
kaldi与中文语音识别
kaldi是什么
kaldi是一个用C++写的语音识别工具包。kaldi旨在供语音识别研究员使用。当然,kaldi也可以用作声纹识别。关于他的详细介绍可以访问kaldi的官方文档
kaldi与中文语音识别
感谢很多大神与科研工作者在kaldi上开源了他们的数据集和训练模型,让我这样的小白可以站在巨人的肩膀上前行。目前我所了解到有3个开源的中文语音识别例子。
清华大学开源的thchs30数据集(疯狂为CSLT打电话~~~)
CVTE公司开源的CVTE Mandarin Model模型
Beijing Shell Shell Technology公司开源的aishell数据集
如果有同学知道其他的数据集or模型,中英文皆可,欢迎联系我补充啊~
编译与安装kaldi
注意:为了提高训练的速度,kaldi最好安装在GPU云服务器下。如果没有服务器话,使用虚拟机应该也是可以的,但一定要分配足够的内存空间和存储空间。下面我就以我使用的centos服务器为例,介绍kaldi的编译与安装。
编译与安装大概分为3步
安装git、下载kaldi的源码
安装编译所需依赖包
配置、编译kaldi
1.kaldi的下载
kaldi的所有源码开源在了GitHub上,可以直接git下载到服务器上,首先得确保服务器上安装了git,如果没有安装的话,就先安装git
sudo yum install git -y
接着git clone下载kaldi
git clone https://github.com/kaldi-asr/kaldi.git
下载完成kaldi源码后,我们将得到如下一个文件结构的目录。
kaldi/ ├── COPYING ├── egs/ //egs目录里存放了使用kaldi完成的开源语音识别/声纹识别项目 ├── INSTALL //编译安装kaldi的指导 ├── misc/ ├── README.md ├── scripts/ ├── src/ //src文件夹里存放了kaldi源码 ├── tools/ //tools文件夹里存放了语音处理的工具包 └── windows/ //windows文件夹存放了在windows下编译安装kaldi的文件
2.安装编译所需要的依赖包
编译之前需要确操作系统中安装有如下包
subversion automake autoconf libtool g++ zlib libatal wget sox
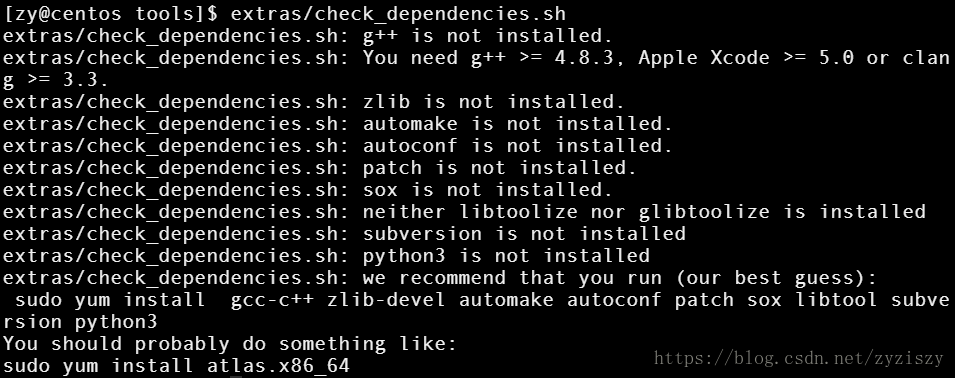
首先进入到kaldi/tools目录下,接着在调用check_dependencies.sh脚本检查系统中的包是否安装完全
cd kaldi/tools
extras/check_dependencies.sh
如图所示,这个shell脚本会提示系统需要安装的包,按照提示安装即可。
安装完成后再次运行这个脚本,如果提示OK就可以开始进行kaldi的编译。
3.编译kaldi
首先编译tools,在在kaldi/tools目录下输入
make
我使用的服务器是i7有8个核心,因此输入make -j 8可以使用8个核心一起编译,加快编译速度。
之后转到kaldi/src目录下,输入如下命令
cd ../src
在src目录下首先要运行configure进行配置,由于每个人的cuda版本、安装路径不一定相同,所以这里需要根据自己的服务器情况进行修改,如下是我的configure配置方案,仅供参考。
./configure --static \ --use-cuda=yes \ --cudatk-dir=/home/zy/cuda/cuda-8.0 \ --mathlib=OPENBLAS \ --openblas-root=../tools/OpenBLAS/install \ --threaded-math=no \ --static-math=yes \ --static-fst=yes \ --fst-root=../tools/openfst
配置完成后,就可以进行src的编译了
make depend
make
同样,如果是多核CPU的话,你可以使用make depend -j 8和make -j 8加快编译速度
完成后会有提示成功和失败,结束make后就算完成了kaldi的编译与安装了~
版权声明:本文为CSDN博主「zyziszy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zyziszy/article/details/82919957

 浙公网安备 33010602011771号
浙公网安备 33010602011771号