Python爬虫实战:知音漫客漫画采集
前言
这年头看啥都要会员,各种VIP,没有VIP各种时长广告,就算你开了VIP还会有超级VIP出来,简直无止境【绝对没有内涵谁】,作为一个资深白嫖者,白嫖一时爽,一直白嫖一直爽【咳咳,该用还得开,不要学我】
恰巧同事找我借某平台VIP,看个漫画都要VIP了,于是呢我就给爬了下来,所以就有了这篇文章。为了过审,我把爬取VIP的内容全部去掉了,肯定有人会问,既然爬的都是公开内容,那么我在网站上直接看不就得了?这种问题回多了就没意思了,直接先去看我前面的爬虫教程文章。
废话不多说,直接进入今天 的主题

爬取目标
网址:

效果展示
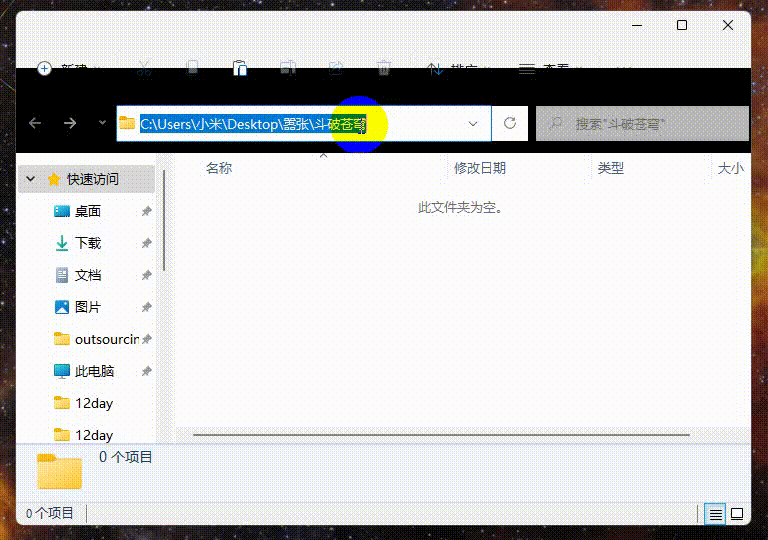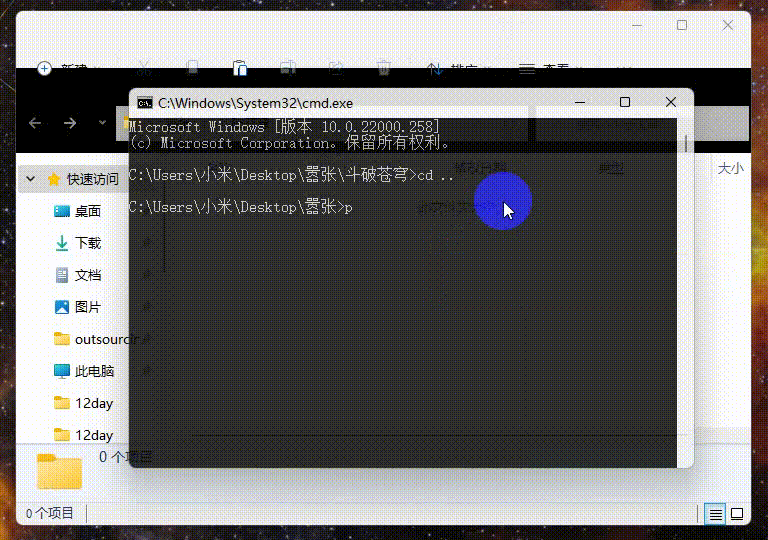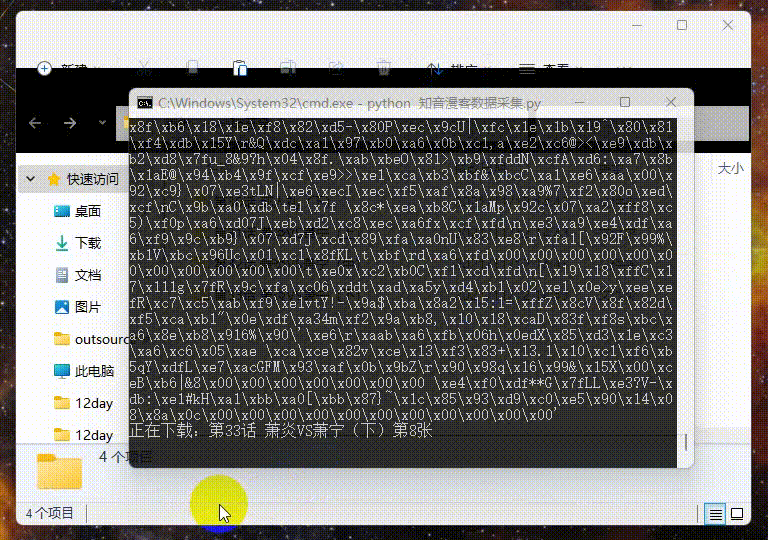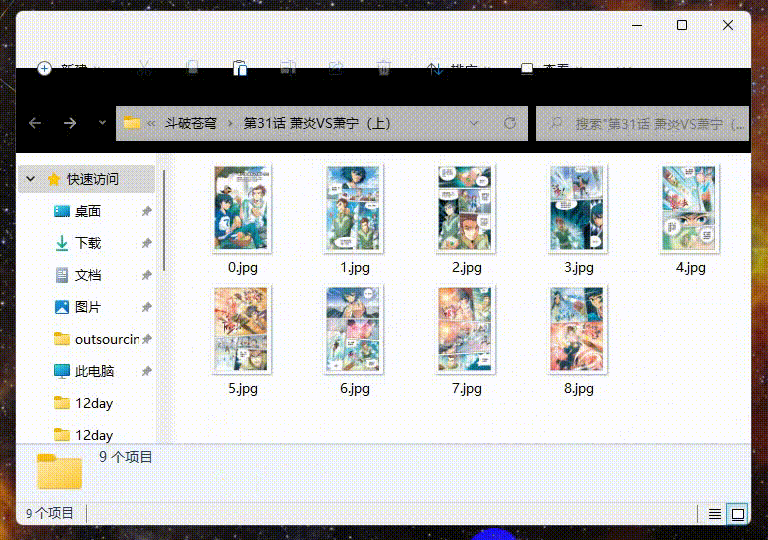
工具准备
开发工具:pycharm 开发环境:python3.7, Windows11 使用工具包:requests
项目思路解析
选择自己需要的动漫这里辣条选择的是斗破苍穹,动漫看萧炎装逼是在太难受了,三年之约硬生生更新了快5年,想办法把它的漫画全给采集了一次到位,搜索需要的漫画名,获取首页的数据信息进行查看,先分析数据是否为加载的动态数据。
需要获取的数据抓包并未获取到,尝试进入漫画页面,看看能不能获取到数据 知音漫客的很多数据都是vip的需要付费观看,但是还是会加载出数据信息,数据里依旧会有我们的漫画信息。
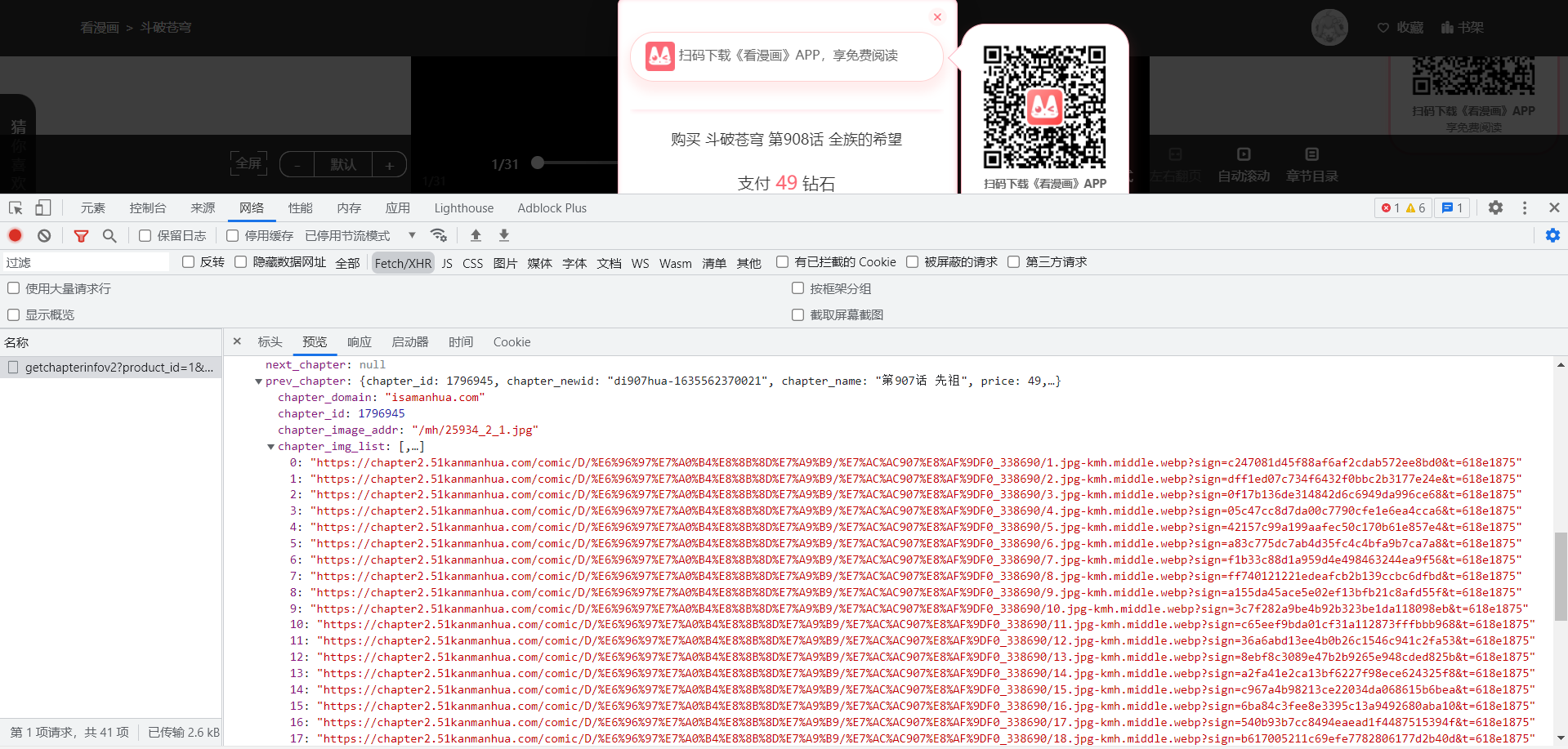
所以说付费的内容不可怕,重点能找的到就好了(狗头保命.jpg) 当前的数据就是知音漫客的图片地址。
知道数据信息后开始分析目标网址,怎么控制数据的翻页
简易源码分享
import requests
import os
def download(img_url_list, title):
# 每个章节 设定单独的文件夹
path = '斗破苍穹/' + title
if not os.path.exists(path):
os.mkdir(path)
i = 0
for img_url in img_url_list:
res = requests.get(img_url).content
print(res)
f = open(path + '/' + str(i) + '.jpg', 'wb')
f.write(res)
i += 1
print(f'正在下载:{title}第{str(i)}张')
def parse_data(url):
response = requests.get(url).json()
chapter_name = response['data']['current_chapter']['chapter_name']
chapter_img_list = response['data']['current_chapter']['chapter_img_list']
download(chapter_img_list, chapter_name)
if __name__ == '__main__':
for i in range(30, 800):
url = 'https://www.kanman.com/api/getchapterinfov2?product_id=1&productname=kmh&platformname=pc&comic_id=25934&chapter_newid=dpcq_{}h&isWebp=1&quality=middle'.format(i)
parse_data(url)一个真事:我在一个接单群,有个朋友接了一个爬虫的单,然后进去了【没错就是进局子里了】,事情大概就是他爬取了一个婚恋交友平台网站的一些信息的单子,然后发布这个单子的人,利用这些数据去诈骗获利了,所以我这个朋友也跟着进去了,现在还没结果。
搞爬虫一定要注意界限,遵法守纪!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号