SparkSQL
一、概述
组件
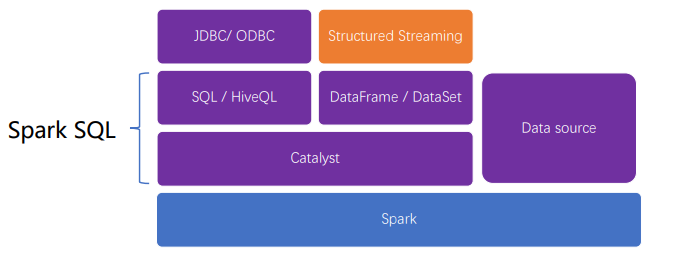

运行机制

转 SparkSQL – 从0到1认识Catalyst https://blog.csdn.net/qq_36421826/article/details/81988157
深入研究Spark SQL的Catalyst优化器(原创翻译)
更高效

查询优化

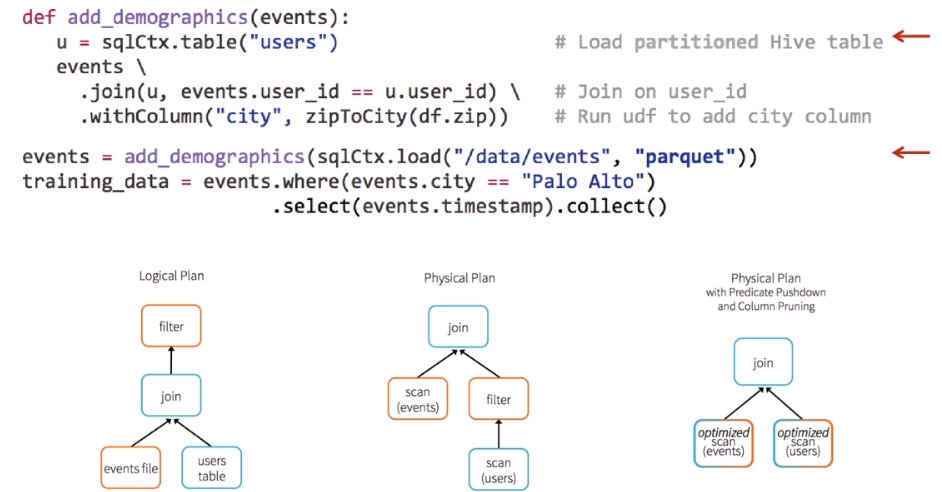
优化:把filter提前
数据源优化

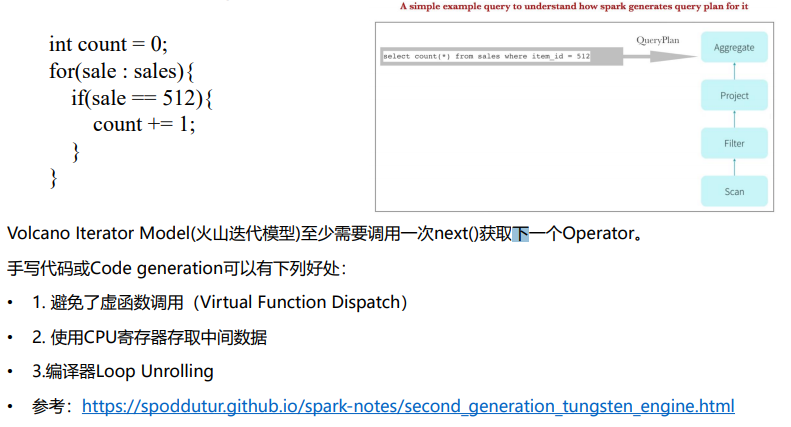
编译优化 Code generation

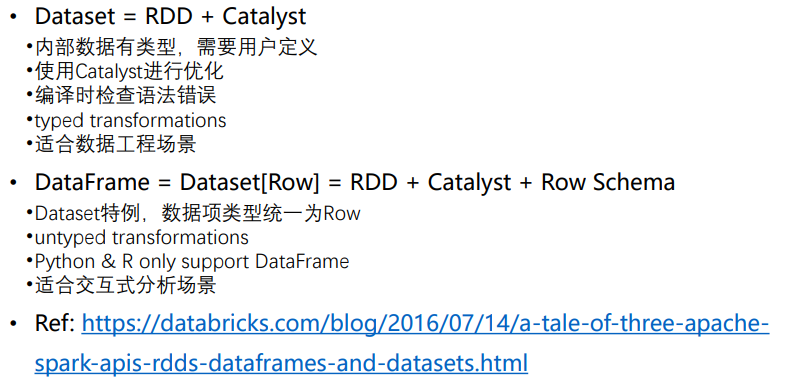
DataSet和DataFrame

数据源

Parquet文件
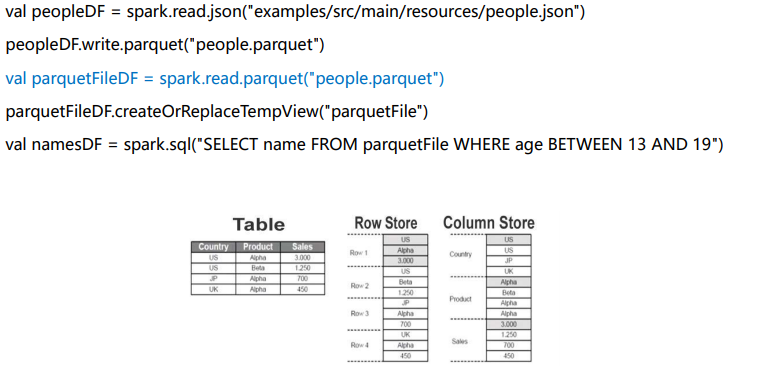
Json文件

读取Hive中文件

外部数据源spark.read.format

二、程序设计
常规流程

API:SQL与DataFrame DSL


统计分析内容大小-全部内容大小,日志条数,最小内容大小,最大内容大小
package org.sparkcourse.log import org.apache.spark.sql.{Row, SparkSession} object LogAnalyzerSQL { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("Log Analyzer") .master("local") .getOrCreate() import spark.implicits._ val accessLogs = spark .read .textFile("data/weblog/apache.access.log") .map(ApacheAccessLog.parseLogLine).toDF() accessLogs.createOrReplaceTempView("logs") // 统计分析内容大小-全部内容大小,日志条数,最小内容大小,最大内容大小 val contentSizeStats: Row = spark.sql("SELECT SUM(contentSize), COUNT(*), MIN(contentSize), MAX(contentSize) FROM logs").first() val sum = contentSizeStats.getLong(0) val count = contentSizeStats.getLong(1) val min = contentSizeStats.getLong(2) val max = contentSizeStats.getLong(3) println("sum %s, count %s, min %s, max %s".format(sum, count, min, max)) println("avg %s", sum / count) spark.close() } }
ApacheAccessLog
package org.sparkcourse.log import sun.security.x509.IPAddressName case class ApacheAccessLog(ipAddress: String, clientIdentd: String, userId: String, dateTime: String, method: String, endpoint: String, protocol: String, responseCode: Int, contentSize: Long){ } object ApacheAccessLog { // 64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846 val PATTERN = """^(\S+) (\S+) (\S+) \[([\w:/]+\s+\-\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\d+)""".r def parseLogLine(log: String): ApacheAccessLog = { log match { case PATTERN(ipAddress, clientIdentd, userId, dateTime, method, endpoint, protocol, responseCode, contentSize) => ApacheAccessLog(ipAddress, clientIdentd, userId, dateTime, method, endpoint, protocol, responseCode.toInt, contentSize.toLong) case _ => throw new RuntimeException(s"""Cannot parse log line: $log""") } }
String 的 .r 方法 将字符串转为正则表达式
方式一: 通过case class创建DataFrames(反射)
TestDataFrame1.scala
package com.bky // 隐式类的导入 // 定义case class,相当于表结构 case class Dept(var id:Int, var position:String, var location:String) // 需要导入SparkSession这个包 import org.apache.spark.sql.SparkSession /** * 方式一: 通过case class创建DataFrames(反射) */ object TestDataFrame1 { def main(args: Array[String]): Unit = { /** * 直接使用SparkSession进行文件的创建。 * 封装了SparkContext,SparkConf,SQLContext, * 为了向后兼容,SQLContext和HiveContext也被保存了下来 */ val spark = SparkSession .builder() //构建sql .appName("TestDataFrame1") // 设置文件名 .master("local[2]") // 设置executor .getOrCreate() //获取或创建 import spark.implicits._ // 隐式转换 // 将本地的数据读入RDD,将RDD与case class关联 val deptRDD = spark.read.textFile("/Users/hadoop/data/dept.txt") .map(line => Dept(line.split("\t")(0).toInt, line.split("\t")(1), line.split("\t")(2).trim)) // 将RDD转换成DataFrames(反射) val df = deptRDD.toDF() // 将DataFrames创建成一个临时的视图 df.createOrReplaceTempView("dept") // 使用SQL语句进行查询 spark.sql("select * from dept").show() } }精简版 TestDataFrame1.scala
package com.bky import org.apache.spark.sql.SparkSession object TestDataFrame1 extends App { val spark = SparkSession .builder() //构建sql .appName("TestDataFrame1") .master("local[2]") .getOrCreate() import spark.implicits._ val deptRDD = spark.read.textFile("/Users/hadoop/data/dept.txt") .map(line => Dept(line.split("\t")(0).toInt, line.split("\t")(1), line.split("\t")(2).trim)) val df = deptRDD.toDF() df.createOrReplaceTempView("dept") spark.sql("select * from dept").show() } case class Dept(var id:Int, var position:String, var location:String)
方式二:通过创建structType创建DataFrames(编程接口)
TestDataFrame2.scala
package com.bky import org.apache.spark.sql.types._ import org.apache.spark.sql.{Row, SparkSession} /** * * 方式二:通过创建structType创建DataFrames(编程接口) */ object TestDataFrame2 extends App { val spark = SparkSession .builder() .appName("TestDataFrame2") .master("local[2]") .getOrCreate() /** * 将RDD数据映射成Row,需要导入import org.apache.spark.sql.Row */ import spark.implicits._ val path = "/Users/hadoop/data/dept.txt" val fileRDD = spark.read.textFile(path) val rowRDD= fileRDD.map(line => { val fields = line.split("\t") Row(fields(0).toInt, fields(1), fields(2).trim) }) // 创建StructType来定义结构 val innerStruct = StructType( // 字段名,字段类型,是否可以为空 StructField("id", IntegerType, true) :: StructField("position", StringType, true) :: StructField("location", StringType, true) :: Nil ) val df = spark.createDataFrame(innerStruct) df.createOrReplaceTempView("dept") spark.sql("select * from dept").show() }
方式三:通过json文件创建DataFrames
TestDataFrame3.scala
package com.bky import org.apache.spark.sql.SparkSession /** * 方式三:通过json文件创建DataFrames */ object TestDataFrame3 extends App { val spark = SparkSession .builder() .master("local[2]") .appName("TestDataFrame3") .getOrCreate() val path = "/Users/hadoop/data/test.json" val fileRDD = spark.read.json(path) fileRDD.createOrReplaceTempView("test") spark.sql("select * from test").show() }
统计每种返回码的数量
package org.sparkcourse.log import org.apache.spark.sql.{Row, SparkSession} object LogAnalyzerSQL { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("Log Analyzer") .master("local") .getOrCreate() import spark.implicits._ val accessLogs = spark .read .textFile("data/weblog/apache.access.log") .map(ApacheAccessLog.parseLogLine).toDF() accessLogs.createOrReplaceTempView("logs") // 统计每种返回码的数量. val responseCodeToCount = spark.sql("SELECT responseCode, COUNT(*) FROM logs GROUP BY responseCode LIMIT 100") .map(row => (row.getInt(0), row.getLong(1))) .collect() responseCodeToCount.foreach(print(_)) } }
统计哪个IP地址访问服务器超过10次
package org.sparkcourse.log import org.apache.spark.sql.{Row, SparkSession} object LogAnalyzerSQL { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("Log Analyzer") .master("local") .getOrCreate() import spark.implicits._ val accessLogs = spark .read .textFile("data/weblog/apache.access.log") .map(ApacheAccessLog.parseLogLine).toDF() accessLogs.createOrReplaceTempView("logs") // 统计哪个IP地址访问服务器超过10次 val ipAddresses = spark.sql("SELECT ipAddress, COUNT(*) AS total FROM logs GROUP BY ipAddress HAVING total > 10 LIMIT 100") .map(row => row.getString(0)) .collect() ipAddresses.foreach(println(_)) } }
查询访问量最大的访问目的地址
package org.sparkcourse.log import org.apache.spark.sql.{Row, SparkSession} object LogAnalyzerSQL { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("Log Analyzer") .master("local") .getOrCreate() import spark.implicits._ val accessLogs = spark .read .textFile("data/weblog/apache.access.log") .map(ApacheAccessLog.parseLogLine).toDF() accessLogs.createOrReplaceTempView("logs") // 查询访问量最大的访问目的地址 val topEndpoints = spark.sql("SELECT endpoint, COUNT(*) AS total FROM logs GROUP BY endpoint ORDER BY total DESC LIMIT 10") .map(row => (row.getString(0), row.getLong(1))) .collect() topEndpoints.foreach(println(_)) } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号