Tensorflow-分布式训练
一、简介
1) 使用单台机器或者单个GPU/CPU来进行模型训练,训练速度会受资源的影响,因为毕竟单个的设备的计算能力和存储能力具有一定的上限的,针对这个问题,TensorFlow支持分布式模型运算,支持多机器、多GPU、多CPU各种模型的组合运行方案的设计。(默认情况下,TensorFlow程序会将程序运行在第一个GPU上<如果有GPU,并且安装的TensorFlow支持GPU运行>)
2)TensorFlow的分布式支持单机多GPU、单机GPU+CPU、多机GPU等结构,不过所有结构的构建方式基本类似。
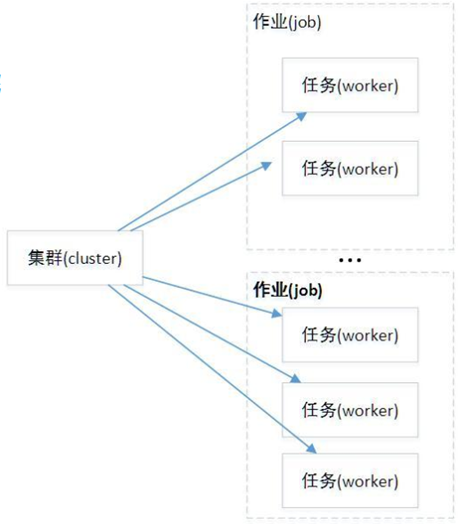
3) 除了TensorFlow外,Caffe、DeepLearning4j等也支持分布式训练,TensorFlow中的集群(Cluster)指的是一系列能够对TensorFlow中的图(graph)进行分布式计算的任务(task)。每个任务是同服务(server)相关联的。TensorFlow中的服务会包含一个用于创建session的主节点和至少一个用于图运算的工作节点。另外在TensorFlow中,一个集群可以被拆分为一个或者多个作业(job),每个作业可以包含至少一个任务。
4)cluster(集群)、job(作业)、task(任务)概念:三者可以简单的看成是层次关系,task可以看成每台机器上的一个进程,多个task组成job;job又有:ps、worker两种,分别用于参数服务、计算服务,组成cluster。
二、构建步骤
TensorFlow分布式集群的构建主要通过代码实现,主要步骤如下:
①创建集群(Cluster)
- 创建一个tf.train.ClusterSpec用于对集群中的所有任务进行描述,该描述内容对于所有内容应该是相同的。
- 创建tf.train.Server并将tf.train.ClusterSpec中参数传入构造函数,
②使用tf.device API指定运算的设备,构建计算图,最后提交运算
备注:TensorFlow负责内部作业之间的数据传输
详细见最后的实验代码。
三、实现方式
TensorFlow中主要包含两个方面
第一:对不同数据大小进行计算的任务(work作业)
第二:用于不停更新共享参数的任务(ps作业)。这样任务都可以运行不同在机器上,在TensorFlow中,主要实现方式如下:
- 图内的拷贝(In-Graph Replication)
- 图间的拷贝(Between-Graph Replication)
- 异步训练(Asynchronous Training)
- 同步训练(Synchronous Training)
3.1)在In-Graph Replication
指定整个集群由一个客户端来构建图,并且这个客户端来提交图到集群中,worker只负责处理执行任务。In-Graph模式的好处在于解耦了TensorFlow集群和训练应用之间的关系,这样可以提前构建好参数服务器和计算服务器,而这些角色本身不需要额外的逻辑代码,只需要使用join等待即可,真正的训练逻辑全部位于客户端,具有足够高的灵活性。
备注:在小规模数据集的情况下,经常使用。在海量数据的训练过程中,不建议使用该方式,建议使用Between-Graph Replication模式。
3.2)在Between-Graph Replication
每个客户端会构建一个相似的图结构,该结构中的参数均通过ps作业进行声明并使用tf.train.replica_device_setter方法将参数映射到不同的任务作业中。
3.3)Synchronous Training
在同步训练中,每个graph的副本读取相同的parameter值,并行的计算,然后将计算完的结果放到一起处理。在TensorFlow中,如果是Betweengraph replication的情况下,可以通tf.train.SyncReplicasOptimizer来处理,如果是In-graph replication情况下,直接对结果进行处理即可(比如平均).
3.4)Asynchronous Training
在异步训练中,每个任务计算完后,就会直接使用计算出的结果更新parameter值。不同的任务之间不存在协调进度。
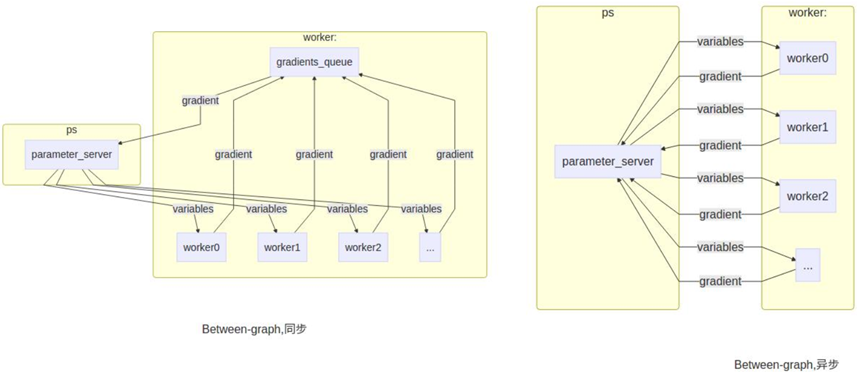
同步训练需要等待最慢的一个任务执行完后,才可用更新参数;异步训练中,可以每执行完一个任务,就更新一次参数。一般情况下,建议使用异步训练。
四、Demo演示
server-demo.py服务器代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
1 import tensorflow as tf 2 # 1. 配置服务器相关信息 3 # 因为tensorflow底层代码中,默认就是使用ps和work分别表示两类不同的工作节点 4 # ps:变量/张量的初始化、存储相关节点 5 # work: 变量/张量的计算/运算的相关节点 6 ps_hosts = ['127.0.0.1:33331', '127.0.0.1:33332'] 7 work_hosts = ['127.0.0.1:33333', '127.0.0.1:33334', '127.0.0.1:33335'] 8 cluster = tf.train.ClusterSpec({'ps': ps_hosts, 'work': work_hosts}) 9 # 2. 定义一些运行参数(在运行该python文件的时候就可以指定这些参数了)10 tf.app.flags.DEFINE_string('job_name', default_value='work', docstring="One of 'ps' or 'work'")11 tf.app.flags.DEFINE_integer('task_index', default_value=0, docstring="Index of task within the job")12 FLAGS = tf.app.flags.FLAGS13 # 2. 启动服务14 def main(_):15 print(FLAGS.job_name)16 server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)17 server.join()18 if __name__ == '__main__':19 # 底层默认会调用main方法20 tf.app.run() |
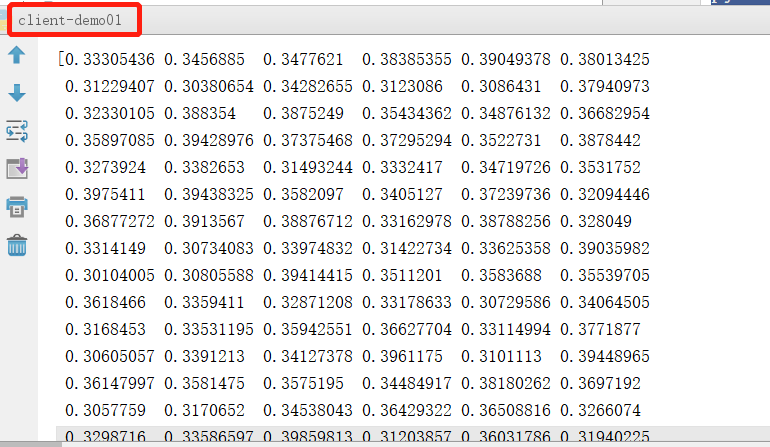
客户端代码:client-demo01
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
1 import tensorflow as tf 2 import numpy as np 3 # 1. 构建图 4 with tf.device('/job:ps/task:0'): 5 # 2. 构造数据 6 x = tf.constant(np.random.rand(100).astype(np.float32)) 7 # 3. 使用另外一个机器 8 with tf.device('/job:work/task:1'): 9 y = x * 0.1 + 0.310 # 4. 运行11 with tf.Session(target='grpc://127.0.0.1:33335',12 config=tf.ConfigProto(log_device_placement=True, allow_soft_placement=True)) as sess:13 print(sess.run(y)) |
执行:
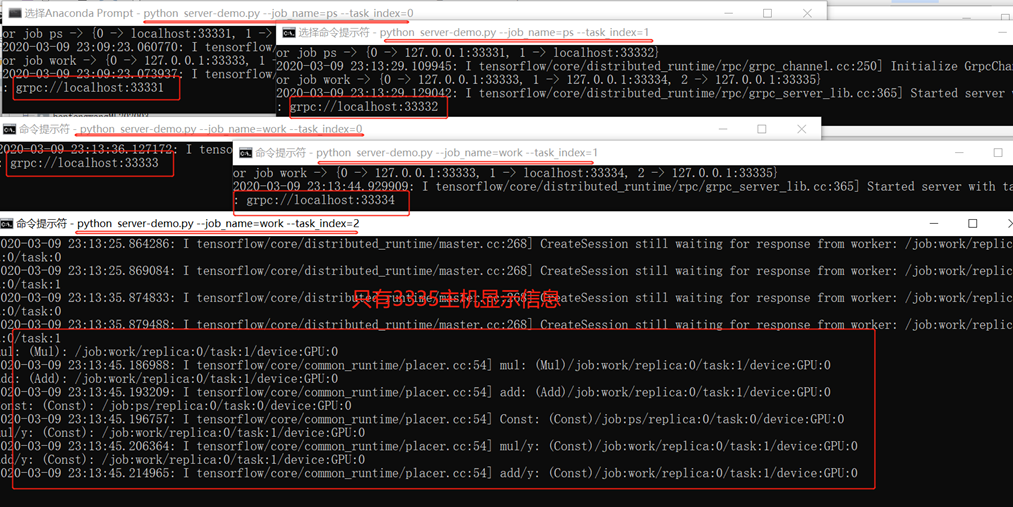
1、通过命令行,进入对应环境:我的是activate tensorflow-gpu,再进入对应server-demo.py所在文件夹,重复打开5个,分别输入(虽然最后结果只是在最后3335中显示,但是必须要全部运行,才能运算出结果):
python server-demo.py --job_name=ps --task_index=0
python server-demo.py --job_name=ps --task_index=1
python server-demo.py --job_name=work --task_index=0
python server-demo.py --job_name=work --task_index=1
python server-demo.py --job_name=work --task_index=2
2、运行客户端,最后结果如下: