

强化学习 (Reinforcement Learning)
详细内容
简介
根据维基百科对强化学习的定义:Reinforcement learning (RL) is an area of machine learning inspired by behaviorist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. (强化学习是机器学习领域之一,受到行为心理学的启发,主要关注智能体如何在环境中采取不同的行动,以最大限度地提高累积奖励。)
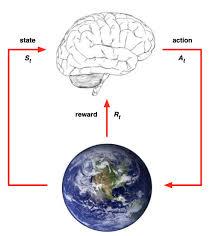
强化学习主要由智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)组成。智能体执行了某个动作后,环境将会转换到一个新的状态,对于该新的状态环境会给出奖励信号(正奖励或者负奖励)。随后,智能体根据新的状态和环境反馈的奖励,按照一定的策略执行新的动作。上述过程为智能体和环境通过状态、动作、奖励进行交互的方式。
智能体通过强化学习,可以知道自己在什么状态下,应该采取什么样的动作使得自身获得最大奖励。由于智能体与环境的交互方式与人类与环境的交互方式类似,可以认为强化学习是一套通用的学习框架,可用来解决通用人工智能的问题。因此强化学习也被称为通用人工智能的机器学习方法。
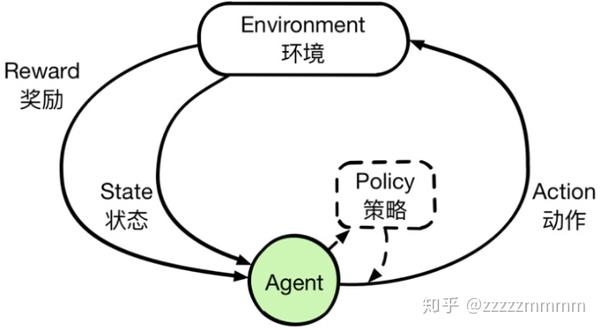
组成元素
智能体
强化学习的本体,作为学习者或者决策者。
环境
强化学习智能体以外的一切,主要由状态集合组成。
状态
一个表示环境的数据,状态集则是环境中所有可能的状态。
动作
智能体可以做出的动作,动作集则是智能体可以做出的所有动作。
奖励
智能体在执行一个动作后,获得的正/负反馈信号,奖励集则是智能体可以获得的所有反馈信息。
策略
强化学习是从环境状态到动作的映射学习,称该映射关系为策略。通俗的理解,即智能体如何选择动作的思考过程称为策略。
目标
智能体自动寻找在连续时间序列里的最优策略,而最优策略通常指最大化长期累积奖励。
因此,强化学习实际上是智能体在与环境进行交互的过程中,学会最佳决策序列。
基本框架
强化学习主要由智能体和环境组成。由于智能体与环境的交互方式与生物跟环境的交互方式类似,因此可以认为强化学习是一套通用的学习框架,是通用人工智能算法的未来。
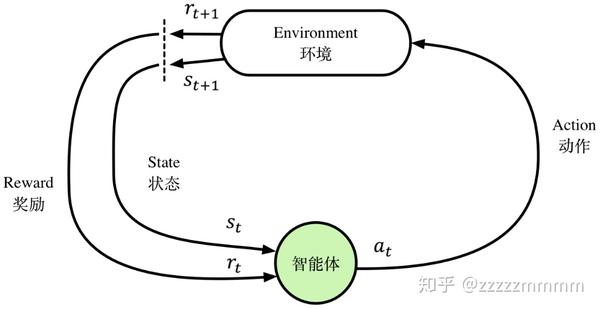
强化学习的基本框架如图所示,智能体通过状态、动作、奖励与环境进行交互。假设图1.7中环境当前处于时刻t的状态记为
上述过程的最终目的是让智能体最大化累积奖励(Cumulative Reward),公式为累积奖励G:
在上述过程中,如何根据状态
举例说明
为了更好地解释强化学习基本框架,这里给出一个简单的例子:当还是一个调皮的孩子不愿意做作业,父母就会在孩子不愿意做作业的时候就会说:“做完作业带你去麦当劳”。这时候,小孩子眼睛闪着金光,于是调皮的孩子就会为了去麦当劳乖乖地去写作业,久而久之,就会明白只有努力写作业才能获得去麦当劳的奖励。
然而事情不是总这么简单,父母对于作业完成的顺序可能会有要求,假如父母特别希望看到孩子先做完数学,然后再做语文、英语作业,如果按照父母的意愿先做完数学再做其他作业,那么就不仅能吃上炸鸡,还可以加一个雪糕。于是小孩就会学聪明点,为了吃到更多麦当劳食品,就会按照父母的意愿去先完成数学作业,再做其他作业。最后小孩不仅知道努力做作业可以获得奖励,并且为了吃到更多的麦当劳食品,改变做作业的顺序,这就相当于找到一个好的策略,能够使小孩获得最大累积奖励。
在上面的这个例子中,调皮的孩子就是智能体,父母代表环境,麦当劳的炸鸡和雪糕分别代表不同的奖励信号,小孩选择不做作业、做作业、做作业的顺序就是动作,当前作业的完成情况可以类比为状态。父母(环境)会根据孩子的作业的完成情况(当前状态)给予不同的奖励,对于不同奖励人们会采取不同的方式去做作业(选择动作),做作业并且先做数学作业就是最优策略。
强化学习就是不断地根据环境的反馈信息进行试错学习,进而调整优化自身的状态信息,其目的是为了找到最优策略、或者找到最大奖励的过程。
比较区别
2016年,由Google DeepMind开发的AlphaGo程序在人机围棋对弈中打败了韩国的围棋大师李世石。就如同1997年IBM的“深蓝”计算机战胜了国际象棋大师卡斯帕罗夫一样,媒体开始铺天盖地般地宣传人工智能时代的来临。
在介绍AlphaGo程序时,很多媒体都会把人工智能(Artificial Intelligence)、机器学习(Machine Learning)和深度强化学习混为一谈。从严格定义上来说,DeepMind在AlphaGo程序中对上述三种技术都有所使用,但使用得更多的是深度强化学习。
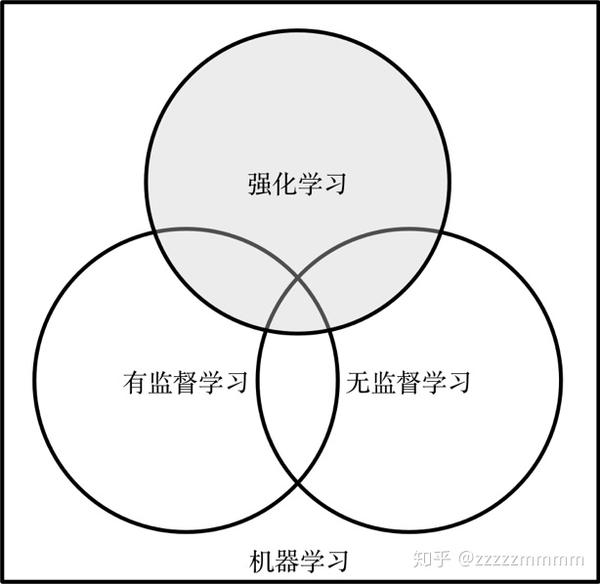
下图展示了人工智能、机器学习、深度强化学习三者之间的关系。其中人工智能包含机器学习,而强化学习则是机器学习的重要分支之一,它们三者是包含与被包含的关系,而非并列的关系。

从20世纪50年代“人工智能”这一概念第一次提出至今,人工智能的问题大致分为6个具体的方向:问题求解、知识推理、规划问题、不确定推理、通信感知与行动、学习问题。而机器学习主要分为3个方向:分类、回归、关联性分析。最后到深度强化学习则是对机器学习中的强化学习进行深度拓展。
人工智能实际上包含了日常使用到的算法。例如在问题求解方面,有A*搜索算法和a-b剪枝算法等经典算法,又如人工智能中的学习问题则包含了机器学习的大部分内容。现阶段已经有很多资料介绍机器学习相关的算法,较为著名的机器学习十大算法为:决策树、支持向量机SVM、随机森林算法、逻辑回归、朴素贝叶斯、KNN算法、K-means算法、Adaboost算法、Apriori算法、PageRank算法。
在机器学习里,其范式主要分为监督学习(Supervised Learning),无监督学习(Unsupervised Learning)和强化学习。
正如维基百科所说,强化学习是机器学习的一个分支组成部分,但是却与机器学习当中常见的监督学习和无监督学习不同。具体而言,强化学习是一种通过交互的目标导向学习方法,旨在找到连续时间序列的最优策略;监督学习是通过有标签的数据,学习规则,通常指回归、分类问题;非监督学习是通过无标签的数据,找到其中的隐藏模式,通常指聚类、降维等算法。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析