python 集合详解
字符串
一个个字符组成的有序的序列,时字符的集合 使用单引,双引,三引 引住的字符序列 字符时不可变的对象
bytes定义
bytes不可变字节序列 使用b前缀定义 只允许基本ASCII使用字符形式 支持索引 返回对应的数,int类型
bytearray定义

字节数组 可变 append 可在尾部追加元素 insert 在指定索引位置插入元素 extend 将一个可迭代的整数集合追加到当前bytearray pop(index=-01) 从指定索引上移除元素,默认从尾部移除 remove(value) 找到第一个value移除,找不到抛出VlaueError异常 上述方法若需要使用int类型,值在【0,255】 clear()清空bytearray reverse()反转bytearray ,就地修改 编码: 字符串按照不同的字符集编码encode返回字节序列bytes 字节序列按照不同的字符集解码decode返回字符串
线性结构
可迭代 for...in len可以获取其长度 可以通过索引访问 可以切片
切片
通过索引区间访问线性结构的一段数据 sequence[start:stop],表示返回[start,stop]区间的子序列 支持负索引 strat为0可以省略 stop为末尾,可以省略 超过上界(右边界),取到末尾;超过下届(左边界),取其开头 strat一定要在stop的左边 [:] 表示从头到尾,全部元素被取出,等效于copy( )方法
封装和结构

解构
把线性结构的元素解开,并顺序的赋给其他变量 左边接纳的变量数要和右边解开的数目一致
python3 的解构
使用 *变量名接收 不能单独使用
被 *变量名 收集后组成一个列表
丢弃变量
不成文的约定,不是标准 如果不关心一个变量,可以定位这个变量的名字为__ __是一个合法的标识符,也可以作为一个有效的数量使用,但是定义成下划线就是希望不被使用,除非明确知道这个数据需要使用
_这变量本身无任何语义,没有任何可读性,
python中有很多库都是用这个变量,使用十分广泛,在不明确变量作用域的情况下,使用_和库中的_冲突
练习
lst=list(range(10)) 取出第二个,第四个,倒数第二个
_,sec,_,F,*_,n,_=lst
从lst=[1,(2,3,4),5]中,提取4出来
_,(*_,a),_=lst
从JAVA_HOME=/usr/bin,返回变量名和路径
s='JAVA_HOME=/usr/bin'
name,_path=s.prtition('=')
总结:
解构,是python中提供的很好的功能,可以方便的提取复杂数据解构的值
配合_的使用,会更加便利
set
可变的,无序的,不重复的元素的集合
set是可迭代的
set可以用来去重
set的元素是要求必须可以hash的
目前已学过的不可hash的类型有 list、set
元素不可以被索引
set增加
add(value)
增加一个元素到set中
如果元素存在,什么都不做
update(*others)
合并其他元素到set集合中来
参数others必须是可迭代对象
就地修改
set删除
remove(elem)
从set中移除一个数
元素不存在,会抛出KeyError错误: 通过hash值查找,直接删除对应hash值的数
discard(elem)
从set中移除一个元素
元素不存在,不会抛错误
pop( )-->item
不可以删除指定数值
移除并返回任意的元素,
空集返回KeyError异常
clear( )
移除所有元素
set的修改和查询
修改:
要么删除,要么加入新的元素,没有修改
查询:
非线性结构,无法索引
遍历:
可迭代所有元素
成员运算符:
in和not in 可以判断元素是否在set中
set和线性结构
线性结构的查询时间复杂度都是O(n),随着数据规模增大,耗时增加
ser、dict等结构,内部使用hash值作为key,时间复杂度可以为O(1),查询时间和数据规模无关
可hash
数值型 int、float、complex
布尔型 True、False
字符串 string、bytes
tuple
None
以上都是不可变类型,成为可hash类型,hashable
set的元素必须是可hash的
集合
基本概念
全集
所有元素的集合,如实数集,所有实数组成的集合就是全集
子集
一个集合A所有元素都在另一个集合B内,A是B的子集,B是A的超集
真子集和真超集
A是B的子集,且A不等于B,A就是B的真子集,B是A的真超集
并集: 多个集合合并的结果
交集:多个集合的公共部分
差集: 集合中出去和其他集合公共部分
并集
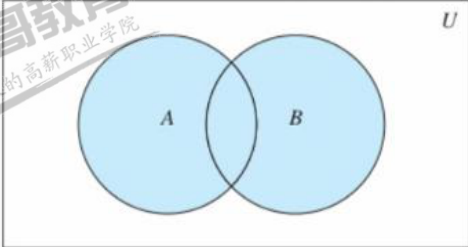
将两个集合A和B所有的元素合并到一起,组成的元素乘坐集合A与集合B的并集
比较运算: union(*others)
union用法:![]()
![]()
![复制代码]()
![]()
![复制代码]()
![复制代码]()
![]()
![]()
![]()
![复制代码]()
![复制代码]()
![]()
![]()
![]()
![复制代码]()
![复制代码]()
![]()
![]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()
![复制代码]()

返回和多个集合合并后的新集合(如图所示A与B的相交部分)、
”|“: union的代表符号
update(*others): 和多个集合合并,就地修改
update的用法:
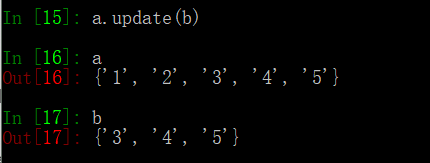
= : update的代表符号
交集:
集合A和B由所有属于A且属于B的元素组成的集合(如下图所示):
intersection(*others)
返回多个集合的交集(如下图所示):

& :intersection的代表符号
intersection_update(*others)
获取和多个集合的交集,并就地修改
&= :intersection_updated 的表示符号
差集
差集
集合A和B,由所有属于A且不属于B的元素组成的集合(如图所示):
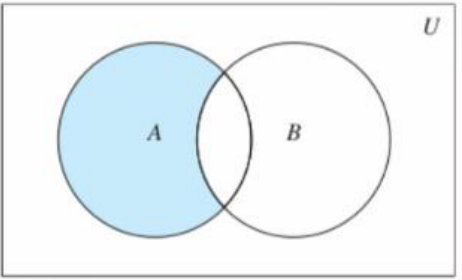
diffrernce(*others)的用法
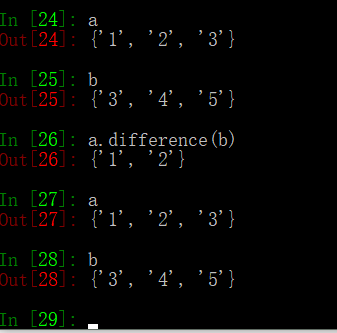
返回多个集合的差集
— : 表示为 difference的符号
difference_(update):
获取和多个集合的差集并就地修改
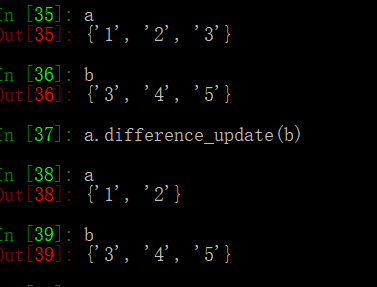
—= : 表示为difference_(update)的符号
对称差集
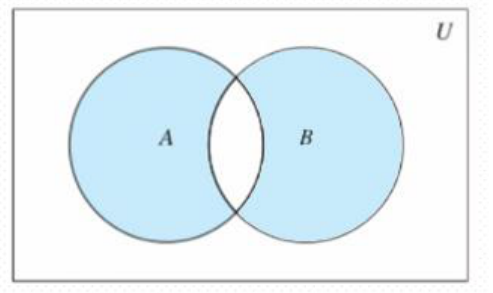
对称差集:
集合A和B,由所有不属于A和B的交集元素组成的集合,记作(A-B)U(B-A):
symmetric_differece(other)
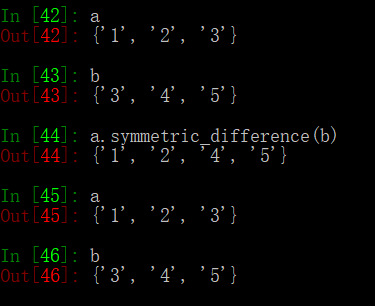
返回和另一个集合的差集
”^“ 表示为symmetric_differece的表示符号
symmetric_differece_update(other)

获取另一个集合的差集并就地修改
”^=“ 表示为symmetric_differece_update(other)的使用符号
issubset(other)、<=:
判断当前集合是否是另一个集合的子集
set1<set2:
判断set1是否是set2的真子集
issuperset(other)、>=
判断set1是否是set的真超集
isdisjoint(other)
当前集合和另一个集合没有交集;没有交集,返回True
集合练习:
共同好友;
你的好友A,B,C 他的好友C,B,D, 求共同好友:
交集问题: {'A','B','C'}.intersection({'B','C','D'})

微信群提醒:
XXX与群里其他人都不是微信朋友关系
并集:userid in (A|B|C|...)==FLASE, A , B , C等是好友的并集,用户ID不在这个并集中,说明他和任何人都不是朋友
权限判断:
有一个API,要求同时具备A,B,C权限才能访问,用户权限B,C,D,判断该用户能否访问该API
API集合为A,权限集合为P;A-P={},AP为空集,说明 P包含A
A.issubset(P)也行,A是P的子集
A&P=A也可以
有一个API,要求具备A,B,C任意一项权限就可访问,用户权限B,C,D ,判断该用户能否访问该API
一个总任务列表,储存所有任务,一个完成的任务列表。找出未完成的任务
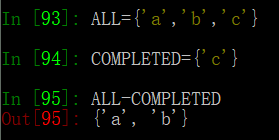
设所有的工作为ALL,已完成的工作为COMPLETED 用所有的减去已完成的得出未完成的
集合练习:
随机产生2组各个数字的列表,如下要求:
每个数字取值范围[10,20]
统计20个数字中,一共有多少个不同的数字?
2组中,不重复的数字有几个?分别是什么?
2组中,重复的数字有几个?分别是什么?

答案依次为:

字典
字典:
字典为 key-vlaue 键值对的数据的集合;字典是可变的,无序的,key不重复
字典的定义,初始化:
字典常用的用法为 : dict(**kwargs) 使用name=value 对一个字典初始化
dict(可迭代,**kwarg)使用可迭代对象和name=value对构造字典,不过可迭代对象的元素必须是一个二元结构
dict(mapping,**kwarg)使用一个字典构造另外一个字典
d={'a':10,'b':20,'c':None,'d':[1,2,3]}
字典元素的访问:
d[key]: 返回key对应的值value;key不存在抛KeyError异常
get(key,[,default]): 返回key对应的值value,key不存在返回缺省值,如果没有设置缺省值返回None
setdefault(key[,default]):返回key对应的值value,key不存在,添加kv对.值为default,并返回default,如果default没有设置,缺省为None
字典增加和修改:
d[key]=value :将key对应的值修改为value(新值),key不存在添加新的kv对
update([other])-->None:
使用另一个字典的kv对更新本字典;key不存在,就添加;key存在,覆盖已经存在的key对应的值;就地修改
字典删除:
pop(key[,default]):
key存在,移除它,并返回他的value
key不存在,返回给定的default
default未设置,key不存在则排除KeyError异常
popitem()
移除并返回一个任意的键值对
字典为空,抛出KeyError异常
clear() 清空字典
字典删除:
del语句
字典练习:

第二题:
import random
randomnumber=[]
countlist=[]
randomdict={}
sortlist=[]
for p in range(100):
randomnumber.append(random.randrange(-1000,1000))
countlist.append(randomnumber.count(randomnumber[p]))
randomdict[randomnumber[p]]=countlist[p]
for k,v in randomdict.items():
sortlist.append((k,v))
sortlist.sort()
print(sortlist)
输出结果:![]()
习题一:
nums=input('>>>')
count_list=[]
sort_list={}
sort_list1=[]
for i in range(len(nums)):
count_list.append(nums.count(nums[i]))
sort_list[nums[i]]=count_list[i]
for k,v in sort_list.items():
sort_list1.append((k,v))
print(sort_list1)
输出结果:

习题三:
import random
s1=[]
same_alpha=[]
count_list={}
diff_alpha=[]
alpha='abcdefghijklmnopqrstuvwxyz'
for _ in range(100):
s1.append(random.choice(alpha)+random.choice(alpha))
same_alpha.append(s1.count(s1[_]))
count_list[s1[_]]=same_alpha[_]
#进行排序
for k,v in count_list.items():
diff_alpha.append((k,v))
diff_alpha.sort(reverse=True)
print(diff_alpha)
输出结果为:
![]()
选择排序:
选择排序使用方法
简单选择排序:
属于选择排序,两两比较大小,找出最大值和最小值;被放在固定的位置,固定位置一般在某一端
结果分为升序和降序
降序:n个数由左至右,索引从0到-1,两两依次比较,并记录最大值,此轮所有数比较完毕,将最大数和索引0数比较,如果最大数就是索引1,不交换;第二轮由1开始比较,找到最大值,将它和索引1位置交换,如果他就在索引1则不叫唤,依次类推,每次左边都会固定下一个大数
升序:
和降序相反
简单排序总结:
简单排序需要 数据一轮轮比较,并在每一轮中发现极值
没有办法知道当前轮是否已经达到排序要求,但可以知道极值是否在目标索引位置上
遍历次数1,....,n-1和n(n-1)/2
时间复杂度为O(n的平方)
减少了交换次数,提高了效率,性能略好于冒泡法
选择排序练习:
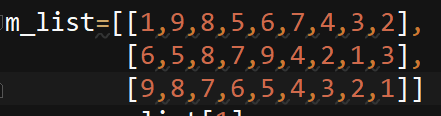
将上述列表第二列利用选择排序进行排序
m_list=[[1,9,8,5,6,7,4,3,2],
[6,5,8,7,9,4,2,1,3],
[9,8,7,6,5,4,3,2,1]]
nums = m_list[1]
length=len(nums)
print(nums)
for i in range(length):
maxindex=i
for j in range(i+1,length):
if nums[maxindex] < nums[j]:
maxindex = j
# print(nums)
if i != maxindex: #第二次判断两个索引是否相等,若相等则说明该值已是最大,无需进行下面的命令操作,否则则进行下面的程序
tmp = nums[maxindex] #将列表中最大的值赋给另一个参数
nums[maxindex]=nums[i] #将列表中maxindex索引的值刷新为i索引的值
nums[i]=tmp #将列表中i的索引的值刷新为tmp的最大值
print(nums)
输出结果为:

回顾之前所学知识,并以新的所学知识做一些以前的习题:
求杨辉三角的第5列的第4个值
m=5
k=4
traingle=[]
for i in range(m):
row=[1]
traingle.append(row)
for j in range(1,i):
if i == 0:
continue
row.append(traingle[i-1][j-1]+traingle[i-1][j])
row.append(1)
traingle.append(row)
print(traingle)
print(traingle[m-1][k-1])

习题二:
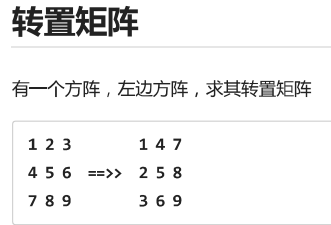
lst=[[1,2,3],[4,5,6],[7,8,9]]
for i in range(len(lst)): #依次循环3个列表
for j in range(i): #本次循环的是列表中的索引值
lst[i][j],lst[j][i]=lst[j][i],lst[i][j] #将列表的值进行交换
print(lst)
for k in lst: #重新排序
print(k)
输出结果为:

习题3:

firstlist=[[1,2,3],[4,5,6]] #创建一个包含两列数的列表
secondlist=[] #创建一个空列表
m=len(firstlist) #将第一个列表的长度输出给m
for i in range(m+1): #
secondlist.append([0]*m)#循环三次,并开辟3个介为0的子列表
print(secondlist)
print(firstlist)
for i in range(m): #
for j in range(m+1): #利用两层循环来读取索引上的数值
secondlist[j][i]=firstlist[i][j] # 将对应索引上的值进行交换
print(secondlist)
输出结果为:

习题三:
随机生成10个数字;
每个数字的取值范围不超过20
分别统计重复与不重复的数字有几个:
import random
nums=[]
for _ in range(10):
nums.append(random.randrange(21))
print('nums1={}'.format(nums))
print()
随机生成10个20以内的数字
————————————————————————
length=len(nums)
samenums=[]
diffnums=[]
states = [0]*length
for i in range(length):
flag=False
if states[i]==1:
continue
for j in range(i+1,length):
if states[j]==1:
continue
if nums[i]==nums[j]:
flag=True
states[j]=1
if flag: #有重复
samenums.append(nums[i])
states[i]=1
else:
diffnums.append(nums[i])
print("Same numbers={1},counter={0}".format(len(samenums),samenums))
print("different numbers={1},counter={0}".format(len(diffnums),diffnums))
print(list(zip(states,nums)))
本文转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号