
机器学习-集成学习-boosting-catboost原理
概述
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。XGBoost被广泛的应用于工业界,LightGBM有效的提升了GBDT的计算效率,而Yandex的CatBoost号称是比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
与XGBoost、LightGBM相比,CatBoost的创新点有:
- 嵌入了自动将类别型特征处理为数值型特征的创新算法。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。
- Catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
- 采用ordered boost的方法避免梯度估计的偏差,进而解决预测偏移的问题。
- 采用了完全对称树作为基模型。
原理
类别型特征
类别型特征的相关工作
所谓类别型特征,即这类特征不是数值型特征,而是离散的集合,比如省份名(山东、山西、河北等),城市名(北京、上海、深圳等),学历(本科、硕士、博士等)。在梯度提升算法中,最常用的是将这些类别型特征转为数值型来处理,一般类别型特征会转化为一个或多个数值型特征。
-
如果某个类别型特征基数比较低(low-cardinality features),即该特征的所有值去重后构成的集合元素个数比较少,一般利用One-hot编码方法将特征转为数值型。One-hot编码可以在数据预处理时完成,也可以在模型训练的时候完成,从训练时间的角度,后一种方法的实现更为高效,CatBoost对于基数较低的类别型特征也是采用后一种实现。
-
在高基数类别型特征(high cardinality features) 当中,比如 user ID,这种编码方式会产生大量新的特征,造成维度灾难。一种折中的办法是可以将类别分组成有限个的群体再进行One-hot编码。上述方法的一种常用解决方法是根据目标变量统计(Target Statistics,以下简称TS)进行分组,目标变量统计用于估算每个类别的目标变量期望值。甚至有人直接用TS作为一个新的数值型变量来代替原来的类别型变量。
重要的是,可以通过对TS数值型特征的阈值设置,基于对数损失、基尼系数或者均方差,得到一个对于训练集而言将类别一分为二的所有可能划分当中最优的那个,即对于不同的损失函数,使用TS数据能获得最有解。在LightGBM当中,类别型特征用每一步梯度提升时的梯度统计(Gradient Statistics,以下简称GS)来表示。虽然为建树提供了重要的信息,但是这种方法有以下两个缺点:
- 增加计算时间,因为需要对每一个类别型特征,在迭代的每一步,都需要对GS进行计算;
- 增加存储需求,对于一个类别型变量,需要存储每一次分离每个节点的类别;
为了克服这些缺点,LightGBM以损失部分信息为代价将所有的长尾类别归为一类,作者声称这样处理高基数类别型特征时比One-hot编码还是好不少。另外对于采用TS特征,仅仅为每个类别计算和存储一个数字。
采用TS作为一个新的数值型特征是最有效、信息损失最小的处理类别型特征的方法。TS也被广泛应用在点击预测任务当中,这个场景当中的类别型特征有用户、地区、广告、广告发布者等。
目标变量统计(Target Statistics)
-
CatBoost算法的设计初衷是为了更好的处理GBDT特征中的categorical features。在处理 GBDT特征中的categorical features的时候,最简单的方法是用 categorical feature 对应的标签的平均值来替换。在决策树中,标签平均值将作为节点分裂的标准。这种方法被称为 Greedy Target-based Statistics , 简称 Greedy TS,用公式来表达就是:
xi,k=j=1∑n[xj,k=xi,k]j=1∑n[xj,k=xi,k]⋅Yj
这种方法有一个显而易见的缺陷,就是通常特征比标签包含更多的信息,如果强行用标签的平均值来表示特征的话,当训练数据集和测试数据集数据结构和分布不一样的时候会出条件偏移问题。 -
一个标准的改进 Greedy TS的方式是添加先验分布项,这样可以减少噪声和低频率类别型数据对于数据分布的影响
xi,k=j=1∑p−1[xσj,k=xσp,k]+aj=1∑p−1[xσj,k=xσp,k]⋅Yj+a⋅p
其中p是添加的先验项,a通常是大于0的权重系数。添加先验项是一个普遍做法,针对类别数较少的特征,它可以减少噪声数据。。对于回归问题,一般情况下,先验项可取数据集label的均值。对于二分类,先验项是正例的先验概率。
当然,在论文《CatBoost: unbiased boosting with categorical features》中,还提到了其它几种改进Greedy TS的方法,分别有:Holdout TS、Leave-one-out TS、Ordered TS。我这里就不再翻译论文中的这些方法了,感兴趣的同学可以自己翻看一下原论文。
- Ordered TS
它是catboost的主要思想,依赖于排序,受online learning algorithms的启发得到,对于某一个样本,TS的值依赖于观测历史,为了在离线的数据上应用该思想,我们将数据随机排序,对于每一个样本,利用该样本之前数据计算该样本类别值的TS值。如果仅仅使用一个随机序列,那么计算得到值会有较大的方差,因此我们使用不同的随机序列来计算。
CatBoost处理Categorical features总结
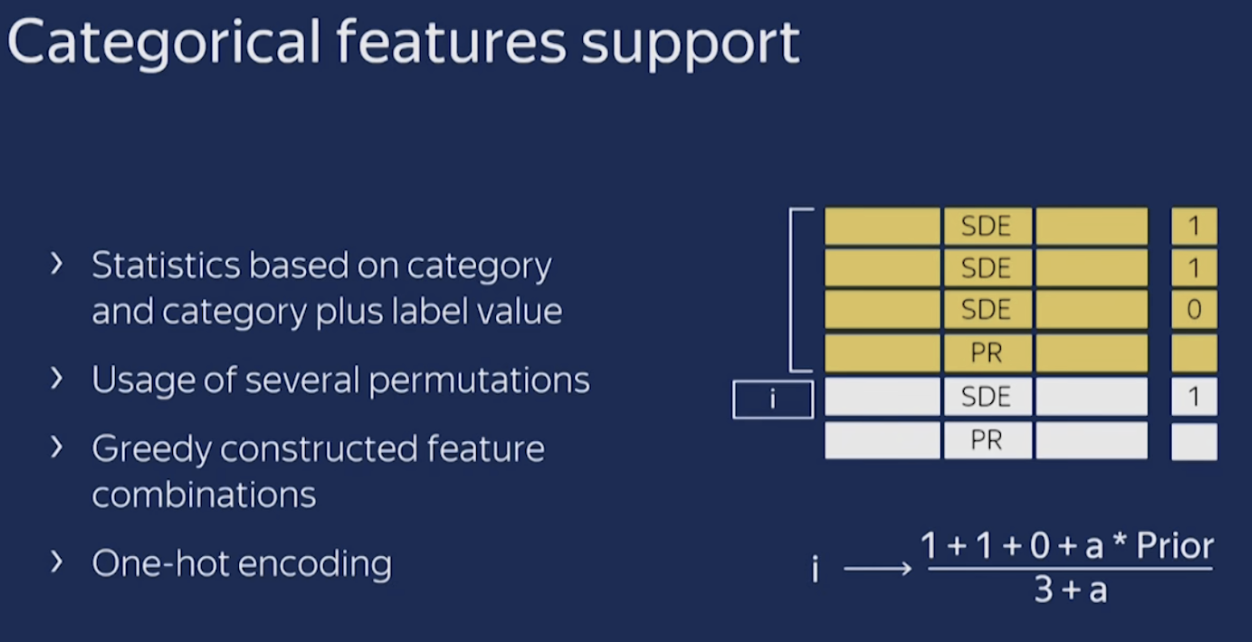
- 首先会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是之后全是这种方式),训练之前需要打乱数据集。
- 第二,使用数据的不同排列。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。
- 第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的特征。当需要组合的categorical features变多时,CatBoost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个特征,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。
- 第四,除非向gender这种维数很小的情况,不建议自己生成One-hot编码向量,最好交给算法来处理。
![]()
梯度偏差/预测偏移
- 为什么会有梯度偏差?
- 梯度偏差造成了什么问题?
- 如何解决梯度偏差?
为什么会有梯度偏差?
CatBoost和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。在每个步骤中使用的梯度都使用当前模型中的相同的数据点来估计,这导致估计梯度在特征空间的任何域中的分布与该域中梯度的真实分布相比发生了偏移。
梯度偏差造成了什么问题?
模型过拟合,预测发生偏移。另外预测偏移还有当我们利用TS来处理类别特征时,引起的target leak的问题。
如何解决梯度偏差/预测偏移?
为了解决这个问题,CatBoost对经典的梯度提升算法进行了一些改进,简要介绍如下:
许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建下一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度或牛顿步长的近似值来计算。
在CatBoost中,第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。既然原来的梯度估计是有偏的,那么怎么能改成无偏估计呢?
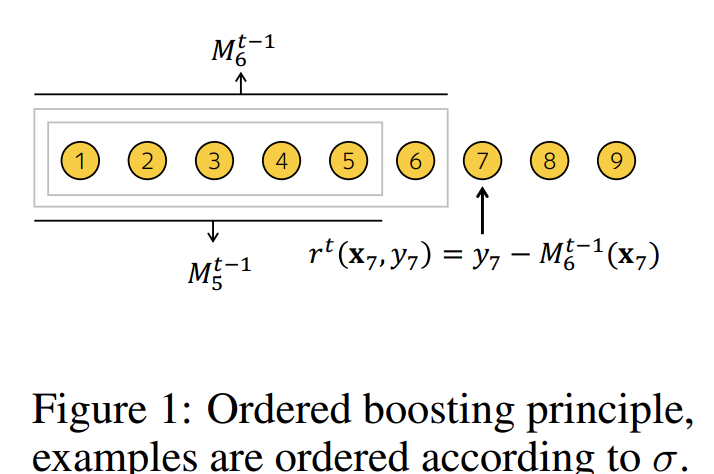
设Fi为构建i棵树后的模型, gi(Xk,yk)为构建i棵树后第k个训练样本上面的梯度值。为了使得gi(Xk,yk)无偏于模型Fi,我们需要在没有Xk参与的情况下对模型Fi进行训练。我们需要对所有训练样本计算无偏的梯度估计
我们可以运用下面这个技巧来处理这个问题:对于每一个样本Xk,我们训练一个单独的模型Mk(该模型由多颗树组成),且该模型从不使用基于该样本的梯度估计进行更新。我们使用Mk估计上Xk的梯度(即叶子节点的值),并使用这个估计对结果树进行评分。用伪码描述如下,其中Loss(yi,a)是需要优化的损失函数,y是标签值,a是公式计算值。

值得注意的是模型的建立并没有 Xi 样本的参与,并且CatBoost中所有的树的共享同样的结构。Mi(Xi)表示模型Mi对Xi进行打分。
这里为了进一步减少过拟合,会使用若干不同对扰动来加强算法鲁棒性。也即上述提到对用于计算类别特征的方法,我们获取s个随机扰动排列,对于每个排列,我们又训练n个不同的模型Mi,这样模型模型复杂度为O(sn2),后续进行优化,具体见算法流程部分;
其他
特征组合
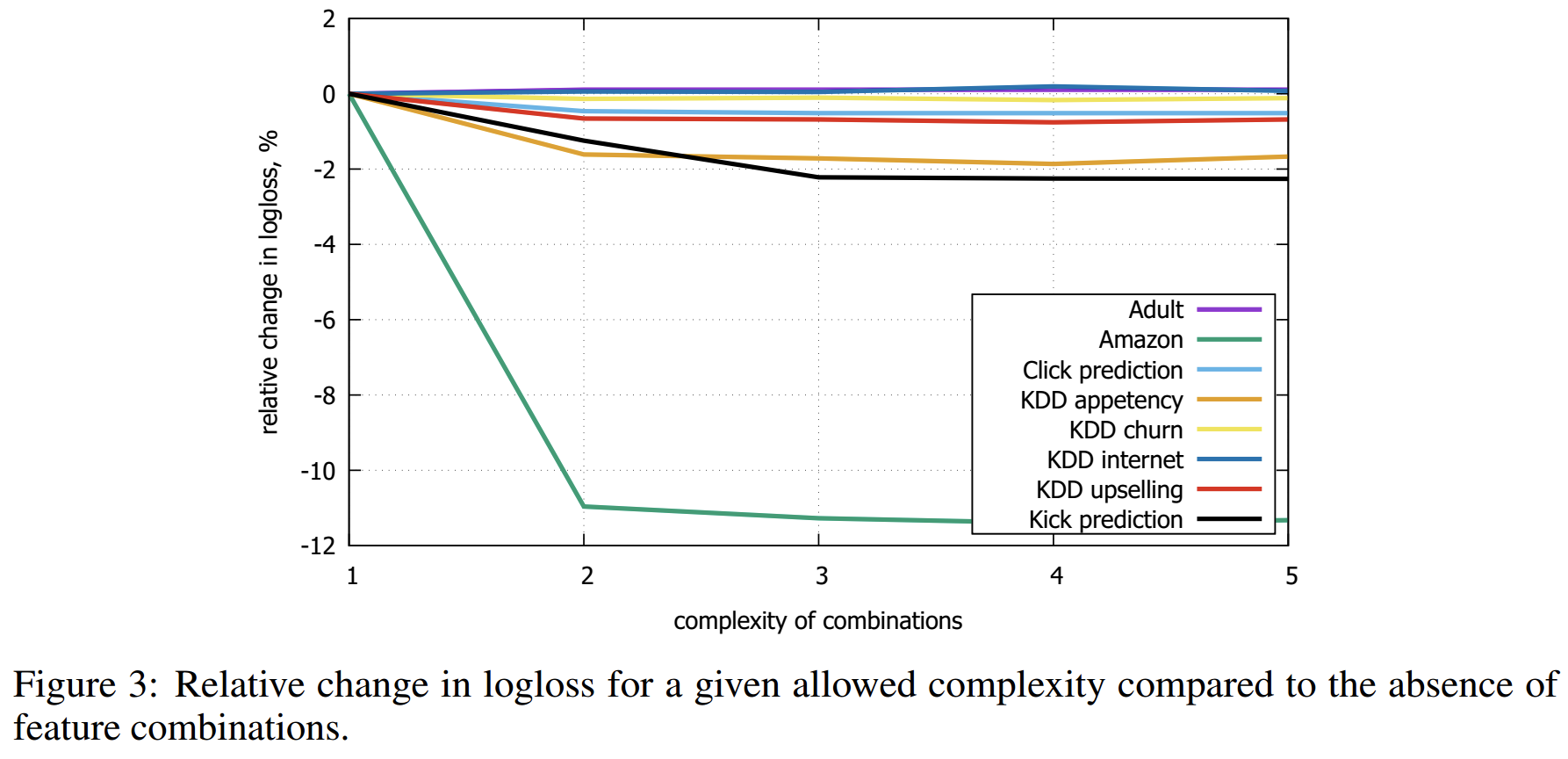
CatBoost的另外一项重要实现是将不同类别型特征的组合作为新的特征,以获得高阶依赖(high-order dependencies),比如在广告点击预测当中用户ID与广告话题之间的联合信息,又或者在音乐推荐引用当中,用户ID和音乐流派,如果有些用户更喜欢摇滚乐,那么将用户ID和音乐流派分别转换为数字特征时,这种用户内在的喜好信息就会丢失。然而,组合的数量会随着数据集中类别型特征的数量成指数增长,因此在算法中考虑所有组合是不现实的。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合,并将新的组合类别型特征动态地转换为数值型特征。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树中选定的所有分割点都被视为具有两个值的类别型特征,并像类别型特征一样地被进行组合考虑。
当特征组合由原始的1到2时,logloss的logloss部分提升(logloss实际数值降低的)为1.86%,从1到3提升2.04%
快速评分
CatBoost使用对称树(oblivious trees)作为基预测器。在这类树中,相同的分割准则在树的整个一层上使用。这种树是平衡的,不太容易过拟合。梯度提升对称树被成功地用于各种学习任务中。在对称树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。这在CatBoost模型评估器中得到了广泛的应用:我们首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
基于GPU实现快速训练
密集的数值特征。 对于任何GBDT算法而言,最大的难点之一就是搜索最佳分割。尤其是对于密集的数值特征数据集来说,该步骤是建立决策树时的主要计算负担。CatBoost使用oblivious 决策树作为基模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
类别型特征。 CatBoost实现了多种处理类别型特征的方法,并使用完美哈希来存储类别型特征的值,以减少内存使用。由于GPU内存的限制,在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。通过哈希来分组观察。在每个组中,我们需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元实现。
多GPU支持。 CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算类别型特征的统计数据。
算法流程
建树的流程:
开始阶段:CatBoost对训练集随机生成s+1个不同对序列,其中σ1,σ2,...,σn用于定义树结构,分裂节点的计算。σ0用于对生成树结构选择叶子节点对值。
对于测试集合,我们根据整个训练集的TS计算相应类别的值
在catboost中,基分类器是对称树,该类树平衡,能够减弱过拟合,加速预测,整体流程为:


- ordered boosting
ordered boosting解决类类别处理及梯度偏差引起的预测偏移问题, 开始提到的方法会训练n个模型,这也会n倍地增加了时间复杂度,为了简化,我们优化其时间复杂度,仅仅储存和计算Mr,j′(i):=M,2j其中j=1,...,[log2n], 满足σr(i)≤2j+1的i,这样总体时间复杂度由O(sn2)转化为O(sn):

总结
优点
- 性能卓越: 在性能方面可以匹敌任何先进的机器学习算法;
- 鲁棒性/强健性: 无需调参即可获得较高的模型质量,采用默认参数就可以获得非常好的结果,减少在调参上面花的时间,减少了对很多超参数调优的需求
- 易于使用: 提供与scikit集成的Python接口,以及R和命令行界面;
- 实用: 可以处理类别型、数值型特征,支持类别型变量,无需对非数值型特征进行预处理
- 可扩展: 支持自定义损失函数;
- 快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行提高准确性,
- 快速预测:即便应对延时非常苛刻的任务也能够快速高效部署模型
缺点
- 对于类别型特征的处理需要大量的内存和时间;
- 不同随机数的设定对于模型预测结果有一定的影响;
Ref:
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. arXiv:1706.09516 [cs] (2017).
- Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: gradient boosting with categorical features support.
- CatBoost算法梳理
- 深入理解catboost
- https://blog.csdn.net/chencas/article/details/104418476/
catboost原理



概述
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。XGBoost被广泛的应用于工业界,LightGBM有效的提升了GBDT的计算效率,而Yandex的CatBoost号称是比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
与XGBoost、LightGBM相比,CatBoost的创新点有:
- 嵌入了自动将类别型特征处理为数值型特征的创新算法。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。
- Catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
- 采用ordered boost的方法避免梯度估计的偏差,进而解决预测偏移的问题。
- 采用了完全对称树作为基模型。
原理
类别型特征
类别型特征的相关工作
所谓类别型特征,即这类特征不是数值型特征,而是离散的集合,比如省份名(山东、山西、河北等),城市名(北京、上海、深圳等),学历(本科、硕士、博士等)。在梯度提升算法中,最常用的是将这些类别型特征转为数值型来处理,一般类别型特征会转化为一个或多个数值型特征。
-
如果某个类别型特征基数比较低(low-cardinality features),即该特征的所有值去重后构成的集合元素个数比较少,一般利用One-hot编码方法将特征转为数值型。One-hot编码可以在数据预处理时完成,也可以在模型训练的时候完成,从训练时间的角度,后一种方法的实现更为高效,CatBoost对于基数较低的类别型特征也是采用后一种实现。
-
在高基数类别型特征(high cardinality features) 当中,比如 user ID,这种编码方式会产生大量新的特征,造成维度灾难。一种折中的办法是可以将类别分组成有限个的群体再进行One-hot编码。上述方法的一种常用解决方法是根据目标变量统计(Target Statistics,以下简称TS)进行分组,目标变量统计用于估算每个类别的目标变量期望值。甚至有人直接用TS作为一个新的数值型变量来代替原来的类别型变量。
重要的是,可以通过对TS数值型特征的阈值设置,基于对数损失、基尼系数或者均方差,得到一个对于训练集而言将类别一分为二的所有可能划分当中最优的那个,即对于不同的损失函数,使用TS数据能获得最有解。在LightGBM当中,类别型特征用每一步梯度提升时的梯度统计(Gradient Statistics,以下简称GS)来表示。虽然为建树提供了重要的信息,但是这种方法有以下两个缺点:
- 增加计算时间,因为需要对每一个类别型特征,在迭代的每一步,都需要对GS进行计算;
- 增加存储需求,对于一个类别型变量,需要存储每一次分离每个节点的类别;
为了克服这些缺点,LightGBM以损失部分信息为代价将所有的长尾类别归为一类,作者声称这样处理高基数类别型特征时比One-hot编码还是好不少。另外对于采用TS特征,仅仅为每个类别计算和存储一个数字。
采用TS作为一个新的数值型特征是最有效、信息损失最小的处理类别型特征的方法。TS也被广泛应用在点击预测任务当中,这个场景当中的类别型特征有用户、地区、广告、广告发布者等。
目标变量统计(Target Statistics)
-
CatBoost算法的设计初衷是为了更好的处理GBDT特征中的categorical features。在处理 GBDT特征中的categorical features的时候,最简单的方法是用 categorical feature 对应的标签的平均值来替换。在决策树中,标签平均值将作为节点分裂的标准。这种方法被称为 Greedy Target-based Statistics , 简称 Greedy TS,用公式来表达就是:
xi,k=j=1∑n[xj,k=xi,k]j=1∑n[xj,k=xi,k]⋅Yj
这种方法有一个显而易见的缺陷,就是通常特征比标签包含更多的信息,如果强行用标签的平均值来表示特征的话,当训练数据集和测试数据集数据结构和分布不一样的时候会出条件偏移问题。 -
一个标准的改进 Greedy TS的方式是添加先验分布项,这样可以减少噪声和低频率类别型数据对于数据分布的影响
xi,k=j=1∑p−1[xσj,k=xσp,k]+aj=1∑p−1[xσj,k=xσp,k]⋅Yj+a⋅p
其中p是添加的先验项,a通常是大于0的权重系数。添加先验项是一个普遍做法,针对类别数较少的特征,它可以减少噪声数据。。对于回归问题,一般情况下,先验项可取数据集label的均值。对于二分类,先验项是正例的先验概率。
当然,在论文《CatBoost: unbiased boosting with categorical features》中,还提到了其它几种改进Greedy TS的方法,分别有:Holdout TS、Leave-one-out TS、Ordered TS。我这里就不再翻译论文中的这些方法了,感兴趣的同学可以自己翻看一下原论文。
- Ordered TS
它是catboost的主要思想,依赖于排序,受online learning algorithms的启发得到,对于某一个样本,TS的值依赖于观测历史,为了在离线的数据上应用该思想,我们将数据随机排序,对于每一个样本,利用该样本之前数据计算该样本类别值的TS值。如果仅仅使用一个随机序列,那么计算得到值会有较大的方差,因此我们使用不同的随机序列来计算。
CatBoost处理Categorical features总结
- 首先会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是之后全是这种方式),训练之前需要打乱数据集。
- 第二,使用数据的不同排列。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。
- 第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的特征。当需要组合的categorical features变多时,CatBoost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个特征,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。
- 第四,除非向gender这种维数很小的情况,不建议自己生成One-hot编码向量,最好交给算法来处理。
![]()
梯度偏差/预测偏移
- 为什么会有梯度偏差?
- 梯度偏差造成了什么问题?
- 如何解决梯度偏差?
为什么会有梯度偏差?
CatBoost和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。在每个步骤中使用的梯度都使用当前模型中的相同的数据点来估计,这导致估计梯度在特征空间的任何域中的分布与该域中梯度的真实分布相比发生了偏移。
梯度偏差造成了什么问题?
模型过拟合,预测发生偏移。另外预测偏移还有当我们利用TS来处理类别特征时,引起的target leak的问题。
如何解决梯度偏差/预测偏移?
为了解决这个问题,CatBoost对经典的梯度提升算法进行了一些改进,简要介绍如下:
许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建下一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度或牛顿步长的近似值来计算。
在CatBoost中,第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。既然原来的梯度估计是有偏的,那么怎么能改成无偏估计呢?
设Fi为构建i棵树后的模型, gi(Xk,yk)为构建i棵树后第k个训练样本上面的梯度值。为了使得gi(Xk,yk)无偏于模型Fi,我们需要在没有Xk参与的情况下对模型Fi进行训练。我们需要对所有训练样本计算无偏的梯度估计
我们可以运用下面这个技巧来处理这个问题:对于每一个样本Xk,我们训练一个单独的模型Mk(该模型由多颗树组成),且该模型从不使用基于该样本的梯度估计进行更新。我们使用Mk估计上Xk的梯度(即叶子节点的值),并使用这个估计对结果树进行评分。用伪码描述如下,其中Loss(yi,a)是需要优化的损失函数,y是标签值,a是公式计算值。
值得注意的是模型的建立并没有 Xi 样本的参与,并且CatBoost中所有的树的共享同样的结构。Mi(Xi)表示模型Mi对Xi进行打分。
这里为了进一步减少过拟合,会使用若干不同对扰动来加强算法鲁棒性。也即上述提到对用于计算类别特征的方法,我们获取s个随机扰动排列,对于每个排列,我们又训练n个不同的模型Mi,这样模型模型复杂度为O(sn2),后续进行优化,具体见算法流程部分;
其他
特征组合
CatBoost的另外一项重要实现是将不同类别型特征的组合作为新的特征,以获得高阶依赖(high-order dependencies),比如在广告点击预测当中用户ID与广告话题之间的联合信息,又或者在音乐推荐引用当中,用户ID和音乐流派,如果有些用户更喜欢摇滚乐,那么将用户ID和音乐流派分别转换为数字特征时,这种用户内在的喜好信息就会丢失。然而,组合的数量会随着数据集中类别型特征的数量成指数增长,因此在算法中考虑所有组合是不现实的。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合,并将新的组合类别型特征动态地转换为数值型特征。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树中选定的所有分割点都被视为具有两个值的类别型特征,并像类别型特征一样地被进行组合考虑。
当特征组合由原始的1到2时,logloss的logloss部分提升(logloss实际数值降低的)为1.86%,从1到3提升2.04%
快速评分
CatBoost使用对称树(oblivious trees)作为基预测器。在这类树中,相同的分割准则在树的整个一层上使用。这种树是平衡的,不太容易过拟合。梯度提升对称树被成功地用于各种学习任务中。在对称树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。这在CatBoost模型评估器中得到了广泛的应用:我们首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
基于GPU实现快速训练
密集的数值特征。 对于任何GBDT算法而言,最大的难点之一就是搜索最佳分割。尤其是对于密集的数值特征数据集来说,该步骤是建立决策树时的主要计算负担。CatBoost使用oblivious 决策树作为基模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
类别型特征。 CatBoost实现了多种处理类别型特征的方法,并使用完美哈希来存储类别型特征的值,以减少内存使用。由于GPU内存的限制,在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。通过哈希来分组观察。在每个组中,我们需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元实现。
多GPU支持。 CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算类别型特征的统计数据。
算法流程
建树的流程:
开始阶段:CatBoost对训练集随机生成s+1个不同对序列,其中σ1,σ2,...,σn用于定义树结构,分裂节点的计算。σ0用于对生成树结构选择叶子节点对值。
对于测试集合,我们根据整个训练集的TS计算相应类别的值
在catboost中,基分类器是对称树,该类树平衡,能够减弱过拟合,加速预测,整体流程为:
- ordered boosting
ordered boosting解决类类别处理及梯度偏差引起的预测偏移问题, 开始提到的方法会训练n个模型,这也会n倍地增加了时间复杂度,为了简化,我们优化其时间复杂度,仅仅储存和计算Mr,j′(i):=M,2j其中j=1,...,[log2n], 满足σr(i)≤2j+1的i,这样总体时间复杂度由O(sn2)转化为O(sn):
总结
优点
- 性能卓越: 在性能方面可以匹敌任何先进的机器学习算法;
- 鲁棒性/强健性: 无需调参即可获得较高的模型质量,采用默认参数就可以获得非常好的结果,减少在调参上面花的时间,减少了对很多超参数调优的需求
- 易于使用: 提供与scikit集成的Python接口,以及R和命令行界面;
- 实用: 可以处理类别型、数值型特征,支持类别型变量,无需对非数值型特征进行预处理
- 可扩展: 支持自定义损失函数;
- 快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行提高准确性,
- 快速预测:即便应对延时非常苛刻的任务也能够快速高效部署模型
缺点
- 对于类别型特征的处理需要大量的内存和时间;
- 不同随机数的设定对于模型预测结果有一定的影响;
Ref:
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. arXiv:1706.09516 [cs] (2017).
- Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: gradient boosting with categorical features support.
- CatBoost算法梳理
- 深入理解catboost

 浙公网安备 33010602011771号
浙公网安备 33010602011771号