


我用Python爬取了女神视界,爬虫之路永无止境【内附源码】
我发现抖音上很多小姐姐就拍个跳舞的视频就火了,大家是冲着舞蹈水平去的吗,都是冲着颜值身材去的,能刷到这篇文章的都是lsp了,我就跟大家不一样了,一个个刷太麻烦了,我直接爬下来看个够,先随意展示两个。

采集目标
爬取目标:
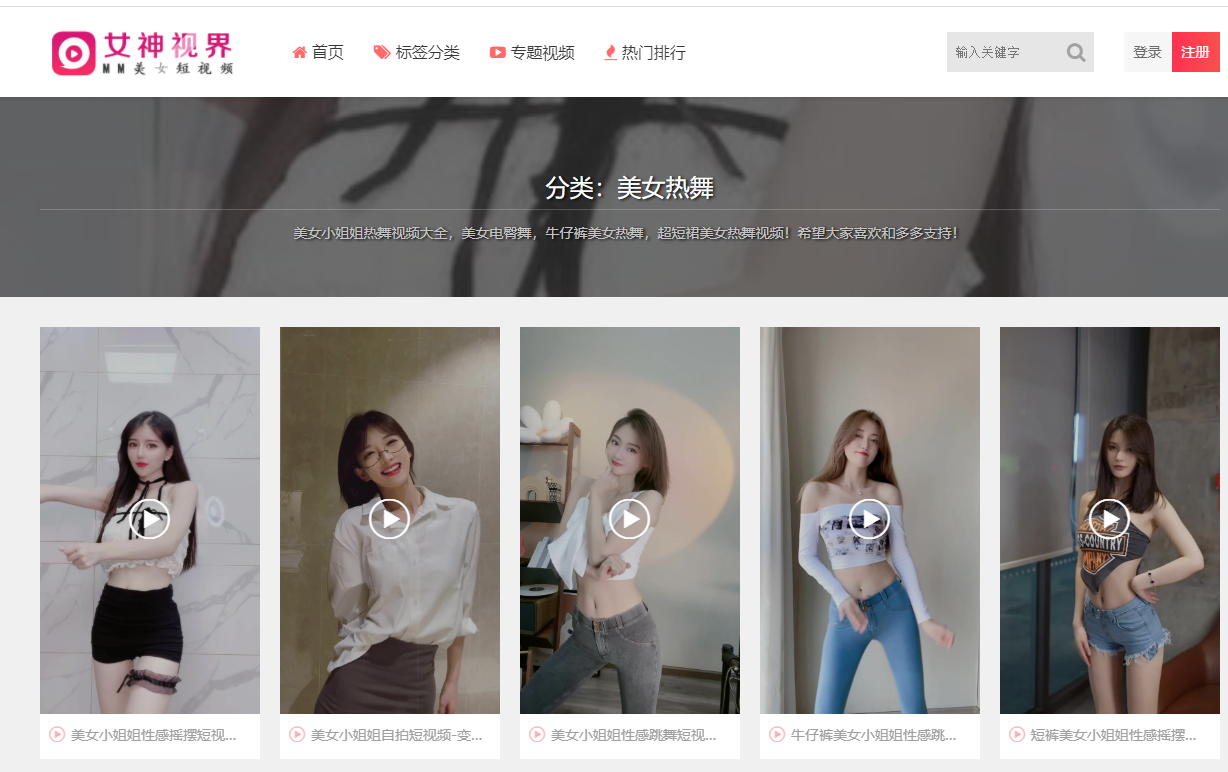
效果展示
![]()
工具使用
使用环境:Python3.7 工具:pycharm 第三方库:requests, re, pyquery
爬虫思路:
-
获取的是视频数据 (16进制字节)
-
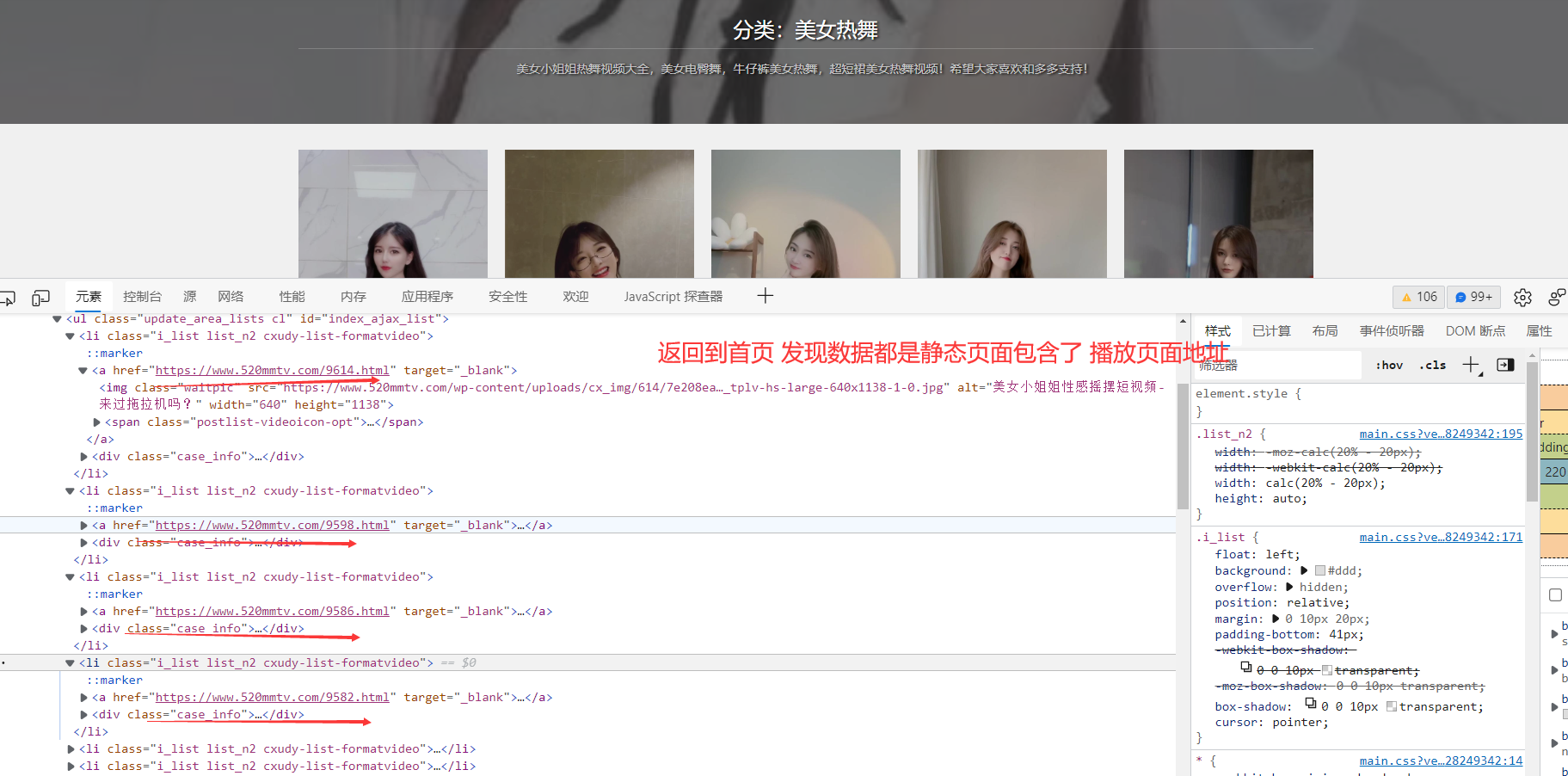
在这个页面没有视频地址 需要进去详情页 所有需要从 视频播放页开始抓取
使用快捷键 F12 进入开发者控制台:
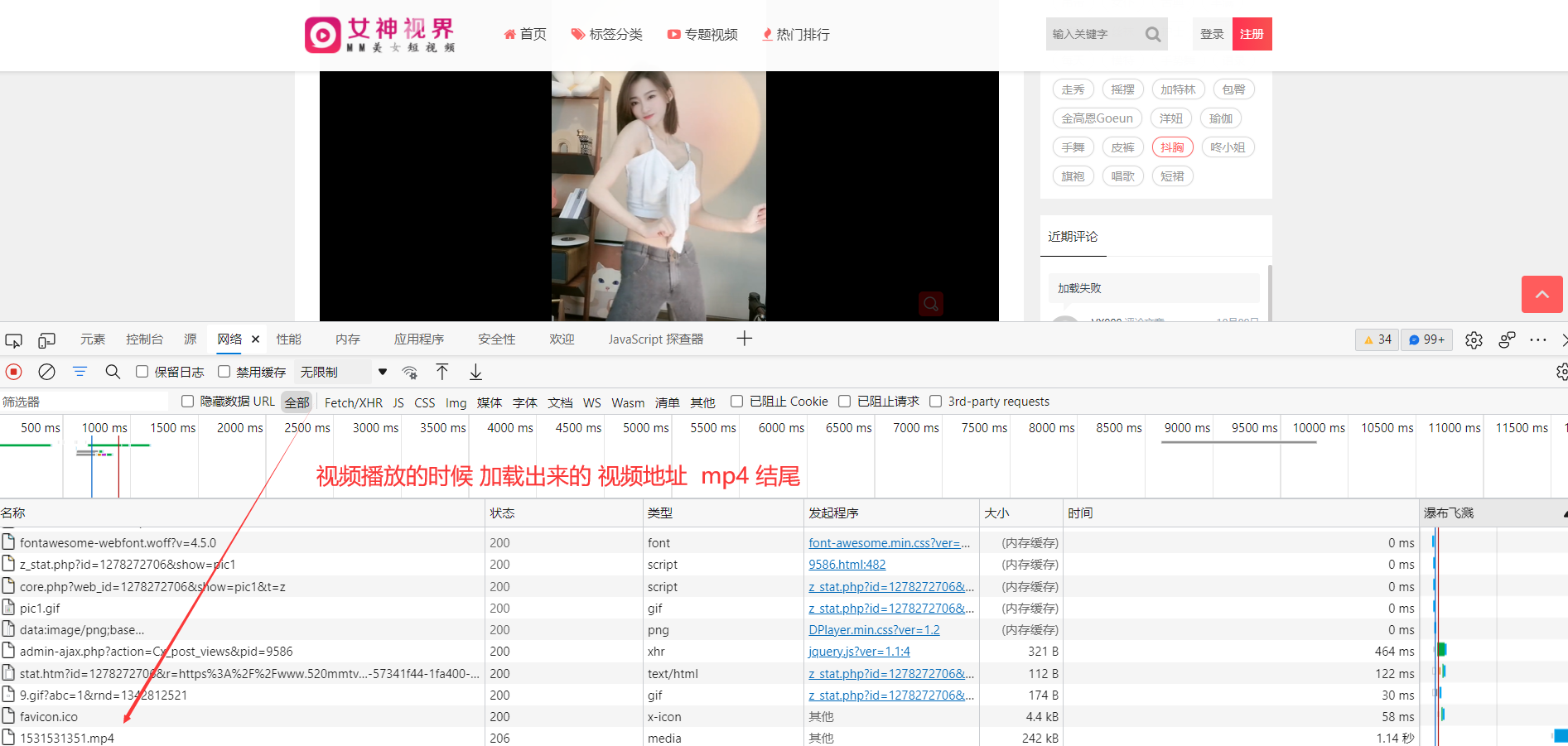
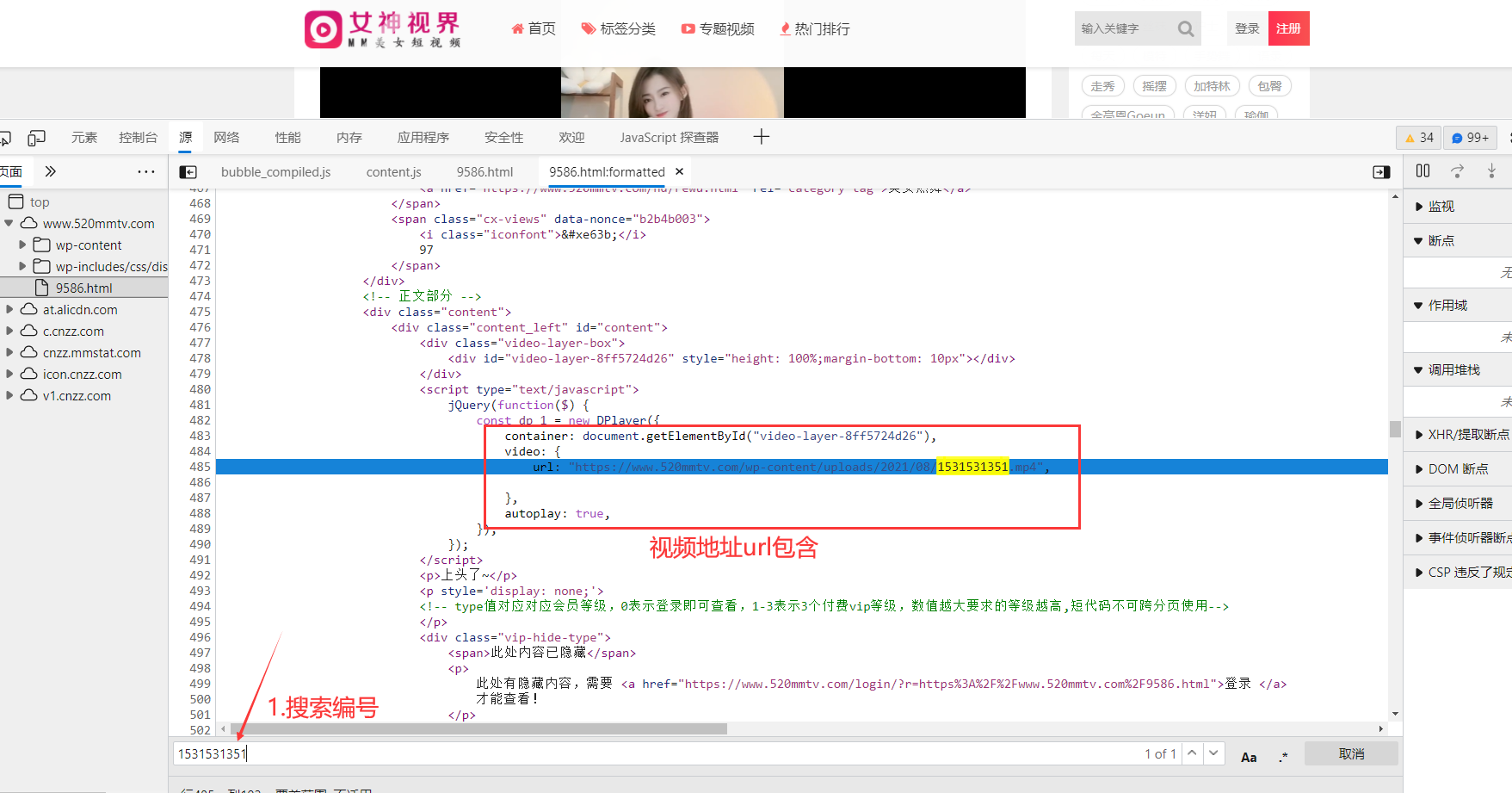
先不急, 找到 视频地址 去搜索他 看看在哪里有包含:
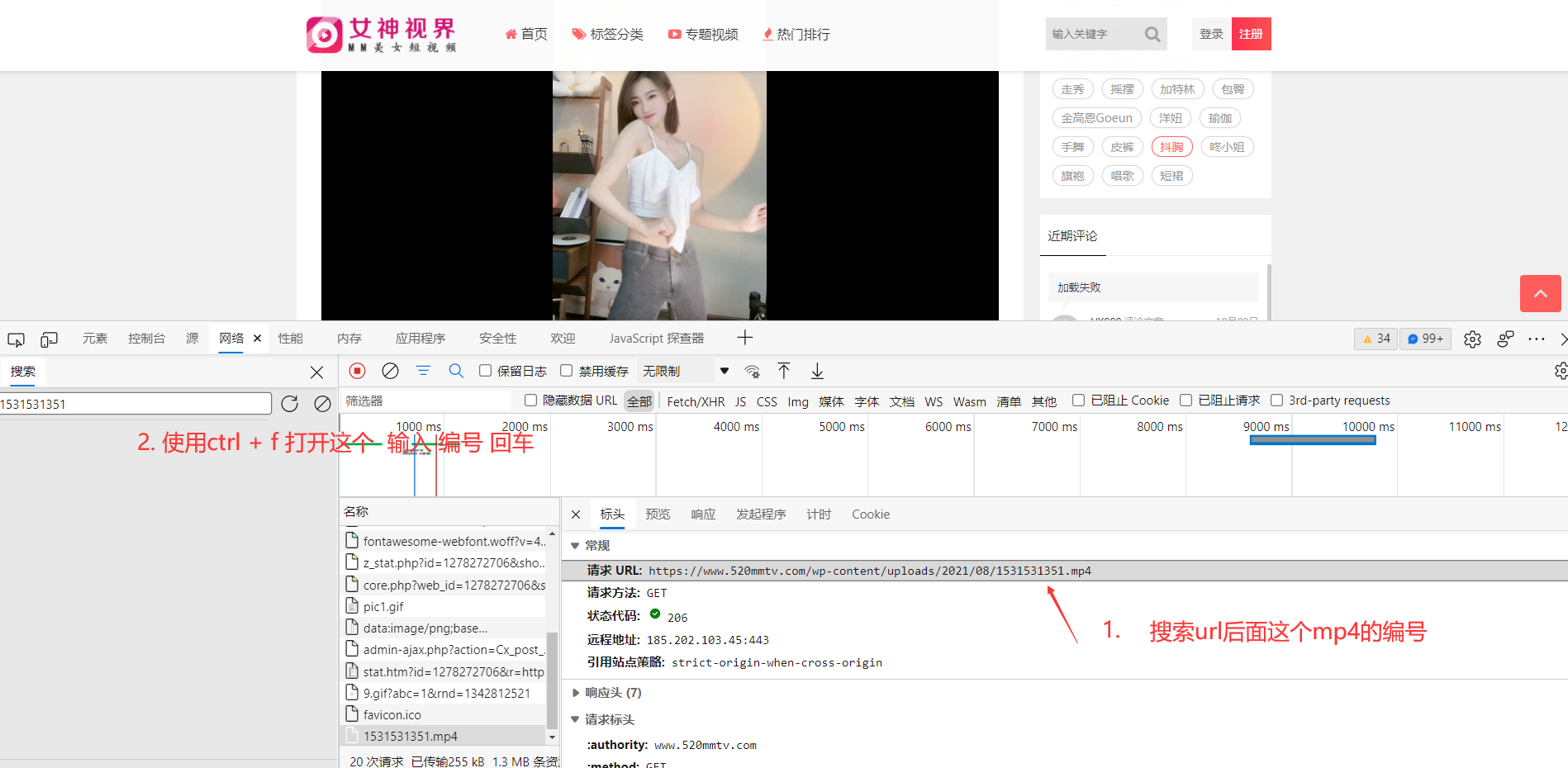
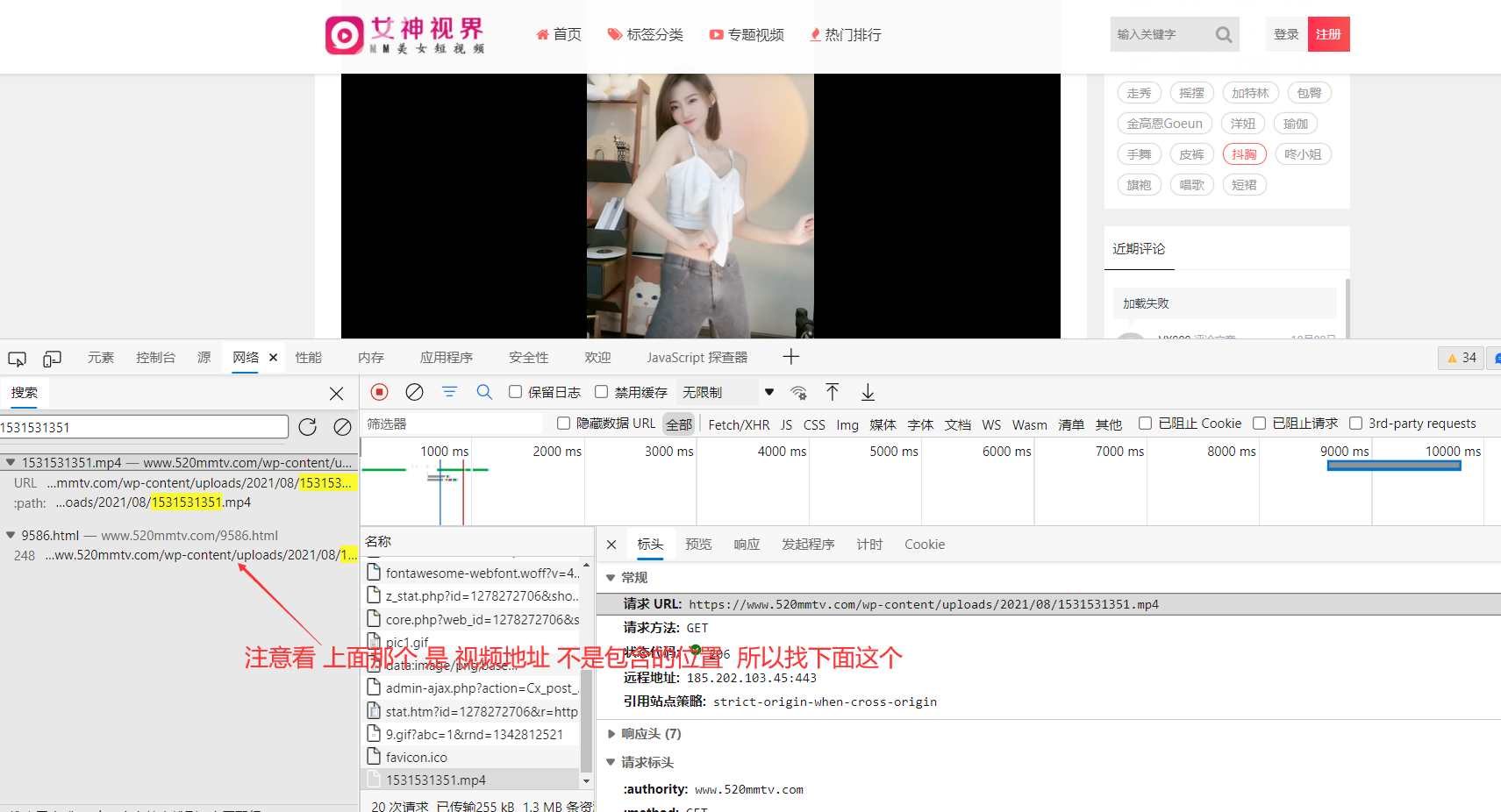
定位他 发现是静态页面返回的数据:
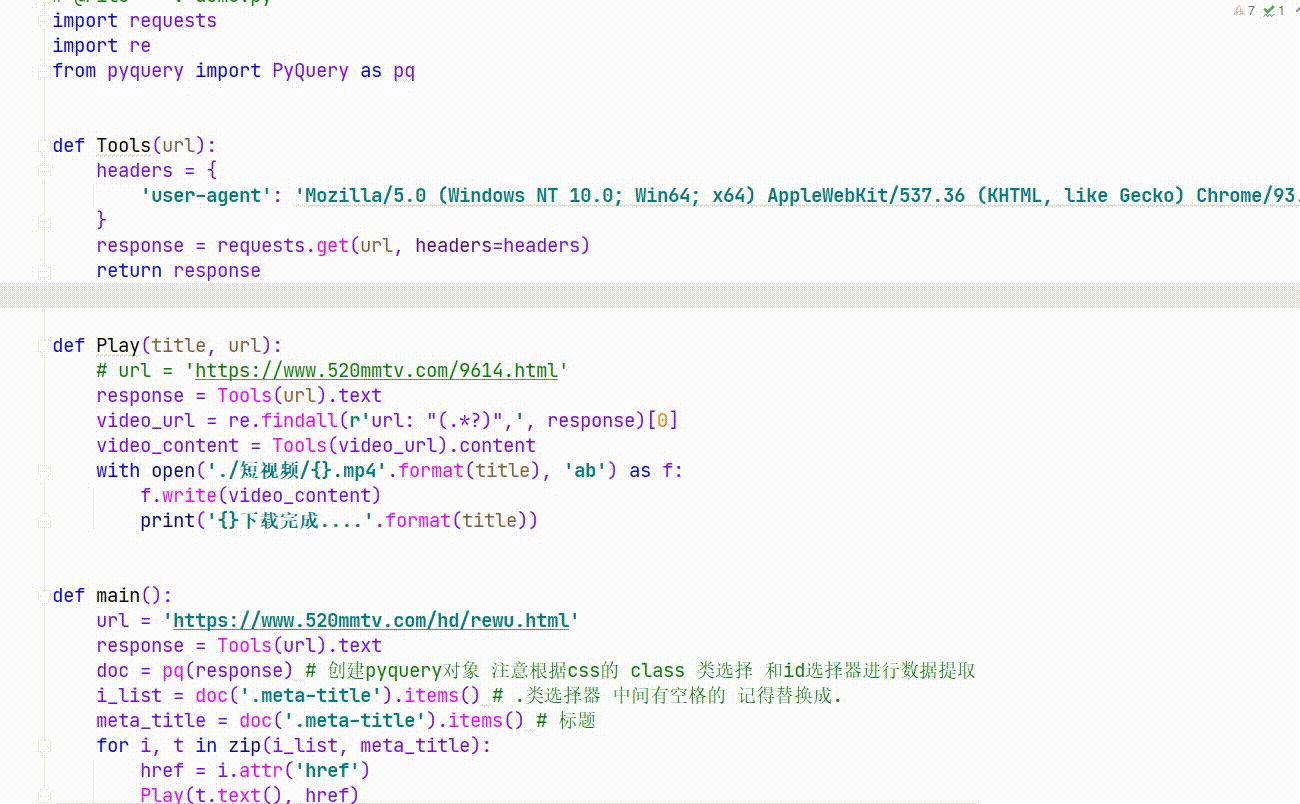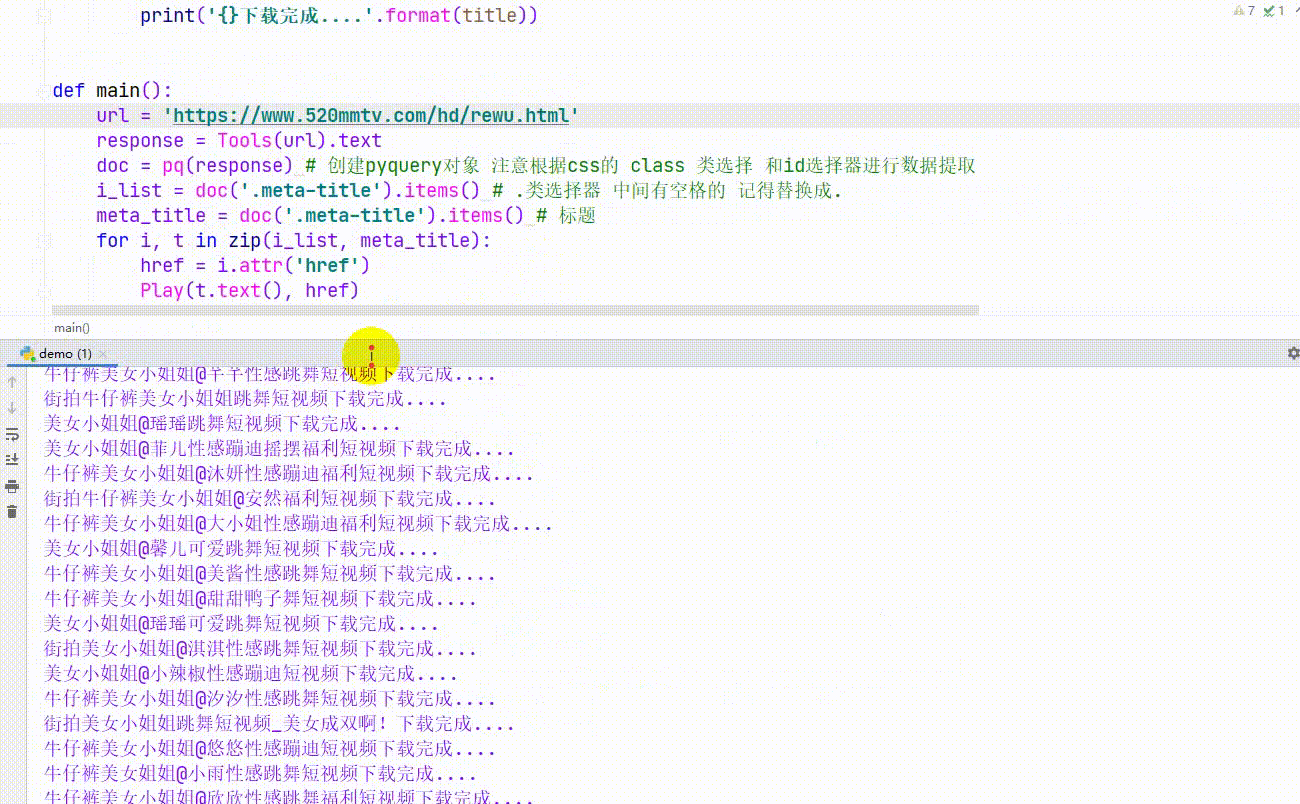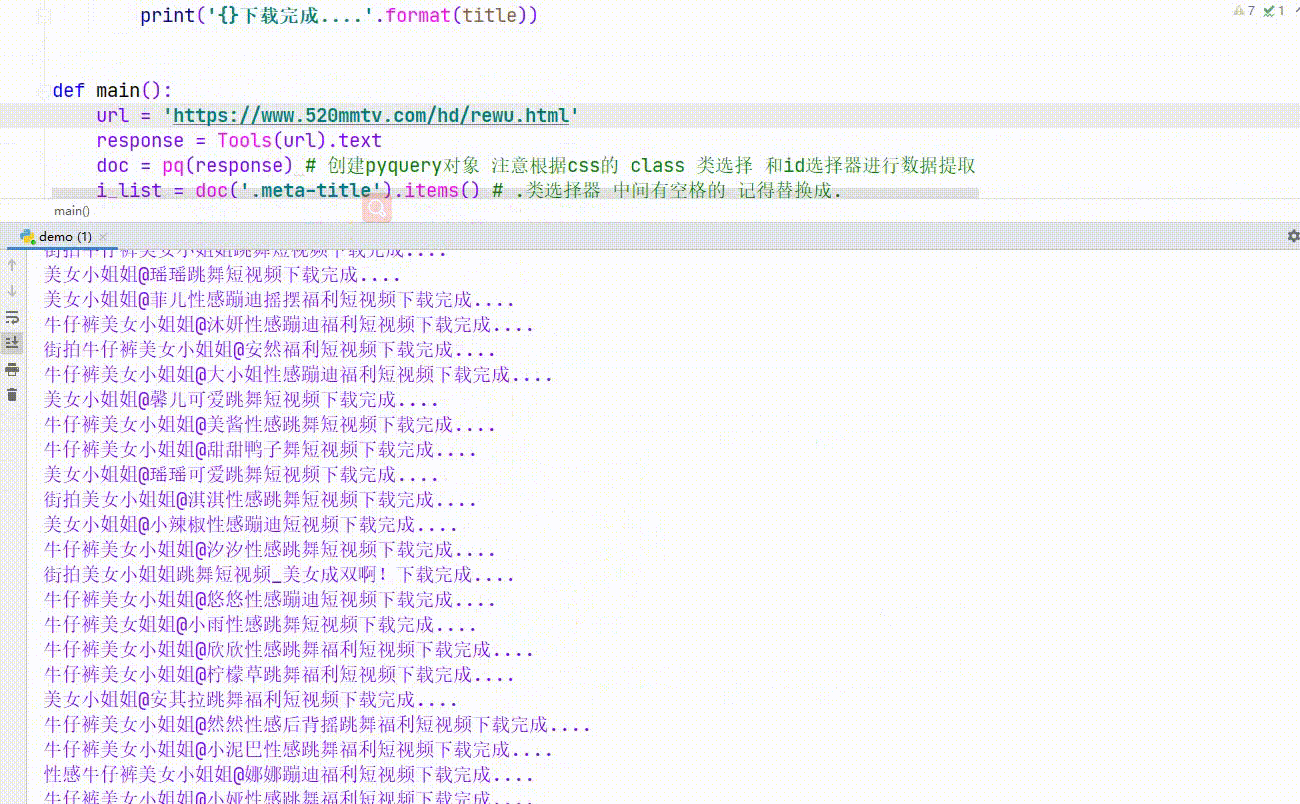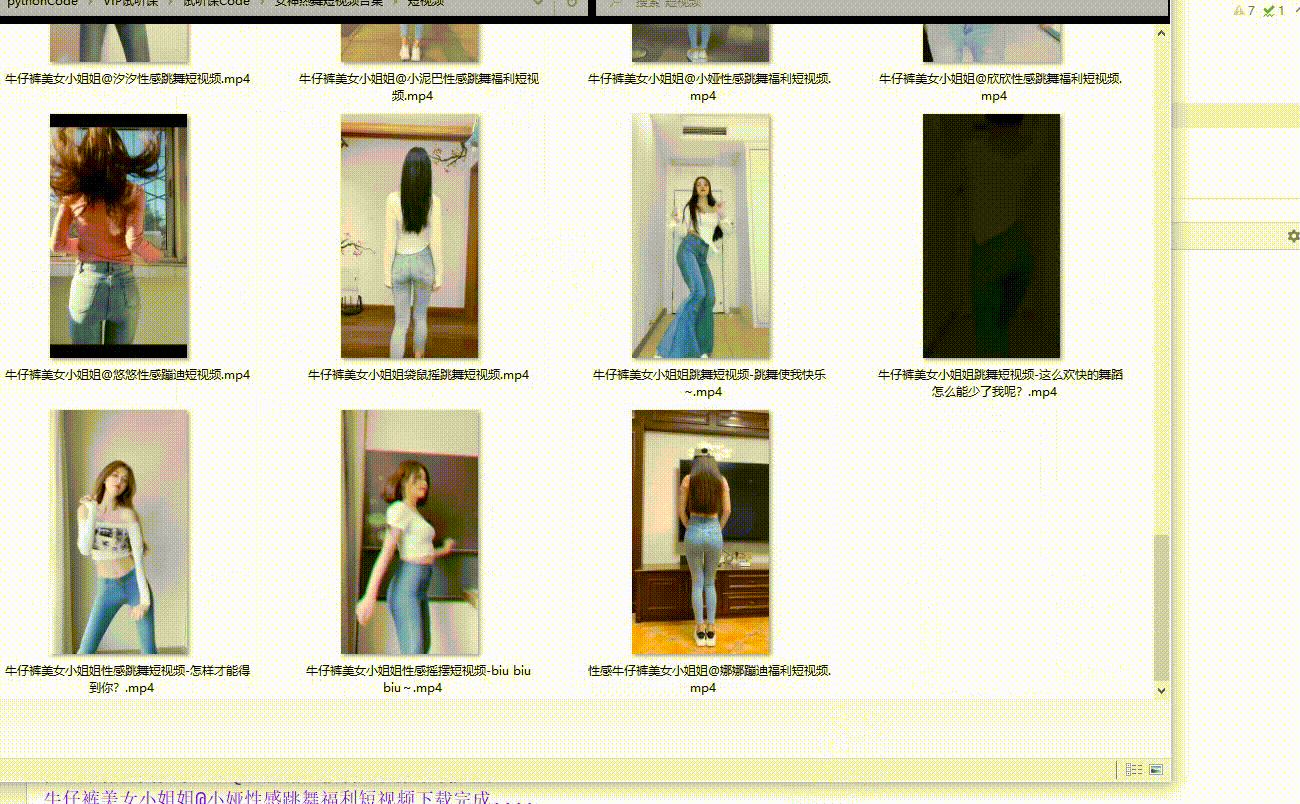
上代码:
def Tools(url):# 封装一个工具函数 用来做请求的
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
response = requests.get(url, headers=headers)
return response
url = 'https://www.520mmtv.com/9614.html'
response = Tools(url).text
video_url = re.findall(r'url: "(.*?)",', response)[0] # 正则表达式提取 视频地址
video_content = Tools(video_url).content
# 视频地址存储 需要在代码同路径 手动创建 短视频文件夹
with open('./短视频/123.mp4', 'ab') as f:
f.write(video_content)
# 下载了一个
def main():
url = 'https://www.520mmtv.com/hd/rewu.html'
response = Tools(url).text
doc = pq(response) # 创建pyquery对象 注意根据css的 class 类选择 和id选择器进行数据提取
i_list = doc('.i_list.list_n2.cxudy-list-formatvideo a').items() # .类选择器 中间有空格的 记得替换成.
meta_title = doc('.meta-title').items() # 标题
for i, t in zip(i_list, meta_title):
href = i.attr('href')
Play(t.text(), href)全部代码:
import requests
import re
from pyquery import PyQuery as pq
def Tools(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
response = requests.get(url, headers=headers)
return response
def Play(title, url):
# url = 'https://www.520mmtv.com/9614.html'
response = Tools(url).text
video_url = re.findall(r'url: "(.*?)",', response)[0]
video_content = Tools(video_url).content
with open('./短视频/{}.mp4'.format(title), 'ab') as f:
f.write(video_content)
print('{}下载完成....'.format(title))
def main():
url = 'https://www.520mmtv.com/hd/rewu.html'
response = Tools(url).text
doc = pq(response) # 创建pyquery对象 注意根据css的 class 类选择 和id选择器进行数据提取
i_list = doc('.meta-title').items() # .类选择器 中间有空格的 记得替换成.
meta_title = doc('.meta-title').items() # 标题
for i, t in zip(i_list, meta_title):
href = i.attr('href')
Play(t.text(), href)
if __name__ == '__main__':
main()下载比较慢网络不好,你网快的话 ,就下载快。
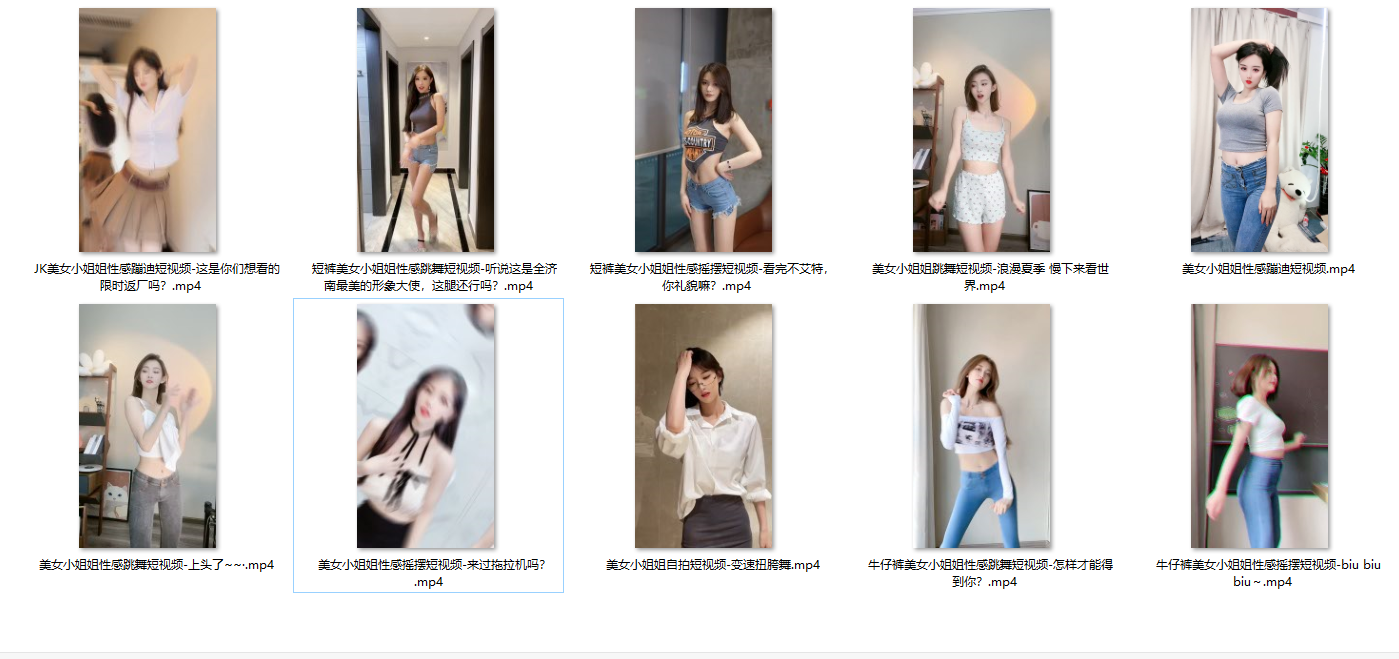
效果:
👇🏻 疑难解答可通过搜索下方获取👇🏻

