第6章 DOM解析XML文档
XML能很好、方便的描述和组织数据,在很多实际问题中,人们非常关心XML的数据结构,并根据其结构提取自己需要的数据。XML解析器是XML和应用程序之间的一个软件组织,为应用程序从XML文件中解析出所需要的数据。常见的解析器包括基于DOM的解析器和基于事件的解析器。
在本章中,将会详细XML文档解析过程、DOM树模型、DOM基本接口、DOM的节点访问和DOM对文档的相关操作。
本章知识要点:
了解XML文档解析器
掌握DOM概念
熟练掌握DOM文档树模型
熟练掌握DOM级别接口
掌握DOM对象的创建和调用
熟练掌握访问各种类型节点
掌握动态创建XML文档
熟练掌握各种类型节点的添加、删除等操作
掌握异常处理
6.1 XML文档解析
在我们程序中,经常需要对XML文档进行分析,以检索、修改、删除或重新组织其中的内容。例如,将应用程序运行所需的一些配置信息,以XML的格式保存在文件中,在程序启动时,读取XML文件,从中取出有用的信息,这就需要对XML文档解析。
6.1.1 XML解析器
XML处理都从解析开始。无论使用高层编程语言(如XSLT)还是低层Java编程,第一步都是要读入XML文件,解码结构和检索信息等等,这就是解析。解析可能是开发人员能够使用的最基本的服务。解析文档时面临的第一个选择是采用现成的解析库(基本上每种编程语言都有,包括COBOL[Common Business Oriented Language])还是自己创建一个。答案非常简单:选择现成的库。
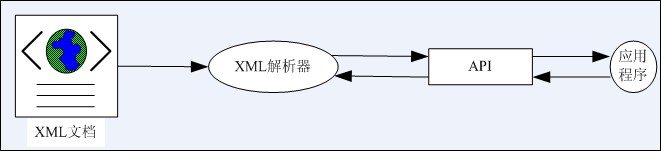
6.1.2 常用解析器接口
一个XML解析器可以支持多个API接口,如DOM接口或SAX接口,可以把这些解析器称为DOM解析器或SAX解析器。现在比较和常用的解析器有DOM解析器、SAX解析器、DOM4J和JDOM等。
6.2 DOM介绍
DOM是Document Object Model的缩写,即文档对象模型,是W3C组件推荐的处理XML的标准接口,定义了所有文档元素的对象和属性,以及访问它们的方法(接口)。W3C文档对象模型(DOM)定义了访问诸如XML和XHTML文档的标准,是一个使程序和脚本有能力动态地访问和更新文档的内容、结构以及样式的平台和语言中立的接口。
6.3 DOM文档树模型
DOM规范的核心就是树模型,对于要解析的XML文档,解析器会把XML文档加载到内存中,在内存中为XML文件建立逻辑形式的树。从本质上说,DOM就是XML文档的一个结构化的视图,它将一个XML文档看作是一棵节点树,而其中的每一个节点代表一个可以与其进行交互的对象。树的节点是一个个的对象,这样通过操作这棵树和这些对象就可以完成对XML文档的操作,为处理文档的所有方面提供了一个完美的概念性框架。
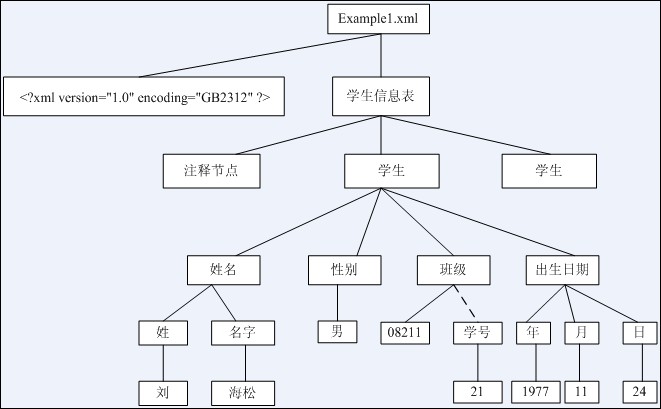
6.4 DOM接口对象
不管XML文档有多简单或者多复杂,在加载到内存中都会被转化成一棵对象节点树。该节点树中存在了不同类型的节点,如属性形成的节点、元素标记形成的节点、注释形成的节点、标记内容形成的节点。节点树生成之后,就可以通过DOM接口访问、修改、添加、删除、创建树中的节点和内容。
6.4.1 DOM基本接口
在DOM接口规范中,包含有多个接口。其中常用的基本接口有Document接口、Node接口、NamedNodeMap接口、NodeList接口、Element接口、Text接口、CDATASection接口和Attr接口等接口。其中,Document接口是对文档进行操作的入口,它是从Node接口继承过来的。Node接口是其他大多数接口的父类,象Documet、Element、Attribute、Text、Comment等接口都是从Node接口继承过来的。NodeList接口是一个节点的集合,它包含了某个节点中的所有子节点。NamedNodeMap接口也是一个节点的集合,通过该接口,可以建立节点名和节点之间的一一映射关系,从而利用节点名可以直接访问特定的节点。
6.4.2 DOM对象
接口是一组方法声明的集合,没有具体的实现。这些方法具有共同的特征,即共同作用于XML文档中某一个对象的一类方法。当我们用编程语言实现这个接口的一个对象,那么该对象我们就可以称为DOM对象。如Attr这个接口,里面封装的关于节点属性方面的操作方法,如获的属性的名称,获得属性的值等。如果一个Attr对象实现了这个接口,那么此对象就是DOM对象,即属性操作对象。
6.5 DOM使用
创建DOM对象、加载XML文档和处理XML文档是使用DOM解析器处理解析XML文档的基本步骤。在本节中,我们将详细介绍DOM对象在不同语言中的创建方式、加载XML文档和访问XML文档的不同的节点。
6.5.1 DOM对象创建及调用
本章将主要介绍Sun公司的DOM解析器的创建和使用,Sun公司的解析器是支持DOM level 3的解析器。为了让Java开发人员以一种标准的方式对XML进行编程,Sun公司制定了JAXP(Java API for XML Processing)规范。JAXP没有提供解析XML的新方法,也没有为XML的处理提供新功能,它只是在解析器之上封装了一个抽象层,允许开发人员以独立于厂商的API调用访问XML数据。
6.5.2 访问Document节点
Java应用程序可以从Dcoument节点的子孙节点中获取整个XML文件中数据的细节。Document节点对象两个直接子节点,类型分别是DocumentType类型和Element类型,其中的DocumentType节点对应着XML文件所关联的DTD文件,可通过进一步获取该节点子孙节点来分析DTD文件中的数据;Element类型节点对应着XML文件的根节点,可通过进一步获取该Element类型节点子孙节点来分析XML文件中的数据。
6.5.3 访问Element节点
Element接口是比较重要的接口,该接口被实例化后,会对应节点树中的Element节点,我们这里称为Element节点。Element节点可以有Element子节点和Text子节点(规范的XML文件的标记可以有子标记和文本数据)。若一个节点使用getNodeType()方法测试,如果返回值为Node.ELEMENT_NODE,那么该节点就是Element节点。
|
名称
|
说明
|
|
getTagName()
|
返回该节点的名称,节点名称就是对应的XML文件的标记名称
|
|
getAtrribute(String name)
|
返回该节点中参数name指定的属性值,XML标记中对应的属性值
|
|
getElementsByTagName(String name)
|
返回一个NodeList对象
|
|
has Attribute(String name)
|
判断当前节点是否存在名字为name的指定的属性
|
|
removeAttribute(String name)
|
通过名称移除一个属性
|
|
setAttribute(String name, String value)
|
添加一个新属性
|
6.5.4 访问Text节点
通过Text接口实现的对象称为Text对象,该对象对应着节点树中的文本节点,也可把该对象称为Text节点对象。我们知道,Element节点对象和元素标记相对应,文本内容和Text节点相对应。若判断一个节点是否是Text节点,可通过getNodeType()判断,如该方法返回值为Node.TEXT_NODE,那么该节点就是Text节点。Element节点可以有Text节点和Element节点。
|
名称
|
说明
|
|
getWholeText()
|
返回Text节点(逻辑上与此节点相邻的节点)的以文档顺序串接的所有文本
|
|
isElementContentWhitespace()
|
返回此文本节点是否包含元素内容空白符,即经常所称的“可忽略的空白符”
|
|
replaceWholeText(String content)
|
将当前节点和所有逻辑上相邻的文本节点的文本替换为指定的文本
|
|
splitText(int offset)
|
在指定的offset处将此节点拆分为两个节点,并将二者作为兄弟节点保持在树中
|
6.5.5 访问Attr节点
XML文件中标记所包含的属性,在节点树中,对应的是Attr节点。Attr节点是Attr接口的实例化对象,Attr接口表示Element对象中的属性,Attr对象继承Node接口,但由于它们实际上不是它们描述的元素的子节点,DOM不会将它们看作文档树的一部分,DOM认为元素的属性是其特性,而不是一个来自于它们所关联的元素的独立的身份;这应该使实现把这种特征作为与所有给定类型的元素相关联的默认属性更为有效。
|
名称
|
说明
|
|
getName()
|
返回属性名称
|
|
getOwnerElement()
|
此属性连接到的Element节点;如果未使用此属性,则为null
|
|
getValue()
|
检索时,该属性值以字符串形式返回
|
|
setValue(String value)
|
检索时,该属性值以字符串形式返回
|
6.6 DOM对文档操作
通过DOM不但可以遍历XML文档指定的节点,如Element节点、文本节点和属性节点等,还可以对在内存中存在的树模型进行操作,如添加、删除或修改节点,添加、删除或修改属性,添加元素内容等。
6.6.1 动态创建XML文档
DOM解析器通过在内存中建立和XML结构相对应的树状结构数据,使得应用程序可以方便地获得XML文件中的数据。JAXP也提供了使用内存中的树状结构数据建立一个XML文件的API,即使用解析器得到的Document对象建立一个新的XML文件。
|
名称
|
说明
|
|
appendChild(Node newChild)
|
向当前节点增加一个新的子节点,并返回这个新节点
|
|
removeChild(Node oldChild)
|
删除参数指定的子节点,并返回被删除的子节点
|
|
replaceChild(Node newChild, Node oldChild)
|
替换子节点,并返回被替换的子节点
|
|
removeAttributeNode(Attr oldAttr)
|
删除Element节点的属性
|
|
setAttribute(String name, String value)
|
为Element节点增加新的属性及属性值,如果该属性已经存在,新的属性将替换旧的属性。
|
|
replaceWholeText(String content)
|
替换当前Text节点的文本内容
|
|
appendData(String arg)
|
向当前Text节点尾加文本内容
|
|
insertData(int offset, String arg)
|
向当前Text节点插入文本内容,插入的位置由参数offset指定,即第offset个字符的后继位置
|
|
deleteData(int offset,int count)
|
删除当前节点的文本内容中的一部分。被删除的范围由参数offset和count指定,即从第offset个字符后续的count个字符
|
|
replaceData(int offset,int count, String arg)
|
当前Text节点中文本内容的一部分替换为参数arg指定的内容,被替换的范围由参数offset和count指定,即从第offset个字符后续的count个字符
|
6.6.2 添加和删除元素节点
XML文档被加载到内存后,可以对其形成的XML文档树中的节点进行操作,如在根标记下添加一个节点,或删除一个已有的节点。
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<手机>
<品牌>Nokia</品牌>
<型号>5200</型号>
<价格>588</价格>
</手机>
6.6.3 添加和删除属性节点
XML文档中标记的属性具有属性名称和属性值,如果通过DOM形成XML文档的树模型,会形成属性节点和相应的文本节点。此时,可以对DOM树模型中属性节点进行添加和删除操作。
6.6.4 添加或修改文本节点
在DOM的树模型中,可以通过文本节点对更新节点内的数据,如添加新的内容,或修改旧的内容。
6.6.5 异常处理
大多数DOM下的异常都是作为DOMException类的一个实例发生的。这个类支持15种不同的、具体的异常条件。每种条件都被指定为DOMException类的一个成员,叫做code。除了这个code成员,DOMException类还包含一组15个静态成员,它们被用来确定异常的条件。

 employees.html
employees.html
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>显示XML文档数据</title>
<script language="javascript">
function loadXML(handler) {
var url = "employees.xml";
if(document.implementation&&document.implementation.createDocument) {
var xmldoc = document.implementation.createDocument("", "", null);
xmldoc.onload = handler(xmldoc, url);
xmldoc.load(url);
}
else if(window.ActiveXObject) {
var xmldoc = new ActiveXObject("Microsoft.XMLDOM");
xmldoc.onreadystatechange = function() {
if(xmldoc.readyState == 4) handler(xmldoc, url);
}
xmldoc.load(url);
}
}
function makeTable(xmldoc, url) {
var table = document.createElement("table");
table.setAttribute("border","1");
table.setAttribute("width","600");
table.setAttribute("class","tab-content");
document.body.appendChild(table);
var caption = "员工信息" + url;
table.createCaption().appendChild(document.createTextNode(caption));
var header = table.createTHead();
var headerrow = header.insertRow(0);
headerrow.insertCell(0).appendChild(document.createTextNode("姓名"));
headerrow.insertCell(1).appendChild(document.createTextNode("职业"));
headerrow.insertCell(2).appendChild(document.createTextNode("工资"));
var employees = xmldoc.getElementsByTagName("employee");
for(var i=0;i<employees.length;i++) {
var e = employees[i];
var name = e.getAttribute("name");
var job = e.getElementsByTagName("job")[0].firstChild.data;
var salary = e.getElementsByTagName("salary")[0].firstChild.data;
var row = table.insertRow(i+1);
row.insertCell(0).appendChild(document.createTextNode(name));
row.insertCell(1).appendChild(document.createTextNode(job));
row.insertCell(2).appendChild(document.createTextNode(salary));
}
}
</script>
<link href="css/style.css" rel="stylesheet" type="text/css">
</head>
<body onLoad="loadXML(makeTable)">
</body>
</html>employees
<?xml version="1.0" encoding="gb2312"?>
<employees>
<employee name="马宝生">
<job>厨师</job>
<salary>2528</salary>
</employee>
<employee name="孙少恩">
<job>售货员</job>
<salary>1680</salary>
</employee>
<employee name="王峰">
<job>硬件维护员</job>
<salary>1200</salary>
</employee>
</employees>
example2.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example2{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example2.xml"));
String version=document.getXmlVersion();
System.out.println("XML文档版本为:"+version);
String encoding=document.getXmlEncoding();
System.out.println("XML文档的编码是"+encoding);
}
catch(Exception e){
System.out.println(e);
}
}
}
example2
<?xml version="1.0" encoding="GB2312"?>
<公交车次>
<车次>32</车次>
<始发>6:30</始发>
</公交车次>
example3.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example3{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example3.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();
System.out.println("XML文件根结点的名称为:"+rooName);
NodeList nodelist=document.getElementsByTagName("图书");
int size=nodelist.getLength();
for(int i=0;i<size;i++){
Node node=nodelist.item(i);
String name=node.getNodeName();
String content=node.getTextContent();
System.out.println(name);
System.out.println(content);
}
}
catch(Exception e){
System.out.println(e);
}
}
}
example3
<?xml version="1.0" encoding="GB2312"?>
<书店>
<图书 类别="烹饪">
<标题 语种="中文">家常菜二十一招</标题>
<作者>刘华林</作者>
<出版日期>2007</出版日期>
<价格>12.00</价格>
</图书>
</书店>
example4.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example4{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example4.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();
System.out.println("XML文件根结点的名称为:"+rooName);
NodeList nodelist=root.getChildNodes();
int size=nodelist.getLength();
for(int i=0;i<size;i++){
Node node=nodelist.item(i);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
String name=elementNode.getNodeName();
String id=elementNode.getAttribute("时间");
String content=elementNode.getTextContent();
System.out.println(name+" "+id+" "+content+"\n");
}
}
}
catch(Exception e){
System.out.println(e);
}
}
}
example4
<?xml version="1.0" encoding="GB2312"?>
<日程计划>
<日程1 时间="8:00-10:00">修改文稿</日程1>
<日程2 时间="10:00-16:00">看书</日程2>
<日程3 时间="16:00-18:00">跑步</日程3>
</日程计划>
example5.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example5{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example5.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();
System.out.println("XML文件根结点的名称为:"+rooName);
NodeList nodelist=root.getChildNodes();
TotalM tt=new TotalM();//创建一个类的对象
tt.outP(nodelist);//使用创建的对象调用节点集合。
System.out.println("普通员工月收入合计"+tt.sumP);
System.out.println("经理月收入合计"+tt.sumB);
System.out.println("所有员工月收入合计"+tt.sumA);
}
catch(Exception e){
System.out.println(e);
}
}
}
class TotalM{
double sumA,sumP,sumB;
public void outP(NodeList nodelist){
int size=nodelist.getLength();
for(int i=0;i<size;i++){
Node node=nodelist.item(i);
if(node.getNodeType()==Node.TEXT_NODE){
Text textNode=(Text)node;
String content=textNode.getWholeText();
System.out.print(content);
Element parent=(Element)textNode.getParentNode();
if(parent.getNodeName().equals("月薪")){
sumA=sumA+Double.parseDouble(content.trim());
String str=parent.getAttribute("职务");
if(str.equals("普通员工"))
sumP=sumP+Double.parseDouble(content.trim());
if(str.equals("经理"))
sumB=sumB+Double.parseDouble(content.trim());
}
}
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
String name=elementNode.getNodeName();
System.out.print(name);
NodeList nodes=elementNode.getChildNodes();
outP(nodes);
}
}
}
}
example5
<?xml version="1.0" encoding="Gb2312"?>
<收入调查表>
<姓名>刘海松
<月薪 职务="经理">2000</月薪>
</姓名>
<姓名>刘红霞
<月薪 职务="普通员工">879</月薪>
</姓名>
<姓名>李张利
<月薪 职务="经理">3200</月薪>
</姓名>
<姓名>陈凡灵
<月薪 职务="普通员工">1680</月薪>
</姓名>
</收入调查表>
example6.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example6{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example6.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();//获的根结点的名称
System.out.println("XML文件根结点的名称为:"+rooName);
NodeList nodelist=root.getElementsByTagName("员工");//获得标记名为学生的所有的标记集合
int size=nodelist.getLength();
for(int i=0;i<size;i++){
Node node=nodelist.item(i);
String name=node.getNodeName();
NamedNodeMap map=node.getAttributes();//获得标记中属性的集合。
String content=node.getTextContent();
System.out.print(name);
for(int k=0;k<map.getLength();k++){//循环的形式输出标记中所有的属性
Attr attrNode=(Attr)map.item(k);
String attName=attrNode.getName();
String attValue=attrNode.getValue();
System.out.print(" "+attName+"="+attValue);
}
System.out.print(content);
}
}
catch(Exception e){
System.out.println(e);
}
}
}
example6
<?xml version="1.0" encoding="GB2312" ?>
<员工名单>
<员工 姓名="赵妍" 年龄="30" 性别="女">
项目经理
</员工>
<员工 姓名="王冰" 年龄="32" 性别="男">
普通员工
</员工>
</员工名单>
example7.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example7{
public static void main(String args[]){
try{
String train[]={"XML实践教程","JSP从入门到精通","Java实践教程"};
String type[]={"978-7-302-15488-4","7-302-12591-0","978-7-302-14337-6"};
String startTime[]={"王峰","刘海松","李章帅"};
//创建XML文档中需要的数据
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.newDocument(); //创建document节点对象
document.setXmlVersion("1.0");//设置使用XML文件的版本
Element root=document.createElement("图书列表");
document.appendChild(root);//设置XML文件的根结点
for(int k=1;k<=train.length;k++){
root.appendChild(document.createElement("图书"));
} //在根节点下添加了三个节点
NodeList nodeList=document.getElementsByTagName("图书");//获得图书的节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE)
{
Element elementNode=(Element)node;
elementNode.setAttribute("ISBN",type[k]);//为图书设置属性其取值从数组type中取。
elementNode.appendChild(document.createElement("名称"));//为图书添加一个名字标记
elementNode.appendChild(document.createElement("作者"));//为图书添加一个开车时间标记
}
}
nodeList=document.getElementsByTagName("名称");//获得名字的节点集合
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.appendChild(document.createTextNode(train[k])); //为标记添加文本数据。
}
}
nodeList=document.getElementsByTagName("作者");
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.appendChild(document.createTextNode(startTime[k]));
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();//创建一个TransformerFactory(转换工厂对象)
Transformer transformer=transFactory.newTransformer();//创建一个Transformer对像(文件转换对象)
DOMSource domSource=new DOMSource(document); //把要转换的Document对象封装到一个DOMSource类中
File file=new File("图书列表.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);//将要变换得到XML文件将来保存在StreamResult
transformer.transform(domSource,xmlResult);//把节点树转换为XML文件
}
catch(Exception e){
System.out.println(e);
}
}
}
example8.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example8{
public static void main(String args[]){
try{ DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example8.xml"));
Element root=document.getDocumentElement();
root.appendChild(document.createElement("价格"));//为根节点添加价格标记。
NodeList nodeList=document.getElementsByTagName("价格");//获得价格节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.appendChild(document.createTextNode("588")); //为标记添加文本数据。
}
}
nodeList=document.getElementsByTagName("出厂日期");//获得出厂日期节点集合
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
root.removeChild(node);
}
} //删除名称为出厂日期的节点
TransformerFactory transFactory=TransformerFactory.newInstance();
Transformer transformer=transFactory.newTransformer();
DOMSource domSource=new DOMSource(document);
File file=new File("Example8.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);
transformer.transform(domSource,xmlResult);
}
catch(Exception e){
System.out.println(e);
}
}
}
example8
<?xml version="1.0" encoding="utf-8" standalone="no"?><手机>
<品牌>Nokia</品牌>
<型号>5200</型号>
<价格>588</价格></手机>
example9.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example9{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example9.xml"));
Element root=document.getDocumentElement();
NodeList nodeList=document.getElementsByTagName("名称");//获得交通工具节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.removeAttribute("品牌");
}
}
nodeList=document.getElementsByTagName("价格");//获得交通工具节点集合
size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.setAttribute("币种","人民币");
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();
Transformer transformer=transFactory.newTransformer();
DOMSource domSource=new DOMSource(document);
File file=new File("Example9.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);
transformer.transform(domSource,xmlResult);
}
catch(Exception e){
System.out.println(e);
e.printStackTrace();
}
}
}
example9
<?xml version="1.0" encoding="utf-8"?>
<交通工具列表>
<交通工具>
<名称 品牌="飞鸽">自行车</名称>
<价格>568元</价格>
</交通工具>
<交通工具>
<名称 品牌="奇瑞">轿车</名称>
<价格>23568元</价格>
</交通工具>
</交通工具列表>
example10.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example10{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example10.xml"));
Element root=document.getDocumentElement();
NodeList nodeList=root.getElementsByTagName("图书名称");//获得书名的节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
String str=elementNode.getTextContent();
if(str.equals("")){
elementNode.setTextContent("Java经典案例");
}
if(str.equals("Java实践教程")){
elementNode.setTextContent("Ajax基础教程");
}
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();
Transformer transformer=transFactory.newTransformer();
DOMSource domSource=new DOMSource(document);
File file=new File("Example10.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);
transformer.transform(domSource,xmlResult);
}
catch(Exception e){
System.out.println(e);
}
}
}
example10
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<新书快递>
<图书名称>Ajax基础教程</图书名称>
<图书名称>Java经典案例</图书名称>
</新书快递>
example11.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example11{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example11.xml"));
DocumentType doctype=document.getDoctype();
String DTDName=doctype.getName();
System.out.println("DTD的名字:" +DTDName);
String publicId=doctype.getPublicId();
System.out.println("PUBLIC的标识:" +publicId);
String systemId=doctype.getSystemId();
System.out.println("systemId的标识:" +systemId);
String internalDTD=doctype.getInternalSubset();
System.out.println("内部DTD:" +internalDTD);
}
catch(Exception e){
System.out.println(e);
}
}
}
example11
<?xml version="1.0" encoding="GB2312" standalone="yes"?>
<!DOCTYPE 员工[
<!ELEMENT 姓名 (#PCDATA)>
<!ELEMENT 性别 (#PCDATA)>
<!ELEMENT 出生日期 (#PCDATA)>
]>
<员工>
<姓名>王良</姓名>
<性别>男</性别>
<出生日期>1978-2-12</出生日期>
</员工>
example12.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example12{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example12.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();
System.out.println("XML文件根结点的名称为:"+rooName);
int sum=0;
NodeList nodelist=document.getElementsByTagName("顾客");
int size=nodelist.getLength();
for(int i=0;i<size;i++) {
Node node=nodelist.item(i);
String name=node.getNodeName();
if(node.getNodeType()==Node.ELEMENT_NODE){
Element ele=(Element)node;
NodeList nl=node.getChildNodes();
for(int k=0;k<nl.getLength();k++){
Node nd=nl.item(k);
String name1=nd.getNodeName();
String content=nd.getTextContent();
System.out.print(name1+content);
}
}
}
}
catch(Exception e){
System.out.println(e);
}
}
}
example12
<?xml version="1.0" encoding="utf-8" standalone="no"?><顾客清单>
<顾客>
<姓名>张耀文</姓名>
<消费金额>200元</消费金额>
<联系方式 工具="手机/固定电话/小灵通">13633826164</联系方式>
</顾客>
<顾客>
<姓名>李田田</姓名>
<消费金额>1123元</消费金额>
<联系方式 工具="手机/固定电话/小灵通">037168346572</联系方式>
</顾客>
</顾客清单>
example13.java
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example13{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example12.xml"));
Element root=document.getDocumentElement();
String rooName=root.getNodeName();
System.out.println("XML文件根结点的名称为:"+rooName);
int sum=0;
NodeList nodelist=document.getElementsByTagName("消费金额");
int size=nodelist.getLength();
for(int i=0;i<size;i++){
Node node=nodelist.item(i);
String name=node.getNodeName();
String content=node.getTextContent();
sum=sum+Integer.parseInt(content.trim());
}
System.out.print("顾客的消费金额合计为:"+sum);
}
catch(Exception e){
System.out.println(e);
}
}
}
example14.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example14{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example12.xml"));
Element root=document.getDocumentElement();
NodeList nodeList=document.getElementsByTagName("联系方式");//获得交通工具节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element elementNode=(Element)node;
elementNode.setAttribute("工具","手机/固定电话/小灵通");
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();
Transformer transformer=transFactory.newTransformer();
DOMSource domSource=new DOMSource(document);
File file=new File("Example12.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);
transformer.transform(domSource,xmlResult);
}
catch(Exception e){
System.out.println(e);
e.printStackTrace();
}
}
}
example15.java
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.dom.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
public class Example15{
public static void main(String args[]){
try{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("Example12.xml"));
Element root=document.getDocumentElement();
NodeList nodeList=root.getElementsByTagName("消费金额");//获得图书名称节点集合
int size=nodeList.getLength();
for(int k=0;k<size;k++){
Node node=nodeList.item(k);
if(node.getNodeType()==Node.ELEMENT_NODE){
Element ele=(Element)node;
Node ndl=ele.getFirstChild();
Text text=(Text)ndl;
text.appendData("元");
}
}
TransformerFactory transFactory=TransformerFactory.newInstance();
Transformer transformer=transFactory.newTransformer();
DOMSource domSource=new DOMSource(document);
File file=new File("Example12.xml");
FileOutputStream out=new FileOutputStream(file);
StreamResult xmlResult=new StreamResult(out);
transformer.transform(domSource,xmlResult);
}
catch(Exception e){
System.out.println(e);
}
}
}
example1
<?xml version="1.0" encoding="GB2312"?>
<学生信息表>
<!--this is an example-->
<学生>
<姓名>
<姓>刘</姓>
<名字>海松</名字>
</姓名>
<性别>男</性别>
<班级 学号="21">08211</班级>
<出生日期>
<日>24</日>
<月>11</月>
<年>1977</年>
</出生日期>
</学生>
<学生>
<姓名>
<姓>刘</姓>
<名字>红霞</名字>
</姓名>
<性别>女</性别>
<班级 学号="15">08211</班级>
<出生日期>
<日>17</日>
<月>10</月>
<年>1983</年>
</出生日期>
</学生>
</学生信息表>
SimpleResponse
<?xml version="1.0" encoding="GB2312"?>
<提示>
<被提示>刘红霞</被提示>
<提示者>刘海松</提示者>
<标题>周末</标题>
<内容>不用忘了去人民公园玩呀</内容>
</提示>
test.html
<html>
<body>
<script type="text/javascript">
if (window.ActiveXObject) { // 对IE浏览器
var doc=new ActiveXObject("Microsoft.XMLDOM");
doc.async="false";
doc.load("SimpleResponse.xml");
}
else {// 对Mozilla, Firefox, Opera等浏览器
var parser=new DOMParser();
var doc=parser.parseFromString("SimpleResponse.xml","text/xml");
}
var x=doc.documentElement;
for (i=0;i<x.childNodes.length;i++)
{
document.write(x.childNodes[i].nodeName);
document.write("=");
document.write(x.childNodes[i].childNodes[0].nodeValue);
document.write("<br />");
}
</script>
</body>
</html>
图书列表
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<图书列表>
<图书 ISBN="978-7-302-15488-4">
<名称>XML实践教程</名称>
<作者>王峰</作者>
</图书>
<图书 ISBN="7-302-12591-0">
<名称>JSP从入门到精通</名称>
<作者>刘海松</作者>
</图书>
<图书 ISBN="978-7-302-14337-6">
<名称>Java实践教程</名称>
<作者>李章帅</作者>
</图书>
</图书列表>



