
第7章 SAX解析XML
通过上一章的学习,我们知道基于DOM的解析器的核心是在内存中建立和XML文档相对应的树性树状结构,XML文件的标记、标记中的文本数据、实体等都会和内存中树状结构的某个节点相对应。使用DOM解析器的好处是,可以方便的操作内存中的树的节点来处理XML文档,获取自己所需要的数据。但DOM解析的不足之处在于,如果XML文件较大,或者只需要解析XML文档一部分数据,此时就会占有大量的内存空间。和DOM解析不同的是,SAX解析器不在内存中建立和XML文件相对应的树状结构数据,SAX解析器的核心是事件处理机制,具有占有内存少、效率高等特点。
本章知识要点:
掌握SAX概念和特点
熟练掌握SAX的工作机制
了解SAX常用接口
熟练掌握SAX解析XML文档的步骤
熟练掌握解析器和事件处理器的创建和使用
熟练掌握SAX处理各种应用
掌握SAX和DOM共同构建XML文档
7.1 SAX概述
高效地解析XML数据非常重要,尤其是对于那些要处理大量数据的应用程序,这种技术尤为重要。不正确的解析会导致过度的内存消耗和过长的处理时间,从而有损于可伸缩性。SAX就是其中一种,并以快速高效解析大量XML文档而著称。
7.1.1 SAX介绍
用于读取和操作XML文件的标准是文档对象模型(Document Object Model,DOM)。遗憾的是,DOM方法涉及读取整个文件并将该文件存储在一个树结构中,而这样可能是低效的、缓慢的,并且很消耗资源。一种替代技术就是Simple API for XML,或称为SAX,翻译过来的意思是简易应用程序编写接口。SAX允许在读取文档时处理它,从而不必等待整个文档被存储之后才采取操作。
7.1.2 工作机制
SAX在概念上与DOM完全不同。首先,不同于DOM的文档驱动,它是事件驱动的,也就是说,它并不需要读入整个文档,而文档的读入过程也就是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。我们也可以把它称为授权事件模型。
SAX解析器装载XML文件时,它遍历XML文档并在其主机应用程序中产生事件(经由回调函数、指派函数或者任何可调用平台完成这一功能)表示这一过程。这样,编写SAX应用程序就如同采用最现代的工具箱编写GUI事件程序。
7.1.3 常用接口
SAX是一个接口,一套API,在SAX接口里声明了处理XML文档的时候需要的方法。利用SAX编写的程序,可以快速的对数据进行操作。SAX接口中常用的接口如下所示:
Attributes接口
ContentHandler接口
DTDHandler接口
EntityResolver接口
XMLReader接口
SAX错误处理程序的基本接口
7.1.4 SAX解析器创建及使用
SAX接口提供了解析XML文件的API,基于SAX接口的解析器这里我们称作SAX解析器。和DOM解析不同的是,SAX解析器不在内存中建立和XML文件相对应的树状结构数据。SAX解析器的核心是事件处理机制。
7.2 SAX应用
SAX是一种基于事件驱动的API。利用SAX解析XML文档,涉及到两个部分:解析器和事件处理器。解析器负责读取XML文档,并向事件处理器发送事件,如元素开始和元素结束。事件处理器则负责对事件做出响应,对传递的XML数据进行处理。
7.2.1 处理文件开始与结束
当SAX解析器解析XML文档时,解析到不同的标记会触发不同的事件。当SAX解析器开始解析XML文件时,就会报告“文件开始”事件给事件处理器,此时事件处理器会调用方法startDocument()方法,然后再陆续处理并报告其他的事件,如“开始标记”、“文本事件”等,如果解析到XML文档的结束,解析器会报告“文件结束”事件,事件处理器会调用endDocument()方法。解析器在解析XML文件的过程中,只能报告一次“文件开始”事件和“文件结束”事件。如果要实现处理“文件结束”和“文件开始”事件,需要在程序的类中重写这两个继承的方法。
7.2.2 处理指令
该处理指令使得XML文件关联到某个层叠样式表,其路径为url。当SAX解析器处理XML文件时,如果发现XML文档中的处理指令会报告一个“处理指令”事件给事件处理器,事件处理器会调用下面的方法处理。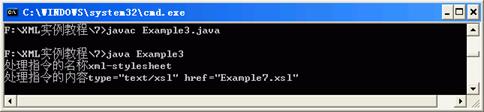
7.2.3 处理开始和结束标记
在解析器解析XML文档时,如果发现了开始标记,就会触发“开始标记”事件,并向事件处理器发送一个“开始标记”事件报告。事件处理器获得发送的事件报告信息,就会调用方法。
7.2.4 处理文本数据
XML文件中标记的内容是文本数据,当SAX解析器解析这些数据时,就报告“文本数据”事件给事件处理器,事件处理器获取事件信息后,就会调用下面的方法:
public void characters(char[] ch,int start,int length)throws SAXException
7.2.5 处理空白
人们习惯上称标记之间的缩进区域是可忽略空白,这实际上不是很准确,应为XML文件的标记可以有文本和子标记,在这种情况下,标记之间的区域就可能包含非空白的字符内容(混合内容)。如果我们不允许标记有混合内容,即标记要么只包含有子标记要么只包含有文本数据,在这种情形下,称标记之间缩进区域是可忽略空白就比较恰当,这些空白区使得XML文件看起来更加美观,是没有价值的文本数据。
7.2.6 处理名称空间
在XML文档中,名称空间主要是有效的区分名字相同的标记。当使用两个标记的名字相同时,它们可以通过隶属不同的名称空间来相互区分。名称空间通过声明名称空间来建立,分为有前缀的名称空间和无前缀的名称空间。
7.2.7 处理实体
在XML文档中,利用DTD可以定义实体,然后与该DTD文件关联的XML文件可以通过实体引用使用该实体。实体又分为内部实体和外部实体,所谓内部实体就是实体的内容包含在DTD文件本身中;而外部实体是指实体的内容是DTD文件以外的其他文件。
7.2.8 SAX应用程序异常
从上面的案例中,可以看出解析在调用parese方法时,必须使用try-catch语句来捕获SAXException异常,当SAXException异常发生时,parse方法会离开结束执行,停止解析过程。实际上,DefaultHandler类中的方法都可以抛出一个SAXException对象给解析器,比如,事件处理在调用startDocument()方法时,突然决定终止解析文件,就可以抛出一个SAXException对象给解析器,解析器将停止parse方法的执行。
7.3 SAX与DOM接口比较
基于DOM接口的解析器,解析XML文档时,会将XML文档以树模型的方式加载到内存中。此时应用程序可以对树模型的任一个部分进行遍历和操作,通过DOM的树模型可以实现对XML文档的随机访问。这种访问方式给应用程序的开发带来了很大的灵活性,它可以任意地控制整个XML文档中的内容。然而,由于DOM解析器把整个XML文档转化成DOM树放在了内存中,因此,当XML文档比较大或者文档结构比较复杂时,对内存的需求就比较高。而且,对于结构复杂的树的遍历也是一项比较耗时的操作。所以,DOM解析器对机器性能的要求比较高,实现效率不十分理想。不过,由于DOM解析器的树结构的思想与XML文档的结构相吻合,所以通过DOM树机制很容易实现随机访问。
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example1{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();//创建SAX解析器
MyHandler handler=new MyHandler();//创建事件处理器
saxParser.parse(new File("Example1.xml"),handler);//绑定文件和事件处理者
System.out.println("该XML文件共有"+handler.count+"标记");
}
catch(Exception e)
{System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
int count=0;
public void startDocument(){//解析到文档开始时调用该方法
System.out.println("开始解析XML文件");
count++;
}
public void endDocument(){//解析到文档结束时调用该方法
System.out.println("解析文件结束");
count++;
}
public void startElement(String uri,String localName,String qName,Attributes atts){ //解析到标记开始时调用该方法
System.out.println("<"+qName+">");
count++;
}
public void endElement(String uri,String localName,String qName){//解析到标记结束时调用该方法
System.out.println("<"+qName+">");
count++;
}
public void characters(char[] ch,int start,int length){//解析到标记间的数据时调用该方法
String text=new String(ch,start,length);
System.out.println(text);
count++;
}
}
<?xml version="1.0" encoding="GB2312"?>
<员工名单>
<员工>
<姓名>黄胜霞</姓名>
<岗位>前台接待</岗位>
</员工>
</员工名单>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example2{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
File file=new File("Example2.xml"); //创建File文件对象
MyHandler handler=new MyHandler(file);//创建MyHandler对象
saxParser.parse(file,handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
File file;
long starttime,endtime;
public MyHandler(File f){
file=f;
}
public void startDocument(){
starttime=System.currentTimeMillis();
System.out.println("文件所在路径是"+file.getAbsolutePath());
System.out.println("文件名为"+file.getName());
System.out.println("开始解析XML文件---------");
}
public void endDocument(){
System.out.println("解析XML文件结束--------");
endtime=System.currentTimeMillis();
System.out.println("文件解析共花费"+(endtime-starttime)+"秒");
}
}
<?xml version="1.0" encoding="GB2312"?>
<招聘单位>
<单位>
<名称>河南惠通公司</名称>
<公司信息>软件开发和书本编辑</公司信息>
<职位>项目经理</职位>
<岗位要求>计算机相关专业本科以上学历,三至五年工作经验</岗位要求>
</单位>
</招聘单位>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example3{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
File file=new File("Example3.xml"); //创建文件对象file指向XML文件
MyHandler handler=new MyHandler(file);//创建事件处理器
saxParser.parse(file,handler);//用解析器把XML文件和事件处理器绑定
}
catch(Exception e){System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
File file;
public MyHandler(File f){
file=f;
}
public void processingInstruction(String target,String data){
System.out.println("处理指令的名称"+target);
System.out.println("处理指令的内容"+data);
}
}
<?xml version="1.0" encoding="gb2312"?>
<?xml-stylesheet type="text/xsl" href="Example7.xsl"?>
<火车票表>
<车票>
<班次>T99</班次>
<始发时间>11:30</始发时间>
</车票>
<车票>
<班次>S234</班次>
<始发时间>13:04</始发时间>
</车票>
</火车票表>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example4{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
factory.setNamespaceAware(true);//设定该解析器工厂支持名称空间
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example4.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
int count=0;
String str=null;
public void startElement(String uri,String localName,String qName,Attributes atts){
count++;
if(uri.length()>0)
{str=uri;
System.out.println(str);
}
System.out.print("<"+qName+" ");
for(int k=0;k<atts.getLength();k++){//获得该标记的属性,并输出属性名称和值。
System.out.print(atts.getLocalName(k)+"=");
System.out.print("\""+atts.getValue(k)+"\"");
}
System.out.println(">");
}
public void endElement(String uri,String localName,String qName){
System.out.println("</"+qName+">");
}
public void endDocument(){
System.out.println("解析文件结束一共有"+count+"标记");
System.out.println("文件使用的名称空间是"+str);
}
}
<?xml version="1.0" encoding="gb2312"?>
<root xmlns:p1="liu">
<p1:聊天 grade="10">
侃大山
</p1:聊天>
<p1:讲课 type="网络教学">
传授知识
</p1:讲课>
<空话/>
</root>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example5{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example5.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
boolean isDigit=false,zhusu=false,lufei=false;
double personsum=0;
int count=0;
double zhususum=0,lufeisum=0;
public void startElement(String uri,String localName,String qName,Attributes atts){
System.out.print("<"+qName+">");
if(qName.endsWith("费"))//判断标记间包含的是否是文本数据
isDigit=true;
if(qName.equals("住宿费"))
zhusu=true;
if(qName.equals("路费"))
lufei=true;
if(qName.equals("名称"))
{
count++;
personsum=0;
}
}
public void characters(char[] ch,int start,int length){
String text=new String(ch,start,length);
if(isDigit==true)//如果标记间的数据为文本数据
{
String str=text.trim();
if(str.length()>0){
double dd=Double.parseDouble(str);
personsum=personsum+dd;
if(zhusu)
zhususum=zhususum+dd;
if(lufei)
lufeisum=lufeisum+dd;
isDigit=false;
}
}
System.out.print(text);
}
public void endElement(String uri,String localName,String qName){
System.out.print("<"+qName+">");
zhusu=false;
lufei=false;
if(qName.equals("员工"))
{
System.out.print("员工需要报销"+personsum+"元");
}
}
public void endDocument(){
System.out.println(" ");
System.out.println("员工住宿费的平均值为"+zhususum/count);
System.out.println("员工路费的平均值为"+lufeisum/count);
}
}
<?xml version="1.0" encoding="gb2312"?>
<员工报销单>
<员工>
<名称>魏怀超</名称>
<住宿费>234.8</住宿费>
<路费>150</路费>
</员工>
<员工>
<名称>王利甫</名称>
<住宿费>534.8</住宿费>
<路费>232</路费>
</员工>
</员工报销单>
<!ELEMENT 商品信息 (商品)>
<!ELEMENT 商品 (名称,价钱)>
<!ELEMENT 名称 (#PCDATA)>
<!ELEMENT 价钱 (#PCDATA)>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example6{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example6.xml"),handler);
}
catch(Exception e){System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
int count=0;
public void ignorableWhitespace(char[] ch,int start, int length){
count++;
System.out.println("第"+count+"个空白区");
}
public void endDocument(){
System.out.println("解析文件结束报告了"+count+"次空白");
}
}
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE 商品信息 SYSTEM "Example6.dtd">
<商品信息>
<商品>
<名称>海尔洗衣机</名称>
<价钱>2999元</价钱>
</商品>
</商品信息>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example7{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
factory.setNamespaceAware(true);//设定可以解析名称空间
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example7.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
int count=0;
public void startPrefixMapping(String prefix,String uri)throws SAXException{
count++;
System.out.println("前缀"+prefix+" ");
System.out.println("名称空间的名称"+uri+" ");
}
public void endPrefixMapping(String prefix) throws SAXException{
System.out.println("前缀"+prefix+" ");
}
public void endDocument(){
System.out.println("解析文件结束,报告了"+count+"次名称空间");
}
}
<?xml version="1.0" encoding="GB2312" ?>
<学生名单 xmlns:a="henan" xmlns:b="shangdong">
<a:王峰>男,1992年出生</a:王峰>
<b:王峰>男,1994年出生</b:王峰>
<李明伟>女,1993年出生</李明伟>
</学生名单>
<!ENTITY hello "2008奥运会">
<!ENTITY txt PUBLIC "-//ISO333/vvv/FORXML/EN" "Example8.txt">
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example8{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
factory.setNamespaceAware(true);
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example8.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
int count=0;
public InputSource resolveEntity(String publicId,String systemId){
count++;
System.out.println(publicId);
System.out.println(systemId);
return null;
}
public void characters(char[] ch,int start,int length){
String text=new String(ch,start,length);
System.out.print(text);
}
public void endDocument(){
System.out.println("解析结束,报告了"+count+"个实体,包括DOCTYPE声明");
}
}
学习雷锋好榜样
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE 商场 PUBLIC "-//iso/Daxian/EN" "Example8.dtd">
<商场>
<柜台标语>
&hello;&txt;
</柜台标语>
</商场>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
import java.util.*;
public class Example9{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example9.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
boolean bo=false;
boolean sa=true;
public void startElement(String uri,String localName,String qName,Attributes atts) {
System.out.print("<"+qName+">");
if(qName.equals("出生日期"))
bo=true;
}
public void endElement(String uri,String localName,String qName) {
System.out.print("<"+qName+">");
}
public void characters(char[] ch,int start,int length) throws SAXException{
String text=new String(ch,start,length);
if(bo==true){
text=text.trim();
StringTokenizer fenxi=new StringTokenizer(text,"-");
int number=fenxi.countTokens();
String str[]=new String[number];
if(number!=3) {
sa=false;
}
else{
int k=0;
while(fenxi.hasMoreTokens()){
str[k]=fenxi.nextToken();
k++;
}
try{
int year=Integer.parseInt(str[0]);
int month=Integer.parseInt(str[1]);
int day=Integer.parseInt(str[2]);
if(year<=1900 || year>=2009)
sa=false;
if(month<=0 || month>=13)
sa=false;
if(day<=0 || day>31)
sa=false;
}
catch(NumberFormatException e){sa=false;}
}
if(sa==false){
throw new SAXException("数据不合理,停止解析");
}
else{
System.out.print(text);
}
}
else{System.out.println(text);}
}
}
<?xml version="1.0" encoding="GB2312" ?>
<学生名单>
<学生>
<姓名>崔忠伟</姓名>
<出生日期>2006-13-20</出生日期>
</学生>
</学生名单>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
public class Example10{
public static void main(String args[]){
try{
SAXParserFactory factory1=SAXParserFactory.newInstance();
SAXParser saxParser=factory1.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example10.xml"),handler);
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.newDocument(); //创建document节点对象
document.setXmlVersion("1.0");//设置使用XML文件的版本
Element root=document.createElement("图书列表");
document.appendChild(root);//设置XML文件的根结点
for(int k=1;k<=handler.str1.length;k++){
root.appendChild(document.createElement("图书"));
}
NodeList nodeList=document.getElementsByTagName("图书");//获得图书的节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE)
{
Element elementNode=(Element)node;
elementNode.appendChild(document.createElement("名称"));//为图书添加一个名称标记
elementNode.appendChild(document.createElement("价格"));//为图书添加一个价格标记
}
}
nodeList=document.getElementsByTagName("名称");//获得名字的节点集合
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.appendChild(document.createTextNode(handler.str0[k])); //为标记添加文本数据。
}
}
nodeList=document.getElementsByTagName("价格");//获得名字的节点集合
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.appendChild(document.createTextNode(handler.str1[k])); //为标记添加文本数据。
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();//创建一个TransformerFactory(转换工厂对象)
Transformer transformer=transFactory.newTransformer();//创建一个Transformer对像(文件转换对象)
DOMSource domSource=new DOMSource(document); //把要转换的Document对象封装到一个DOMSource类中
File file=new File("图书列表1.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);//将要变换得到XML文件将来保存在StreamResult
transformer.transform(domSource,xmlResult);//把节点树转换为XML文件
}
catch(Exception e){
System.out.println(e);
e.printStackTrace();
}
}
}
class MyHandler extends DefaultHandler{
String str1[]=new String[3];
String str0[]=new String[3];
boolean letter=false,bo=false;
int i=0;
String aa;
public void startElement(String uri,String localName,String qName,Attributes atts) {
if(qName.equals("名称"))
{
bo=true;
}
if(qName.equals("价格")){
letter=true;}
}
public void characters(char[] ch,int start,int length){
String text=new String(ch,start,length);
if(bo){
aa=text.trim();
bo=false;
}
if(letter){
double dd=Double.parseDouble(text.trim());
if(dd>35){
str1[i]=text.trim();
str0[i]=aa;
i++;
}
letter=false;
}
}
}
<?xml version="1.0" encoding="GB2312" ?>
<书库>
<图书>
<名称>XML实践编程</名称>
<作者>刘瑞银</作者>
<类别>计算机图书</类别>
<价格>39.8</价格>
</图书>
<图书>
<名称>Java从入门到精通</名称>
<作者>刘海松</作者>
<类别>计算机图书</类别>
<价格>58.2</价格>
</图书>
<图书>
<名称>社会百态</名称>
<作者>李天波</作者>
<类别>文学图书</类别>
<价格>29.3</价格>
</图书>
<图书>
<名称>我们的家园</名称>
<作者>温全国</作者>
<类别>地理图书</类别>
<价格>63</价格>
</图书>
<图书>
<名称>金融动态</名称>
<作者>石金峰</作者>
<类别>经济类图书</类别>
<价格>35</价格>
</图书>
</书库>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example11{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example11.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
Locator locator;
int row,line;
public void setDocumentLocator(Locator locator){
this.locator=locator;
}
public void characters(char[] ch,int start,int length){
String text=new String(ch,start,length);
System.out.print(text);
line=locator.getLineNumber();
row=locator.getColumnNumber();
System.out.print("[该数据末尾在文件中的位置("+row+","+line+")]");
}
}
<?xml version="1.0" encoding="GB2312" ?>
<学生>
<姓名>常红</姓名>
<姓名>王峰</姓名>
</学生>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example12{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
factory.setNamespaceAware(true);//设定该解析器工厂支持名称空间
SAXParser saxParser=factory.newSAXParser();
MyHandler handler=new MyHandler();
saxParser.parse(new File("Example7.xml"),handler);
}
catch(Exception e){
System.out.println(e);
}
}
}
class MyHandler extends DefaultHandler{
public void startPrefixMapping(String prefix,String uri)throws SAXException{
System.out.println("前缀"+prefix+" ");
System.out.println("名称空间的名称"+uri+" ");
}
}
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example13{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();//创建SAX解析器
MyHandler handler=new MyHandler();//创建事件处理器
saxParser.parse(new File("Example13.xml"),handler);//绑定文件和事件处理者
}
catch(Exception e)
{System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
public void characters(char[] ch,int start,int length){//解析到标记间的数据时调用该方法
String text=new String(ch,start,length);
System.out.println(text.trim());
}
}
<?xml version="1.0" encoding="GB2312" ?>
<员工名单>
<员工>
<名称>范强</名称>
<职务>经理</职务>
<工资>2200</工资>
</员工>
<员工>
<名称>孙少元</名称>
<职务>项目组长</职务>
<工资>1897</工资>
</员工>
<员工>
<名称>王冰</名称>
<职务>普通员工</职务>
<工资>1650</工资>
</员工>
<员工>
<名称>刘华林</名称>
<职务>经理</职务>
<工资>2580</工资>
</员工>
</员工名单>
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example14{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();//创建SAX解析器
MyHandler handler=new MyHandler();//创建事件处理器
saxParser.parse(new File("Example13.xml"),handler);//绑定文件和事件处理者
}
catch(Exception e)
{System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
boolean check=false;
boolean gong=false;
boolean mingc=false;
String str1="",str2="",str3="";
public void startElement(String uri,String localName,String qName,Attributes atts){
if(qName.equals("名称"))
mingc=true;
if(qName.equals("职务"))
check=true;
if(qName.equals("工资"))
gong=true;
}
public void characters(char[] ch,int start,int length){//解析到标记间的数据时调用该方法
String text=new String(ch,start,length);
if(mingc){
str1=text.trim();
mingc=false;
}
if(check){
if(text.trim().equals("经理")){
str2=text.trim();
check=false;
}
}
if(gong){
double dd=Double.parseDouble(text.trim());
if(dd>2500)
{
str3=text.trim();
System.out.print(str1+" .. "+str2+"
 "+dd);
"+dd);}
gong=false;
}
}
}
import javax.xml.parsers.*;
import org.xml.sax.helpers.*;
import org.xml.sax.*;
import java.io.*;
public class Example15{
public static void main(String args[]){
try{
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser saxParser=factory.newSAXParser();//创建SAX解析器
MyHandler handler=new MyHandler();//创建事件处理器
saxParser.parse(new File("Example13.xml"),handler);//绑定文件和事件处理者
}
catch(Exception e)
{System.out.println(e); }
}
}
class MyHandler extends DefaultHandler{
int jinsum=0,yuansum=0;
boolean jingl=false;
boolean yuang=false;
boolean gongz=false;
public void startElement(String uri,String localName,String qName,Attributes atts){
if(qName.equals("工资"))
gongz=true;
}
public void characters(char[] ch,int start,int length){
String text=new String(ch,start,length);
if(text.trim().equals("经理"))
{jingl=true;}
if(text.trim().equals("普通员工"))
{yuang=true;}
if(jingl && gongz){
double dd=Double.parseDouble(text.trim());
jinsum+=dd;
jingl=false;
}
if(yuang && gongz){
double dd1=Double.parseDouble(text.trim());
yuansum+=dd1;
yuang=false;
}
gongz=false;
}
public void endDocument(){
System.out.println("解析XML文件结束--------");
System.out.println("经理工资合计"+jinsum);
System.out.println("员工工资合计"+yuansum);
}
}
<?xml version="1.0" encoding="GB2312"?>
<产品列表>
<产品>
<序列号>2586</序列号>
<名称>餐桌</名称>
<价格>499.00</价格>
</产品>
<产品>
<序列号>2587</序列号>
<名称>椅子</名称>
<价格>199.00</价格>
</产品>
<产品>
<序列号>2586</序列号>
<名称>茶几</名称>
<价格>19.99</价格>
</产品>
<产品>
<序列号>2588</序列号>
<名称>碗橱</名称>
<价格>699.00</价格>
</产品>
</产品列表>
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<图书列表>
<图书>
<名称>XML实践编程</名称>
<价格>39.8</价格>
</图书>
<图书>
<名称>Java从入门到精通</名称>
<价格>58.2</价格>
</图书>
<图书>
<名称>我们的家园</名称>
<价格>63</价格>
</图书>
</图书列表>


