NLP(五)
训练数据中出现了没见过的数据
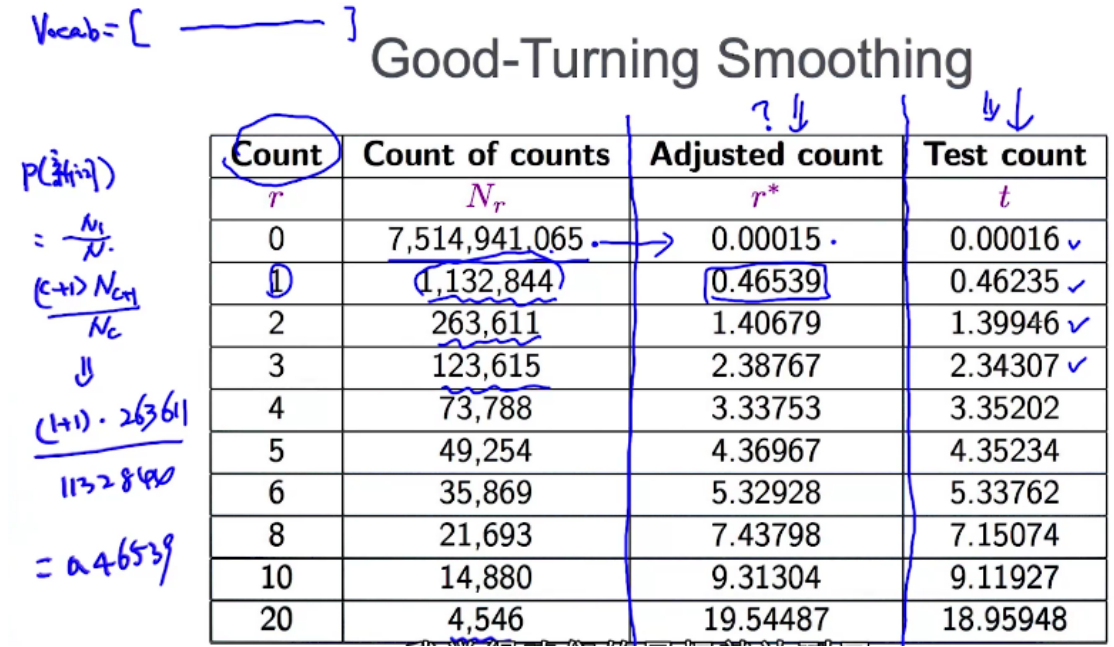
Good-Turning Smoothing
假设你在钓鱼,已经抓到了18只鱼:10条鲤鱼,3条黑鱼,2条刀鱼,1条鲨鱼,1条草鱼,1条鳗鱼......
下一个钓到的鱼是鲨鱼的概率?
18条鱼中有一条鲨鱼,1/18
下一条鱼是新鱼种(之前没出现过)的概率是多少?
近似的方法,用目前为止钓到一条的鱼来去近似未来新鱼种的概率。钓到1条鲨鱼,1条草鱼,1条鳗鱼,因此近似为3/18
既然如此,重新想一下,下一条抓到的鱼为鲨鱼的概率是多少?
第一题的时候,暗含了假定就是六种鱼占满了整个概率空间,概率相加为1,第二题我们扩充了新鱼种,因此六种鱼概率相加小于1,抓到鲨鱼的概率小于1/18


c草鱼出现了几次,出现了1次,c=1
N总共出现的个数
可以根据自己的数据和词典构建一个表
使用语言模型生成句子
语言模型是生成模型
根据该模型可以生成新的数据
词库,经过语言模型的训练后,得出了每个单词的概率

生成句子
一个一个单词的选,6次循环后可能是
![]()
也有可能恰好生成
![]()
都是随机的,不考虑上下文
Bigram
矩阵,最后一列是终止符号
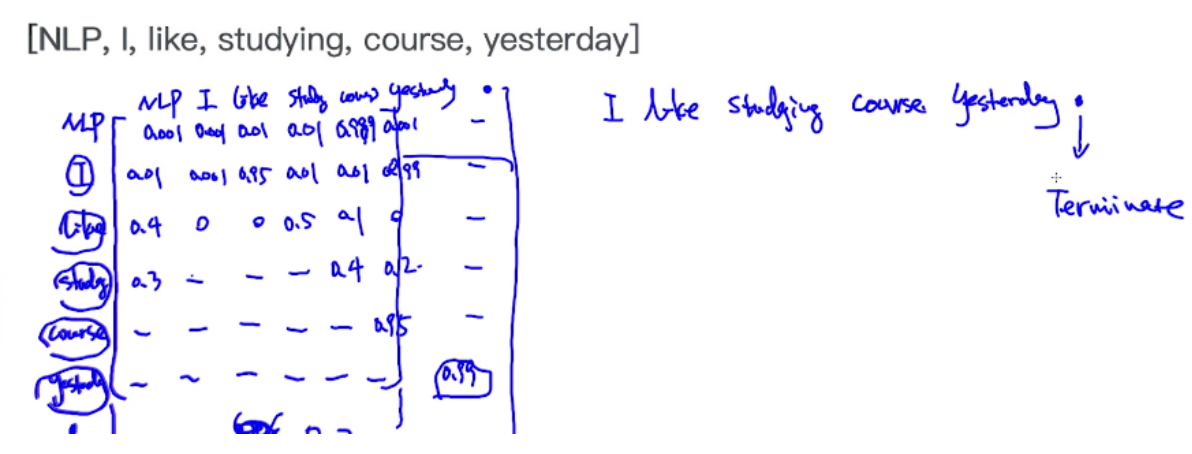
假定第一个单词I,第二个单词去I这行里寻找概率最大的,是like,然后去like行里找概率大的,studying


 浙公网安备 33010602011771号
浙公网安备 33010602011771号