) 16666.67 requests per second (每秒完成16666.67次查询)
命令参数说明
redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>] -h <hostname> 主机名 (默认 127.0.0.1) -p <port> 主机端口 (默认 6379) -s <socket> 主机套接字 (覆盖主机和端口) -c <clients> 并发连接的数量 (默认 50) -n <requests> 请求总数 (默认 10000) -d <size> SET/GET数据的字节大小(默认 2) -k <boolean> 1=keep alive 0=reconnect (默认 1) -r <keyspacelen> SET/GET/INCR使用随机产生的key, SADD使用随机值使用这个选项 get/set keys时会用mykey_rand:000000012456代替常量key, <keyspacelen>参数决定了随机数产生的最大值,比如,设置参数为10,那么产生的随机数范围是rand:000000000000 -rand:000000000009 -P <numreq> Pipeline请求的数量. 默认 1 (不使用pipeline). -q 展示query/sec值 --csv 以CSV格式输出 -l 本地循环. 一直运行测试 -t <tests> 在运行逗号分割列表的测试. 测试的名字与产生输出的名字一样。 -I 空闲模式. 打开 N 个空闲连接,然后等待.
运行示例
对指定服务器、端口进行20个同时并发操作,总共操作100000次 redis-benchmark -h 192.168.1.136 -p 6379 -n 100000 -c 20 测试set写入操作1000000次,随机数范围在100000000 redis-benchmark -t set -n 1000000 -r 100000000 测试ping、set、get操作100000次,结果输出用csv格式 redis-benchmark -t ping,set,get -n 100000 –-csv redis-benchmark -r 10000 -n 10000 lpush mylist ele:rand:000000000000
4.redis-check-aof 基本用法
检查本地日志信息,加--fix参数为修复log文件
redis-check-aof.exe log.aof
5.redis-check-dump 检查数据库文件
redis-check-dump.exe dump.rdb 会输出该文件大小、使用情况。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参考:http://www.cnblogs.com/hoojo/p/4466024.html

