
基于内容自适应的视频超分辨率算法-SRVC
1. 介绍
论文全名是《Efficient Video Compression via Content-Adaptive Super-Resolution》,作者全部来自麻省理工计算机科学与人工智能实验室(MIT CSAIL),这篇论文主要是使用视频超分辨率(video super-resolution)技术来完成视频压缩任务,从而应用于视频的传输(节省带宽)。
2. 算法详解
2.1 传统视频编码管线
众所周知,将图像序列转成一个视频可以大大减少数据存储量(绝大部分情况)。但是,生成的视频如果要在网络上传播的话会严格收到网络带宽的限制。在固定带宽(固定传输速率)的情况下,使用更高的视频压缩算法(同时保证视频质量不损失,或者损失在一定范围内),可以传输更高分辨率的视频。比如,1M的带宽,使用某个视频压缩算法只能传输480P的视频,在使用了更加高效的另外一个视频压缩算法,可以传输720P了。
目前常用的视频压缩算法有H.264、H.265等。这里以H.265为例,其工作原理大致如下:

在上面加入超分的思想,就是先把1080P的视频下采样至480P,压缩传过去解码后,再用超分变回1080P的视频,大致流程如下

这样的好处是视频压缩算法真正要压缩的其实是480P的视频,所以传输的数据量会大大减少。坏处则是传输者在下采样视频的时候其实已经丢掉了一部分信息,而接收者最后获得的1080P视频的质量很大程度上依赖于超分算法的选择。超分算法可以使用最简单的Bicubic(双三次插值)。
Bicubic网上的资料很多,简单来说它跟bilinear(双线性插值)一样,插值的结果依赖邻域的像素,也就是可以用图像中的卷积来完成。但是Bicubic的卷积kernel是固定的,这就很不科学。“科学”来讲,kernel应该根据图像中的不同区域产生不同的变化。
此外,视频经过H.265编码、解码后,已经不是原来的视频了(因为H.265是有损压缩),所以超分的过程还需要尽量恢复这里丢失的信息。
于是,轻量级的超分网络SRVC来了!
2.2 本算法管线
下图是论文里的pipeline。
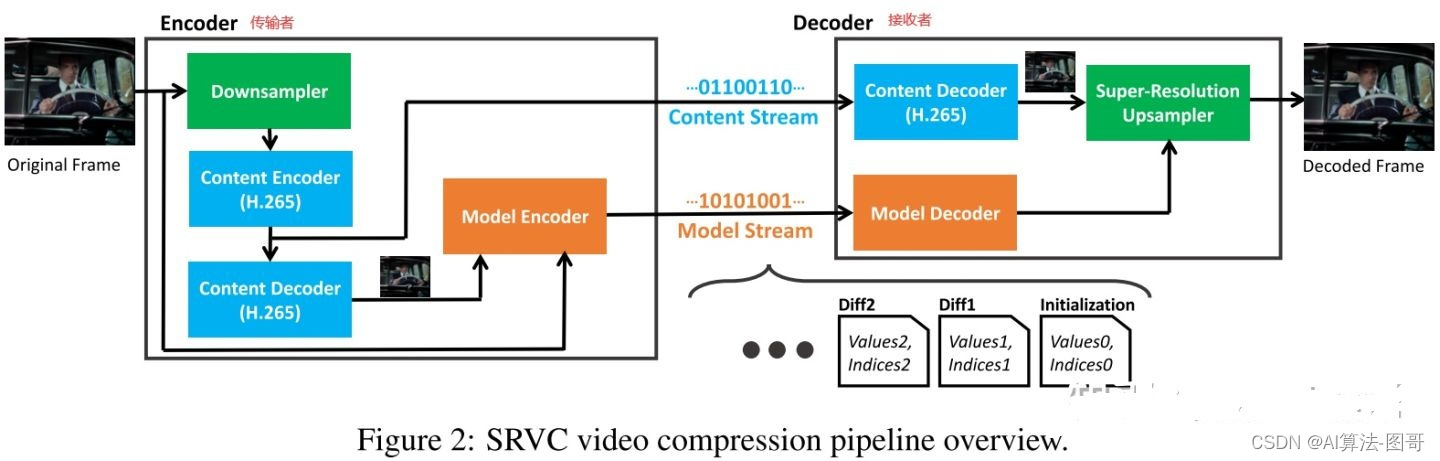
在传输视频之前要先做个准备。首先用超分的数据集(啥都可以)训练SRVC(网络结构后面讲),然后参数给传输者和接收者各一份。
视频传输开始,首先看左边的传输者。1080P的原始视频经过“Downsampler”下采样(具体算法来自一篇专利[1])变成480P(编号①),然后经过“Content Encoder”编码(压缩)视频。编码的视频一边传送给接收者(即“Content Stream”);另一边,编码的视频再经过“Content Decoder”变回480P视频(编号②,不等于①号视频,∵有损压缩),将②号视频和原始的1080P视频输入“Model Encoder”,把它们分别作为input和GT来继续训练SRVC网络(所以网络学习了编解码过程损失的信息),只对训练过程中网络梯度最大(代表影响最大)的1%的参数进行更新,并把这些参数的变化Δ,传输给接收者(即“Model Stream”)。
Model Encoder中只选取了梯度最大的1%的参数,是为了减小传输模型参数的带宽。此外,Model Encoder将输入的视频分割成了5s的视频,因此Model Stream每5s传输一次更新的参数,进一步减小了带宽。假设网络参数存储类型为Float16(16bit),网络参数量为 $M=2.210^6$ ,选取参数的比例$\eta=1%$,视频分割后时长$\tau=5s$,则传输网络参数的带宽为$(16+log(M))\eta M/ \tau \approx 1.6*10^5bit/s \approx 20KB/s$,其中, $log(M)$ 底为2,表示用二进制来表示网络中某个参数的idx
再来看接收者这边。接收者把传输者发送过来的经过编码的视频(即“Content Stream”),通过“Content Decoder”变回480P视频(编号③,等于②号视频)。此外,接收者还把传输者发过来的网络参数的变化Δ(即“Model Stream”)加到自己的SRVC上,这样传输者和接收者手里的SRVC网络的参数就都一样了。最后,接收者将③号视频(480P)用更新过的SRVC网络超分到1080P即可(即“Super-Resolution Upsampler”)。
2.3 SRVC网络结构
前面2.1节说了,SRVC的一部分原因是为了解决bicubic中kernel固定的问题。所以SRVC的步骤如下:
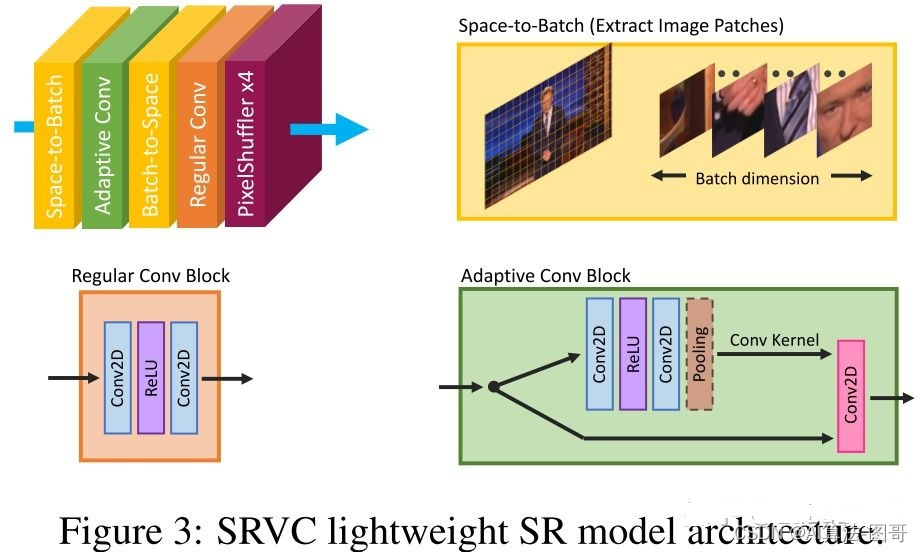
- 首先将输入的低分辨率(LR)图片,分割成了5*5像素大小的patch(“Space-to-Batch”);
- 然后对于每一个patch(即图片的local信息),通过“Adaptive Conv”学习其专有的weight(kernel和bias),再用这个weight卷积这个patch,得到这个patch的ouput feature;
- 接着,将每个patch的ouput feature按照patch分割的方法逆向拼接回去(“Batch-to-Space”)
- 最后,通过普通的卷积(“Regular Conv”)和“PixelShuffler x4”,输出高分辨率(HR)的图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号