大语言模型LLM幻觉的解决方法:检索增强生成RAG
当你向大语言模型LLMs集成的问答系统平台咨询医疗方面的问题,比如呼吸道感染应该怎么治疗,它可能直接给出答案,但不会提供这个答案的依据来源,这是因为大语言模型应用过程中还存在答案透明度不足的缺陷导致。此外,大语言模型还有知识更新的滞后性、在处理复杂任务时的准确性的问题。
为了解决这些问题,检索增强生成(Retrieval-Augmented Generation, RAG)的概念应运而生。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
RAG的实现通常涉及三个主要组成部分:检索器(retriever)、生成器(generator)和增强方法(augmentation methods)。检索器的主要任务是从一个庞大的外部知识库中找到与查询相关的内容;生成器则负责根据检索到的内容生成合理的回答;而增强方法则涉及改进检索器和生成器之间的交互方式,以提高整个系统的效率和准确性。
RAG通过结合传统的大语言模型与外部知识库的检索,能够显著提升答案的准确性,减少模型的幻觉现象,特别是在知识密集型任务中。这种方法通过利用外部的、非参数化的知识库,与内置于LLMs中的参数化知识相结合,有效地弥补了单一模型的知识限制。
举个实际的例子,考虑一个基于RAG的问答系统。当用户询问特定的历史事件或科技新闻时,传统的LLM可能会根据其训练数据生成答案,而这些训练数据可能已经过时。相比之下,RAG系统会实时检索最新的外部数据,如维基百科或新闻文章,以提供最准确、最新的信息。
尽管RAG在许多方面表现出色,但它在实际应用中也面临着一些关键挑战。Kandpal等人在2023年的研究中指出了大型语言模型(LLMs)面临的一个重要局限性 —— 学习和回忆长尾知识的困难。所谓“长尾知识”,指的是那些不常见、比较晦涩或极为特定的信息,这些信息不经常出现或众所周知。这意味着,对于罕见或特定领域的问题,LLMs可能无法提供准确的答案。此时,RAG通过检索相关文献或数据,可以大幅提高这些问题的回答质量。
RAG的发展趋势值得我们关注。Gao等人在2023年的研究中指出,RAG技术将成为实现大型语言模型的最重要方法之一。他们总结了RAG的三种发展范式:初级RAG、高级RAG和模块化RAG,并讨论了如何评估RAG模型的有效性,强调了关键指标和评估能力。
随着RAG技术的不断发展,其在多个领域的应用案例也日益增多。从问答系统到内容创作,RAG为提高输出的相关性和准确性提供了新的可能性。Gao等人在2023年的研究中总结了RAG的三种发展范式:初级RAG、高级RAG和模块化RAG,并讨论了如何评估RAG模型的有效性,强调了关键指标和评估能力,这些都为未来的应用提供了丰富的思路和框架。
如何准确地衡量模型的性能,如何根据评估结果对模型进行优化,是开发者需要重点考虑的问题。2023年的SELF-RAG研究表明,模型被训练时对外部知识源动态检索信息,根据模型对自己输出的评估来决定,进行主动检索。然后对自己输出的信息进行评估和判断,识别输出中的不确定性和可能的错误,最后对输出的的我判断和修正,确保回答的准确定和相关性,提高答案的质量和可信度。
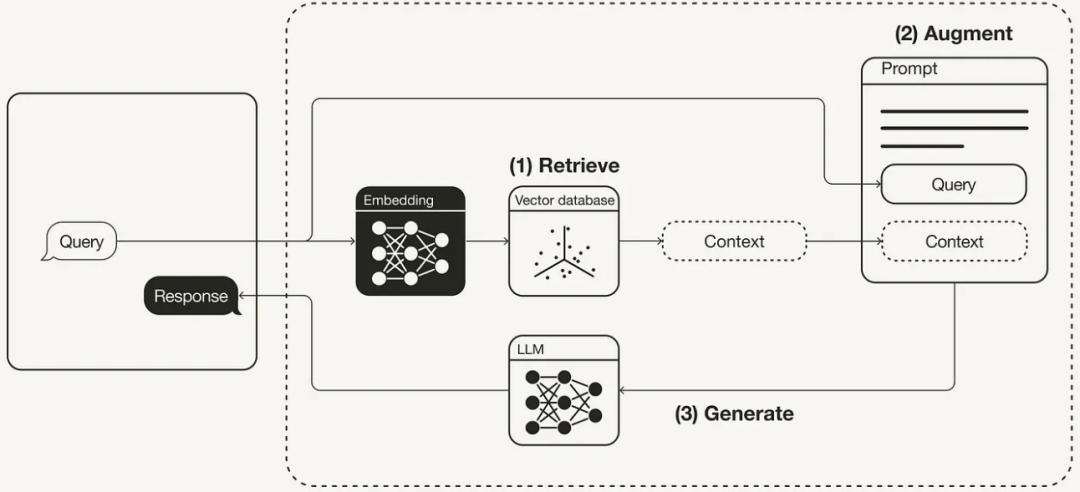
RAG 工作流程
如何在实际项目中应用RAG模型也是一个值得探讨的问题。在实际项目中应用RAG模型通常需要考虑如下几个因素:
1、选择合适的模型:基于项目需求,选择一个适合的RAG模型。这可能涉及到评估不同模型的性能,如处理速度、准确性和对长尾知识的处理能力。对于需要高准确性和细粒度信息的任务,就需要考虑高度专业化的RAG模型。
2、数据和知识源的准备:RAG模型的效果很大程度上依赖于其检索的外部知识源。因此,选择和维护高质量的知识库或数据源至关重要。后期的定期更新数据库,以确保模型能够访问最新的信息。
3、系统集成与优化:将RAG模型集成到现有系统中可能需要一些技术调整。例如,可能需要开发API接口来允许模型与其他系统组件通信,或者对模型进行微调以适应特定类型的查询。
4、性能监控与维护:部署模型后,需要持续监控其性能。这包括跟踪其准确性、响应时间和用户满意度。基于这些指标,需要定期对模型进行调整或再训练,以应对新的数据趋势或业务需求的变化。
5、用户体验和界面设计:为了确保模型的有效使用,需要考虑用户体验和界面设计。这意味着创建直观的用户界面,使非技术用户也能轻松地与模型互动,同时提供清晰的反馈和说明,帮助用户理解模型的输出。
6、合规性与伦理考虑:最后,使用RAG模型时还需要考虑数据隐私、安全性和伦理问题。这可能涉及确保数据处理遵守相关法律法规,以及在设计模型时考虑到潜在的偏见和不公平性问题。
我们相信随着技术的不断完善和应用范围的扩大,RAG 的性能和实用性将得到进一步的提升,未来的发展还能见证RAG技术在各多领域的创新项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号