

目标检测 Fast RCNN
RCNN存在的问题:
1、一张图像上有大量的重叠框,所以这些候选框送入神经网络时候,提取特征会有冗余!
2、训练的空间需求大。因为RCNN中,独立的分类器和回归器需要很多的特征作为训练。RCNN中提取候选框,提取特征和分类回归是分开的,可独立。
Fast RCNN
针对上诉问题:
Q1:将整张图片归一化送入神经网络,在最后一层再加入候选框信息(这些候选框还是经过 提取,再经过一个
层统一映射到最后一层特征图上,而RCNN是通过拉伸来归一化尺寸),这样提取特征的前面层就不再需要重复计算。
Q2:损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。 网络结构如下:
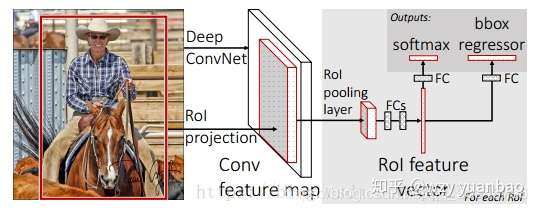
这篇论文我主要介绍 和
,这里面的
表示
。
1、ROI
正文开始之前,先了解一下:SPP空间金字塔池化(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition) SPP的作用:不管输入的尺寸大小,输出都是固定的。
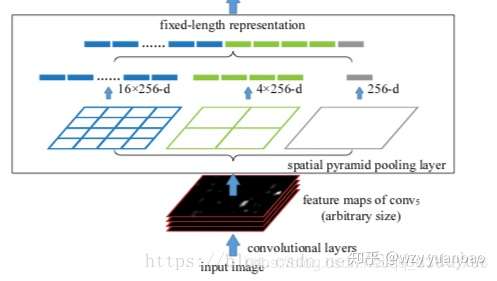
我们从上面网络结构图可以看出:最右边的不管输入是什么尺寸,每个特征图只输出一个值;中间的是不管输入什么尺寸,将特征图分为2*2个矩阵,每个矩阵取出一个值,一共有4个值;同理,最左边输出有16个值。所以不管输入特征图的大小,每一个特征图经过SPP以后都会产生16维的特征向量。
类似于SPP, 的作用有两点:
- 把图片上
选出的候选框映射到特征图上对应的位置,这个映射是根据输入图片缩小的尺寸来的;
- 将映射到
上面的
输出成统一大小的特征,因为这些框的特征区域大小不一样。
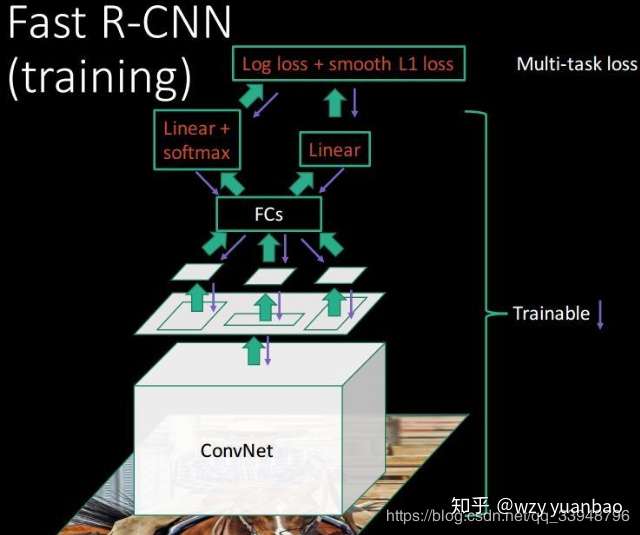
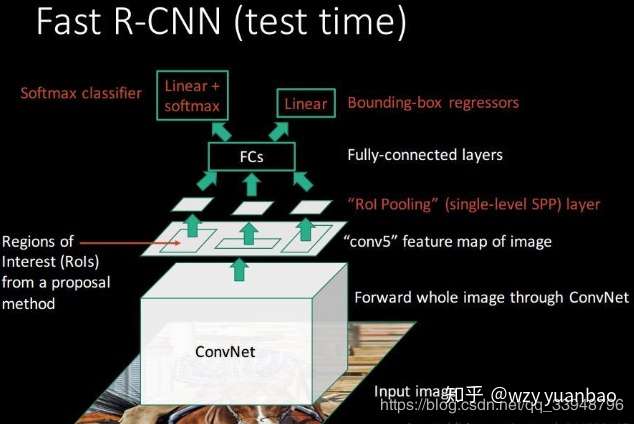
所以我们从上测试图和该层作用可以看出:
该 的输入是:
1. 提取特征的网络的最后一个特征图层;
2. 一个表示图片中所有ROI的N*5的矩阵,其中N表示 的数目。第一列表示图像
,其余四列表示坐标,坐标的参考系不是针对
这张图的,而是针对原图的(这边就是映射的坐标和索引号)。四个参数
除了尺寸参数
外,还有两个位置参数
表示RoI的左上角在整个图片中的坐标;
该 的输出是: 输出是
个vector,其中
的值等于
的个数,vector的大小为
;
的过程就是将一个个大小不同的box矩形框,在特征图上都池化成大小为
的矩形框特征;
具体步骤: ROI pooling具体操作如下:
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同); (3)对每个sections进行max pooling操作; 这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。输出的feature maps的大小不取决于ROI和卷积feature maps大小。因为加入这个神奇的 层,对每个
都提取一个固定维度的特征表示,再通过正常的
进行分类。RCNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做
,而在Fast-RCNN中,把
放进了网络内部,与
分类合并成为了一个
模型,两个任务能够共享卷积特征,并相互促进。
下面介绍上述具体步骤中的(2)和(3):
假设经过 的输出尺寸大小为:
,层之前输入的特征图尺寸大小为:
,那么该特征图所需要池化的尺寸大小为:
。
总结一下:
的输入是
的坐标和某一层的输出特征,
目的是提取输出特征图上该
坐标所对应的特征。网络得到的
坐标是针对输入图像大小的,所以首先需要将
坐标缩小到输出特征对应的大小.。
假设输出特征尺寸是输入图像的1/16,那么先将ROI坐标除以16并取整(第一次量化),然后将取整后的ROI划分成 个块,因为划分过程得到的块的坐标是浮点值,所以这里还要将块的坐标也做一个量化,具体而言对于左上角坐标采用向下取整,对于右下角坐标采用向上取整,最后采用最大池化操作处理每个块,也就是用每个块中的最大值作为该块的值,每个块都通过这样的方式得到值,最终输出的
大小的
特征。从这里的介绍可以看出
有两次量化操作,这两步量化操作会引入误差。
2、损失函数
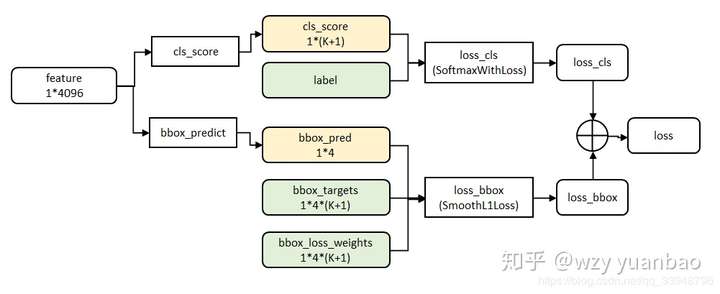
这边利用了参数共享,得到这一层的参数,做分类和回归,各不相干!如下面:
# Resnet中的两层 s = self.L2Norm_out1(out1) sources.append(s) s = self.L2Norm_out2(out2) sources.append(s) # 新添加的四层的值 out3, out4, out5, out6 = self.extras(out2) sources.append(out3) # 添加4个extra层的输出结果 sources.append(out4) sources.append(out5) sources.append(out6) # apply multibox head to source layers for (x, l, c) in zip(sources, self.loc, self.conf): loc.append(l(x).permute(0, 2, 3, 1).contiguous()) conf.append(c(x).permute(0, 2, 3, 1).contiguous()) loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1) conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1) def multiboxlayer(resnet, num_classes): num_anchor = [4, 6, 6, 6, 4, 4] # number of boxes per feature map location in_planes = [128, 512, 512, 512, 512, 512] loc_layers = [] conf_layers = [] # 取自RESNET的两层 loc_layers.append(nn.Conv2d(in_planes[0], num_anchor[0] * 4, kernel_size=3, padding=1)) loc_layers.append(nn.Conv2d(in_planes[1], num_anchor[1] * 4, kernel_size=3, padding=1)) conf_layers.append(nn.Conv2d(in_planes[0], num_anchor[0] * num_classes, kernel_size=3, padding=1)) conf_layers.append(nn.Conv2d(in_planes[1], num_anchor[1] * num_classes, kernel_size=3, padding=1)) # extra_layer中四层 for k in range(2, 6): # 因为前面两层是在VGG中用于输出location和confidence,所以从2开始 loc_layers.append(nn.Conv2d(in_planes[k], num_anchor[k] * 4, kernel_size=3, padding=1)) conf_layers.append(nn.Conv2d(in_planes[k], num_anchor[k] * num_classes, kernel_size=3, padding=1)) return resnet, (loc_layers, conf_layers)

