


我用Python抓取了【S11全球总决赛】直播评论,EDG nb
《爬虫100例实战案例》又来了,昨天兄弟萌看直播了吗,一句话EDG牛掰就完事了。
四强的时候
T1:我是三冠王
GENG:我是双冠王
DK:我是去年世界冠军
EDG:本来想以第一次进四强的身份和你们相处,没想到得到的却是疏远。不装了!摊牌了!我是今年世界冠军!

爬取数据目标
网站:
效果展示
工具使用
开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,threading, csv
重点学习内容
-
常见请求头的反爬
-
json数据的处理
-
csv文件处理
项目思路解析
找到你需要采集的视频地址(EDG牛逼!!!!)
网址:
爬虫采集数据首先要找到对应的数据目标地址,可以明显看出当前的网页的评论数据是在不断变化的,需要找到对应的评论接口,习惯性的去找动态数据。
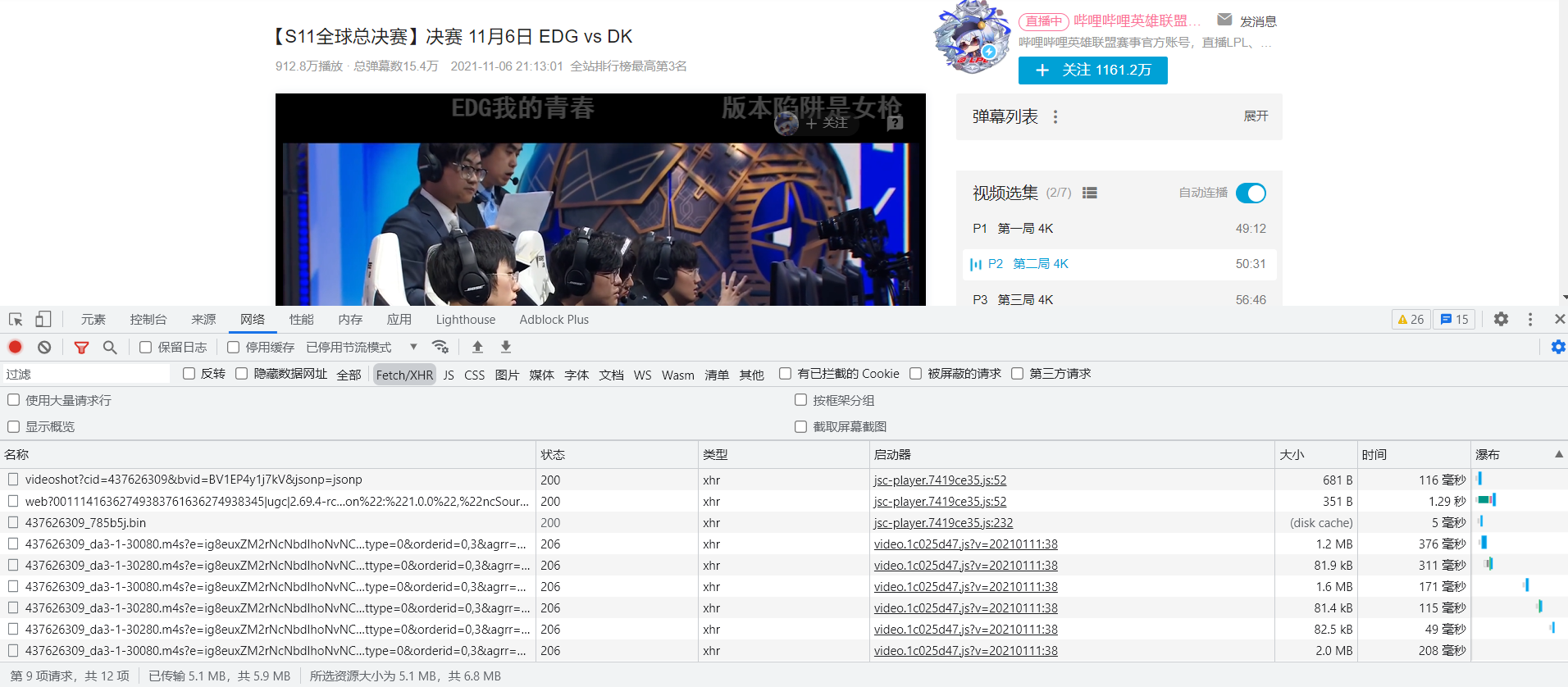
数据并没有在动态数据里,清空数据加载新的评论数据,触发加载条件。
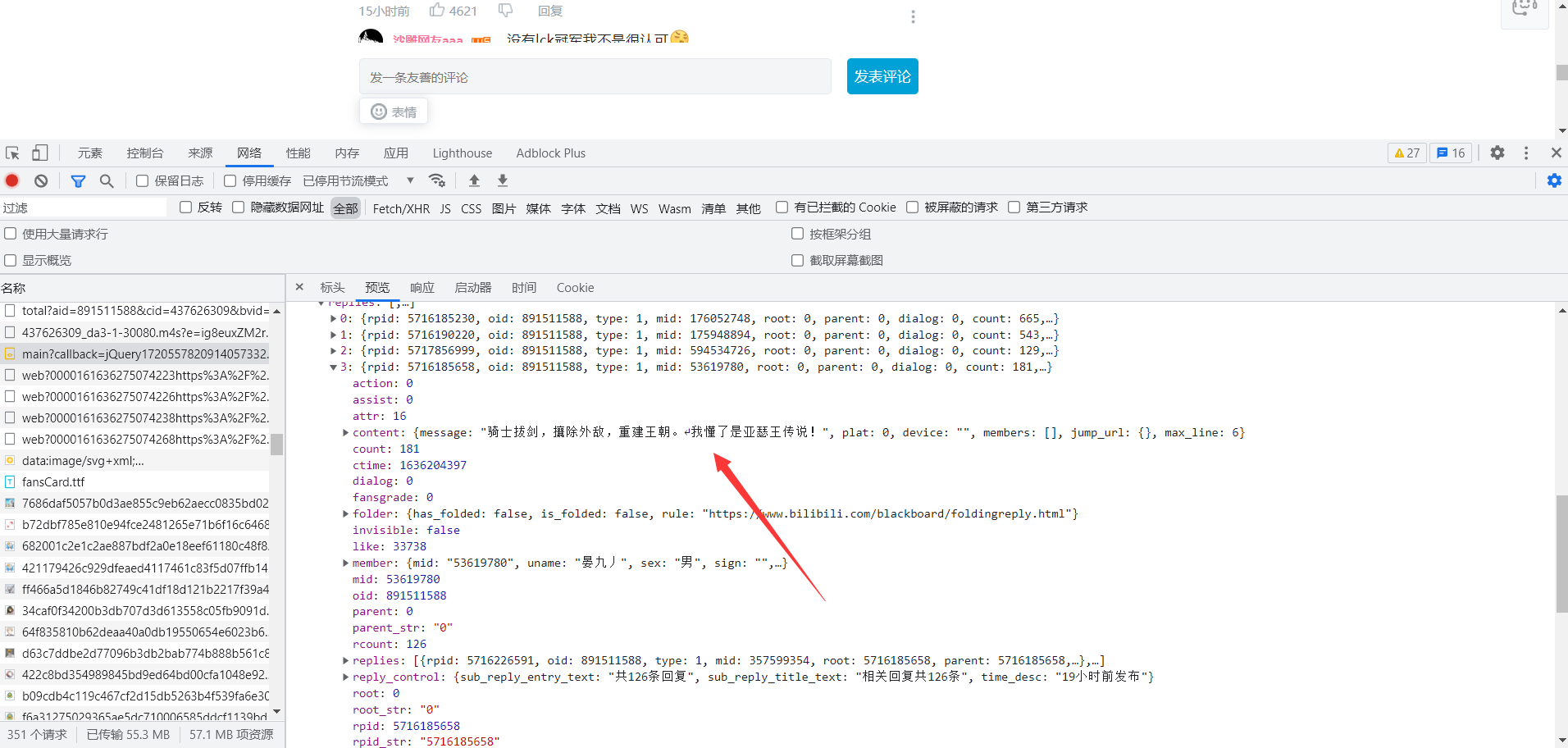
加载的数据在all里,明确数据之后就好处理了,获取到对应的网页接口,通过requests发送网络请求。
url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={}&type=1&oid=891511588&mode=3&plat=1&_=1636272184444'.format(i)
response = requests.get(url)
print(response.text)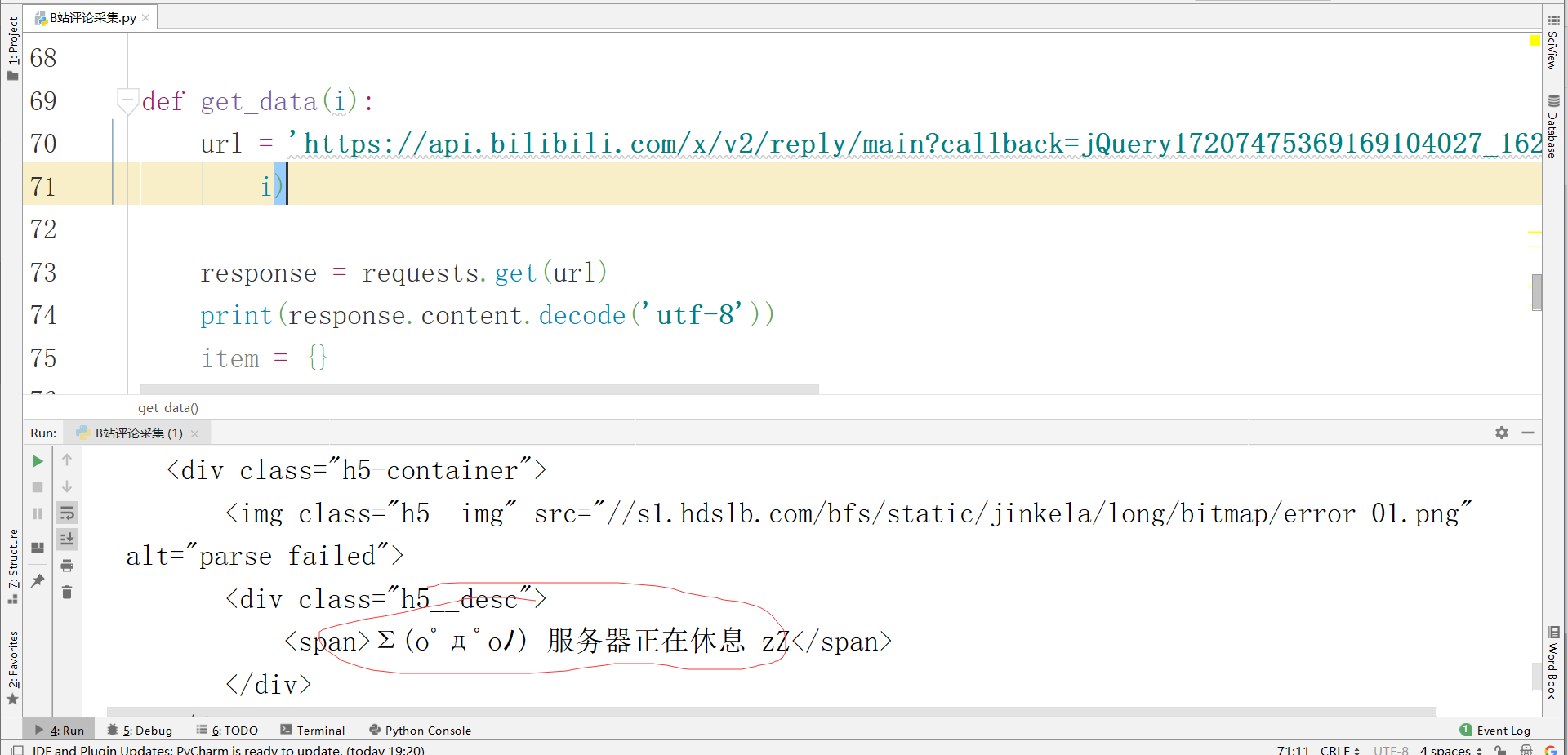
数据请求失败请求头没有做反爬策略 添加对应的ua,以及refere 主要是防盗链的请求头措施,在浏览器请求也是得不到数据的,获取到准确的数据,提取自己想要的数据信息。
-
评论的内容
-
评论的时间
-
评论的作者
-
作者的性别
-
作者的个性签名
-
(各位大佬可以根据自己的需求进行自动的采集数据)
处理json数据时要注意, json数据前有jQuery1720892078778784086_1627994582044 可以通过正则的方式进行匹配提取 这里我选择修改url的参数 讲网址的jQuery1720892078778784086_1627994582044进行删除 最终的网址是:
https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={}&type=1&oid=891511588&mode=3&plat=1&_=1636272184444
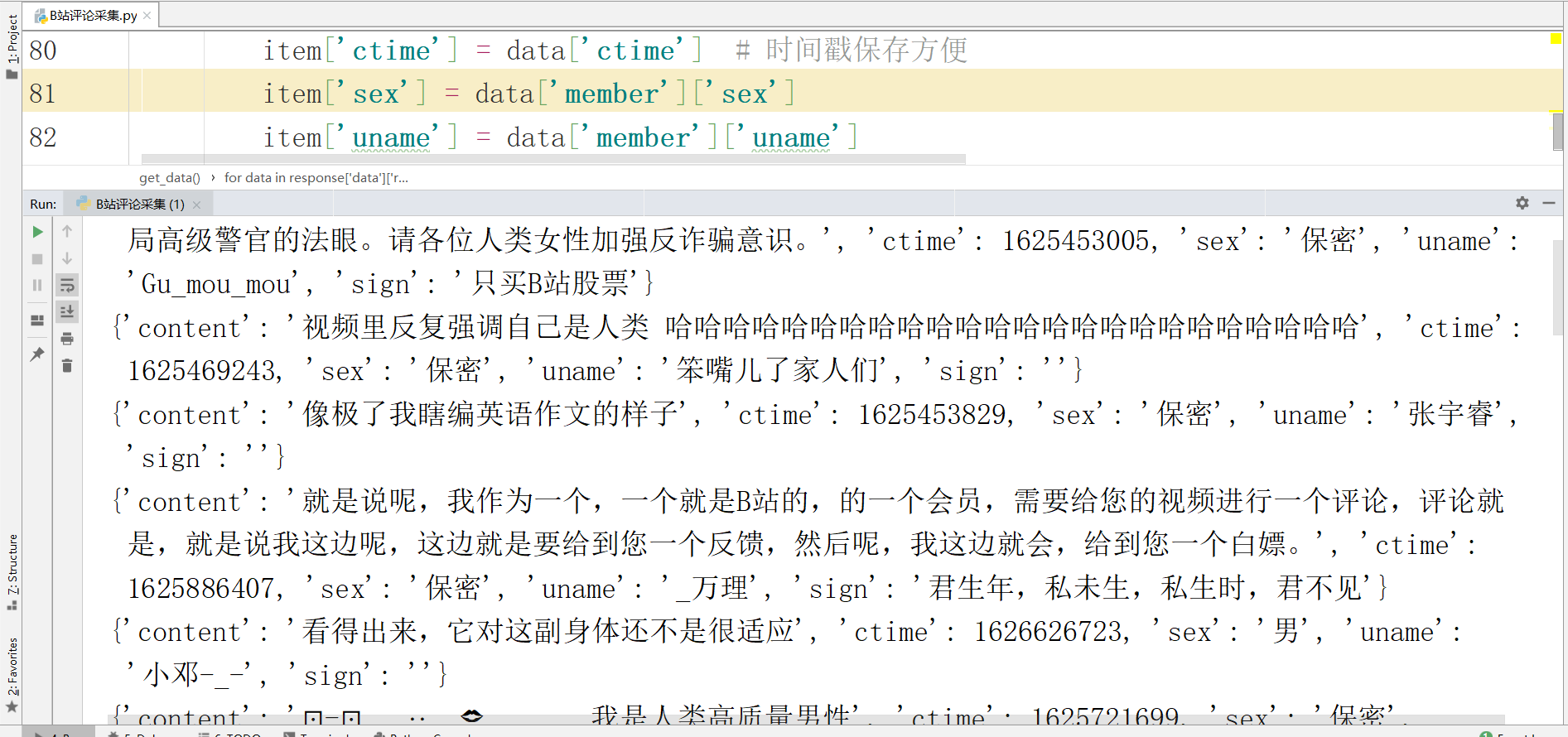
获取到数据后进行数据保存,数据保存在csv文件。
def save_data(item):
with open('小破站1.csv', "a", newline='', encoding="utf-8")as f:
filename = ['content', 'ctime', 'sex', 'uname', 'sign']
csv_data = csv.DictWriter(f, fieldnames=filename)
csv_data.writerow(item)
简易源码分享
import requests
import csv
def save_data(item):
with open('EDG牛逼!.csv', 'a', newline='', encoding='utf-8')as f:
filename = ['content', 'uname', 'sign', 'sex']
csv_data = csv.DictWriter(f, fieldnames=filename)
# csv_data.writeheader()
csv_data.writerow(item)
def get_data(url):
headers = {
'referer': 'https://www.bilibili.com/bangumi/play/ss5852/?from=search&seid=6248919601957945511',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
response = requests.get(url, headers=headers).json()
item = {}
for data in response['data']['replies']:
item['content'] = data['content']['message'].strip()
# print(content)
item['uname'] = data['member']['uname']
item['sign'] = data['member']['sign']
item['sex'] = data['member']['sex']
# print(item)
save_data(item)
if __name__ == '__main__':
for i in range(1, 3):
url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={}&type=1&oid=891511588&mode=3&plat=1&_=1636272184444'.format(i)
html = get_data(url)2012,一个卡牌,一个雷恩加尔,一群红衣少年的欢声笑语。
2013,一个杰斯,一个扎克,一场支离破碎的梦境。
2014,一个螳螂,一个兰博,一座摇摇欲坠的基地。
2015,一个寡妇,一个妖姬,一本永远叠不上去的梅贾窃魂卷。
2016,一个盲僧,一个奥拉夫,一串耻辱的数字。
2017,一个克格莫,一个青钢影,一个赛区绝境中最后的救赎。
2018,一个刀妹,一个剑魔,一个至高无上的尊严。
2019,一个泰坦,一个盲僧,一个浴火重生的凤凰。
2020,一个船长,一个剑姬,一个杀戮无法弥补的遗憾。
2021,一个皇子,一个佐伊,一个挽大厦于将倾的骑士。

