Python爬虫 更新中
基础
一、环境配置
查看已安装的包
pip freeze
导出
pip freeze >requirements.txt
安装
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --ignore-installed
PYTHONPATH
PYTHONPATH是Python搜索路径,默认我们import的模块都会从PYTHONPATH里面寻找
我们可以将我们项目的目录放入到该变量中去,这样就可以导入我们项目中自己的包了
export PYTHONPATH=$PYTHONPATH:/bigdata/spider/src
二、正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
原子
原子是正则表达式中最基本的组成单元,每个正则表达式中至少包含一个原子。常见的原子类型有:
- 普通字符
- 非打印字符 即pattern中可以包含换行符和制表符
- 通用字符
- 原子表
常用通用字符
| 通用字符 | 描述 |
|---|---|
| \w | 匹配字母、数字、下划线 |
| \W | 匹配除字母、数字、下划线外任意字符 |
| \d | 匹配十进制数字,等价于[0-9] |
| \D | 匹配任意非十进制数字 |
| \s | 匹配空白字符 |
| \S | 匹配非空白字符 |
原子表
用中括号把多个原子括起来组成一个表,各原子地位平等。
| 举例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| [0-9] | 匹配匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^0-9] | 匹配除了数字外的字符 |
元字符
正则表达式中有一些特殊含义的字符
| 元字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| ^ | 在原子表中是非,不在原子表中表示匹配开始位置 |
| $ | 匹配结束位置 |
| * | 0次、1次或多次重复前面的原子 |
| ? | 0次或1次 |
| + | 1次或多次 |
| {n} | 恰好n次 |
| {n,} | 至少n次 |
| {n,m} | 至少n次,至多m次 |
| | | 或 |
| () | 匹配括号内的表达式,一些情况下也表示组 |
贪婪模式和懒惰模式:默认是贪婪模式,即尽可能的多匹配,我们可以用?变为懒惰模式。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式 \b
引用网上一段话:
\b 是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是 \b 并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w。
很多人不怎么理解正则中的 \b 含义,看到上面一段话后,很多人还是不怎么理解 \b 究竟是怎样的一个“位置”。
今天就来说说我的理解。
什么是位置
It's a nice day today.
'I' 占一个位置,'t' 占一个位置,所有的单个字符(包括不可见的空白字符)都会占一个位置,这样的位置我给它取个名字叫“显式位置”。
注意:字符与字符之间还有一个位置,例如 'I' 和 't' 之间就有一个位置(没有任何东西),这样的位置我给它取个名字叫“隐式位置”。
“隐式位置”就是 \b 的关键!通俗的理解,\b 就是“隐式位置”。
此时,再来理解一下这句话:
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w。
我用我的话来翻译一下这句话:
“隐式位置” \b,匹配这样的位置:它的前一个“显式位置”字符和后一个“显式位置”字符不全是 \w。
此刻,有没有一种豁然开朗的感觉?有么有?有么有?有么有?
实例讲解
就用 "It's a nice day today." 举例说明:
正确的正则:\bnice\b
分析:第一个 \b 前面一个字符是空格,后面一个字符是 'n',不全是 \w,所以可以匹配出 'n' 是一个单词的开头。第二个 \b 前面一个字符是 'e',后面一个字符是空格,不全是 \w,可以匹配出 'e' 是一个单词的结尾。所以,合在一起,就能匹配出以 'n' 开头以 'e' 结尾的单词,这里就能匹配出 "nice" 这个单词。
错误的正则:a\bnice
分析:我见过有人类似于这样来写正则,想要达到的目的是匹配出上一个单词以 'a' 结尾,下一个单词以 'n' 开头的部分,这里想匹配出 "a nice"。但是这个正则表达的可不是这个目的,\b 前面是字符 'a',后面是字符 'n',两个都是“显式字符”,显然违背了 \b 的含义,所以这就是个错误的表达式,匹配不出任何东西。想要匹配出 "a nice",正确的正则写法是:a\b.\bnice(不能换行)
模式修正符
模式修正符
| 模式修正符 | 描述 |
|---|---|
| re.I | 匹配时忽略大小写 |
| re.M | 多行匹配 |
| re.L | 本地化识别 |
| re.U | unicode |
| re.S | 让.匹配包括多行 |
| \S | 匹配非空白字符 |
re模块常用函数
re.match()
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例
#!/usr/bin/python import re print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
结果
(0, 3)
None
#!/usr/bin/python3 import re line = "Cats are smarter than dogs" # .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符 matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj: print ("matchObj.group() : ", matchObj.group()) print ("matchObj.group(1) : ", matchObj.group(1)) print ("matchObj.group(2) : ", matchObj.group(2)) else: print ("No match!!")
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
re.search()
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
#!/usr/bin/python3 import re print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
结果
(0, 3)
(11, 14)
#!/usr/bin/python3 import re line = "Cats are smarter than dogs" searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj: print ("searchObj.group() : ", searchObj.group()) print ("searchObj.group(1) : ", searchObj.group(1)) print ("searchObj.group(2) : ", searchObj.group(2)) else: print ("Nothing found!!")
结果
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter
re.sub()
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
#!/usr/bin/python3 import re phone = "2004-959-559 # 这是一个电话号码" # 删除注释 num = re.sub(r'#.*$', "", phone) print ("电话号码 : ", num) # 移除非数字的内容 num = re.sub(r'\D', "", phone) print ("电话号码 : ", num)
以上实例执行结果如下:
电话号码 : 2004-959-559
电话号码 : 2004959559
re.compile()
compile函数用于编译正则表达式,生成一个Pattern对象,Pattern对象有一系列的方法,常用的有:
- match(string[, pos[, endpos]])方法
- search(string[, pos[, endpos]])方法
- findall(string[, pos[, endpos]])方法
- finditer(string[, pos[, endpos]])方法
- split(string[, maxsplit])方法
- sub(repl, string[, count])方法
match(string[, pos[, endpos]])
如果没有指定pos和endpos,默认为0和len(string),即match函数将会从头部(左侧第一个字符)开始进行匹配,若匹配成功将返回Match对象,没有匹配成功,则返回None。
search(string[, pos[, endpos]])
与match的差别是可以从任何地方开始,只要待匹配的字符串中有可匹配对象,就会匹配成功,返回Match对象。也是只匹配一次。
上面的方法只匹配一次,如果我们想把字符串中所有匹配的情况都找出来该怎么办办呢?我们可以使用findall(string,[, pos[, endpos]]),findall会找到所有能够匹配的结果,结果是以列表形式返回的所有子串。
findall中的pattern用小括号,会只返回小括号中的匹配的东西,形成元组列表
import re a = "123abc456899opopo" pat = '12(.*?)4(.*?)po' res = re.compile(pat).findall(a) print(res)
结果是:
[('3abc', '56899o')]
split(string[, maxsplit])
split(string[, maxsplit])
split函数根据能够匹配的子串来分割字符串,结果以列表形式返回。
import re p = re.compile(r'a') res = p.split('abcadeacd') print(res)
结果是:
['', 'bc', 'de', 'cd']
‘a’被去除,’a’左右两侧的子串被装进列表中返回。
分组
https://blog.csdn.net/SeeTheWorld518/article/details/49302829
https://www.jianshu.com/p/5ce8100d30a0
三、字符编码
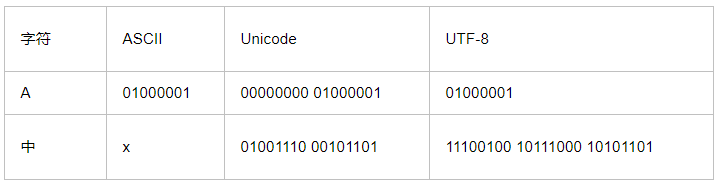
ASCII、Unicode和UTF-8的关系
如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
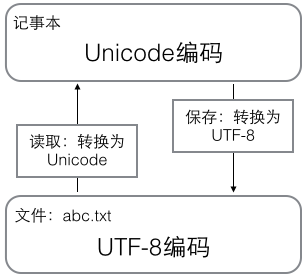
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
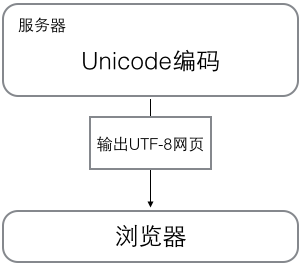
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python 3版本中,字符串是以Unicode编码的
>>> '\u4e2d\u6587' '中文' >>> '中文' '中文'
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii') b'ABC' >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' >>> '中文'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
str—>encode()—>byte
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii') 'ABC' >>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') '中文'
bytes—>decode()—>str
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8') Traceback (most recent call last): ... UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
你眼前看到字符,都是在内存中的,保存到磁盘中的文件只是一堆二进制,在你打开文件的瞬间,这堆二进制进入内存,转为字符呈现在你的眼前。二进制和字符之间显然是有某种规则的,在python3中的规则默认是Unicode。
python 3.x默认的字符编码是unicode,默认的文件编码是utf-8。
在python2文件中,如果你打开一个文件,它默认认为是ASCII编码的,字符编码也是ASCII,它会去直接把那堆二进制去向ASCII匹配,如果有中文根本匹配不到,于是会报错。经常在文件开头看到“ #-*-coding:utf-8 -*- ”语句,它的作用是告诉python解释器此.py文件是utf-8编码,需要用utf-8的编码去读取这个.py文件。
如果是python3文件,你打开一个文件,它默认是utf-8,字符编码是unicode,它会根据utf-8的规则解读这堆二进制,正常解读了就转为遵守Unicode规则的另一堆二进制,然后根据unicode的映射关系就能正常展示在你眼前。
爬虫中经常见到乱码,网站服务器会向你发一堆二进制(bytes),这堆二进制遵守它们的编码规则,如utf-8,而你的python3接收到后总时要转为Unicode后才呈现给你的,如果你不告诉python3接收到的数据使用了什么编码,它就没法进行转换为Unicode的操作,往往会导致乱码。
比如,你好 你收到的是 \xe4\xbd\xa0\xe5\xa5\xbd ,这是utf-8编码,如果被被认为使用ASCII编码,就会用ASCII的方式解读数据去转为Unicode,自然解读不了出错,你要告诉python编码方式是utf-8,encoding就是告诉python使用的编码格式
resp = requests.get(url) resp.encoding = 'utf-8'
在python中,把Unicode转为其他编码格式叫编码encode,把其他编码格式转为Unicode叫解码decode
其实不管是Unicode和其他编码都是二进制,编码格式只是规则,但Unicode是默认编码,也就是说如果你的二进制符合Unicode格式他就会在你眼前显示成为字符,字符串都是Unicode,如果其他格式不会以字符的形式显示在你眼前,你可以看它的二进制的形式,如 b' \xe4\xbd\xa0\xe5\xa5\xbd',你不加b还是Unicode,还是普通字符串。其他编码格式都是bytes。
如,你读取一张图片,要用参数rb,以二进制的形式读,如果你不加,它就用默认的文件存储编码格式给你转Unicode,会出错。
CMD默认是Windows系统默认编码(GBK),你用cmd读取文件的时候,如果用utf-8保存的,打开文件时要设置encoding=utf8。
四、Xpath
五、beautiful soup
六、urllib
python3 urllib.request.urlopen()访问HTTPS网站的出错解决办法
使用以下代码:
urllib.request.urlopen('https://www.******.org')
在请求时会验证证书,没有证书或证书有误会出现:
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
发现会报错,当使用urllib模块访问https网站时,由于需要提交表单,而python3默认是不提交表单的,所以这时只需在代码中加上以下代码即可:
import ssl ssl._create_default_https_context = ssl._create_unverified_context
跳过验证证书。
七、requests
八、操作数据库
pymysql
解决pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x8C\\xB8' for column 'headline' at row 1")
当使用Python对MySQL数据库进行操作时,我们可能会遇到这种错误,这是因为编码所引起的错误,我们必须确保MySQL中的数据库中的编码支持utf8格式,才能将正常的中文格式的字符串插入到MySQL中,我们必须要确保如下character_set_server的格式为utf8,因为将中文插入到MySQL中,主要需要使用的是该驱动
docker mysql
-
拉取官方镜像(我们这里选择5.7,如果不写后面的版本号则会自动拉取最新版)
docker pull mysql:5.7 # 拉取 mysql 5.7 docker pull mysql # 拉取最新版mysql镜像
-
检查是否拉取成功
$ sudo docker images
-
一般来说数据库容器不需要建立目录映射
sudo docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
- –name:容器名,此处命名为
mysql - -e:配置信息,此处配置mysql的root用户的登陆密码
- -p:端口映射,此处映射 主机3306端口 到 容器的3306端口
- –name:容器名,此处命名为
-
如果要建立目录映射
sudo docker run -p 3306:3306 --name mysql \ -v /usr/local/docker/mysql/conf:/etc/mysql \ -v /usr/local/docker/mysql/logs:/var/log/mysql \ -v /usr/local/docker/mysql/data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=123456 \ -d mysql:5.7
- -v:主机和容器的目录映射关系,":"前为主机目录,之后为容器目录
-
检查容器是否正确运行
docker container ls
- 可以看到容器ID,容器的源镜像,启动命令,创建时间,状态,端口映射信息,容器名字
连接mysql
进入docker本地连接mysql客户端
sudo docker exec -it mysql bash mysql -uroot -p123456
连接池
import pymysql from DBUtils.PooledDB import PooledDB, SharedDBConnection ''' 连接池 ''' class MysqlPool(object): def __init__(self): self.POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=5, # 链接池中最多闲置的链接,0和None不限制 maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='root', database='test', charset='utf8' ) def __new__(cls, *args, **kw): ''' 启用单例模式 :param args: :param kw: :return: ''' if not hasattr(cls, '_instance'): cls._instance = object.__new__(cls) return cls._instance def connect(self): ''' 启动连接 :return: ''' conn = self.POOL.connection() cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) return conn, cursor def connect_close(self,conn, cursor): ''' 关闭连接 :param conn: :param cursor: :return: ''' cursor.close() conn.close() def fetch_all(self,sql, args): ''' 批量查询 :param sql: :param args: :return: ''' conn, cursor = self.connect() cursor.execute(sql, args) record_list = cursor.fetchall() self.connect_close(conn, cursor) return record_list def fetch_one(self,sql, args): ''' 查询单条数据 :param sql: :param args: :return: ''' conn, cursor = self.connect() cursor.execute(sql, args) result = cursor.fetchone() self.connect_close(conn, cursor) return result def insert(self,sql, args): ''' 插入数据 :param sql: :param args: :return: ''' conn, cursor = self.connect() row = cursor.execute(sql, args) conn.commit() self.connect_close(conn, cursor) return row
九、无头浏览器
火狐
Firefox全历史版本下载:http://ftp.mozilla.org/pub/mozilla.org//firefox/releases/
驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/
selenium3.5
firefox 62
火狐关闭自动更新,上面的配置升级到最新版本会报错
linux版
下载依赖
yum install xorg-x11-server-Xvfb bzip gtk3
下载上面版本对应linux的火狐和驱动,解压
yum install bzip2 tar jxvf firefox-62.0.tar.bz2
root@JD bigdata]# ln -s /bigdata/firefox/firefox /usr/bin/firefox [root@JD bigdata]# ln -s /bigdata/geckodriver /usr/bin/geckodriver
linux下将项目模块搜索路径放到环境变量中去
export PYTHONPATH=$PYTHONPATH:/bigdata/spider/src
十、scrapy
定时任务
写个后台运行的脚本一直循环运行,然后每次循环sleep 20s
while true ;do command sleep 20 //间隔秒数 done
crontab
linux内置的cron进程能帮我们实现这些需求,cron搭配shell脚本,非常复杂的指令也没有问题。
cron介绍
我们经常使用的是crontab命令是cron table的简写,它是cron的配置文件,也可以叫它作业列表,我们可以在以下文件夹内找到相关配置文件。
- /var/spool/cron/ 目录下存放的是每个用户包括root的crontab任务,每个任务以创建者的名字命名
- /etc/crontab 这个文件负责调度各种管理和维护任务。
- /etc/cron.d/ 这个目录用来存放任何要执行的crontab文件或脚本。
- 我们还可以把脚本放在/etc/cron.hourly、/etc/cron.daily、/etc/cron.weekly、/etc/cron.monthly目录中,让它每小时/天/星期、月执行一次。
启动、重启、关闭、重新加载、查看状态
/bin/systemctl start crond /bin/systemctl stop crond /bin/systemctl restart crond /bin/systemctl reload crond /bin/systemctl status crond
crontab -u //设定某个用户的cron服务 crontab -l //列出某个用户cron服务的详细内容 crontab -r //删除某个用户的cron服务 crontab -e //编辑某个用户的cron服务 crontab -i //打印提示,输入yes等确认信息 /var/spool/cron/root (以用户命名的文件) 是所有默认存放定时任务的文件 /etc/cron.deny 该文件中所列出用户不允许使用crontab命令 /etc/cron.allow 该文件中所列出用户允许使用crontab命令,且优先级高于/etc/cron.deny /var/log/cron 该文件存放cron服务的日志
看日志
cat /var/log/cron
# For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed
定时任务的每段为:分,时,日,月,周,用户,命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
*:表示任意时间都,实际上就是“每”的意思。可以代表00-23小时或者00-12每月或者00-59分
-:表示区间,是一个范围,00 17-19 * * * cmd,就是每天17,18,19点的整点执行命令
,:是分割时段,30 3,19,21 * * * cmd,就是每天凌晨3和晚上19,21点的半点时刻执行命令
/n:表示分割,可以看成除法,*/5 * * * * cmd,每隔五分钟执行一次
Linux定时任务,执行shell文件失败问题&&mailed 73 bytes of output but got status 0x004b#012报错
出现mailed 73 bytes of output but got status 0x004b#012这个问题,这是为什么呢?
通过查看maillog,发现了下面的报错
cat /var/log/maillog
postfix/sendmail[8087]: fatal: parameter inet_interfaces: no local interface found for ::1这是什么错误了(参数inet_interfaces:未找到::1的本地接口),又经过一番查找,终于找到了解决办法
将/etc/postfix/main.cf文件中inet_interfaces值改为all
vim /etc/postfix/main.cf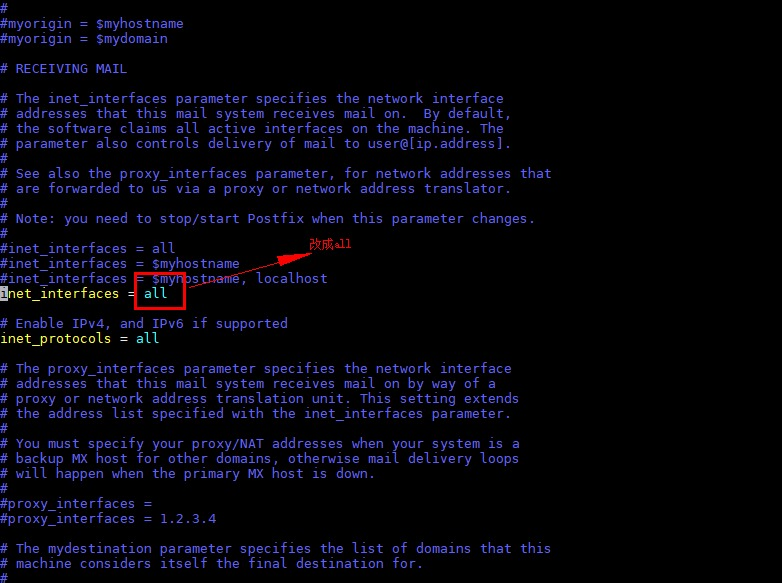
crontab与环境变量
crontab有自己的环境变量
(base) [root@node03 spider]# cat /etc/crontab SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root # For details see man 4 crontabs # Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed
我们可以在调用定时任务的时候导入我们的环境变量:
(base) [root@node03 spider]# crontab -l 15,35,55 * * * * source /root/.bashrc && /bin/sh /bigdata/spider/src/com/aidata/spider.sh > /bigdata/sp.log 2>&1
在 Linux 系统中:标准输入(stdin)默认为键盘输入;标准输出(stdout)默认为屏幕输出;标准错误输出(stderr)默认也是输出到屏幕(上面的 std 表示 standard)。在 BASH 中使用这些概念时一般将标准输出表示为 1,将标准错误输出表示为 2。
如:
nohup java -jar xxxx.jar >/dev/null 2>&1 &/dev/null 代表空设备文件,> 代表重定向到哪里,>/dev/null 2>&1就是不输出任何信息到终端,说白了就是不显示任何信息。
1 表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于"1>/dev/null"
2 表示stderr标准错误
& 表示等同于的意思,2>&1,表示2的输出重定向等同于1nohup ./mqnamesrv >/home/cxb/mqnamesrv.out 2>&1 &
即标准输出到mqnamesrv.out中,接着,标准错误输出重定向等同于标准输出,输出到同一文件中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号