
Python - ^在正则表达式中的作用
转自高手:https://www.cnblogs.com/ddzj01/p/10927054.html
^在正则表达式中有两个作用,一是表达以什么开头,二是表达对什么取反。有时候经常傻傻的分不清楚,接下来给大家详细介绍该怎么用这个^
准备一个python文件test.py,借用re.search函数举例说明

# coding=utf-8
import re
s = ['abc-123-cba', #'abc'在最前面
'123-abc-aabbcc-123', #'abc'在中间
'a-2-3-b-1', #最前面是'a'
'b-x-c-a-1', #最前面是'b'
'z-a-1', #'a'在中间
'x-y-z', #字符串没有任何'a','b','c'
'cbaabc' #字符串全是'a','b','c'组成
]
st = r'abc'
for i in s:
m = re.search(st, i)
if m:
print(i)
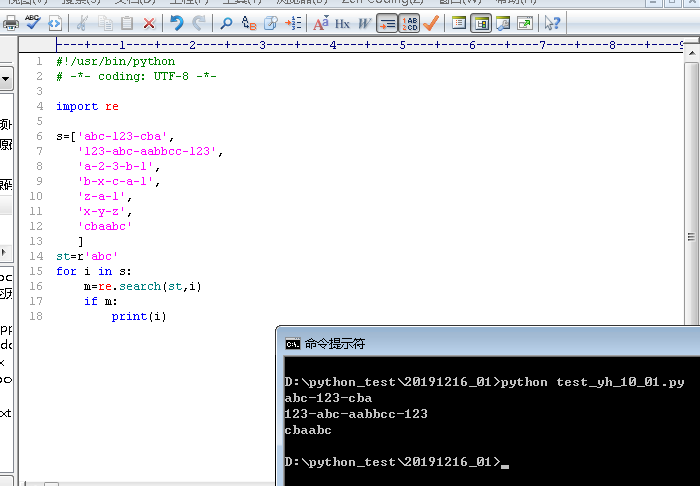
1.当st = r'abc'时,执行python文件得到的结果如下
abc-123-cba
123-abc-aabbcc-123
cbaabc
字符串中有'abc'就匹配成功
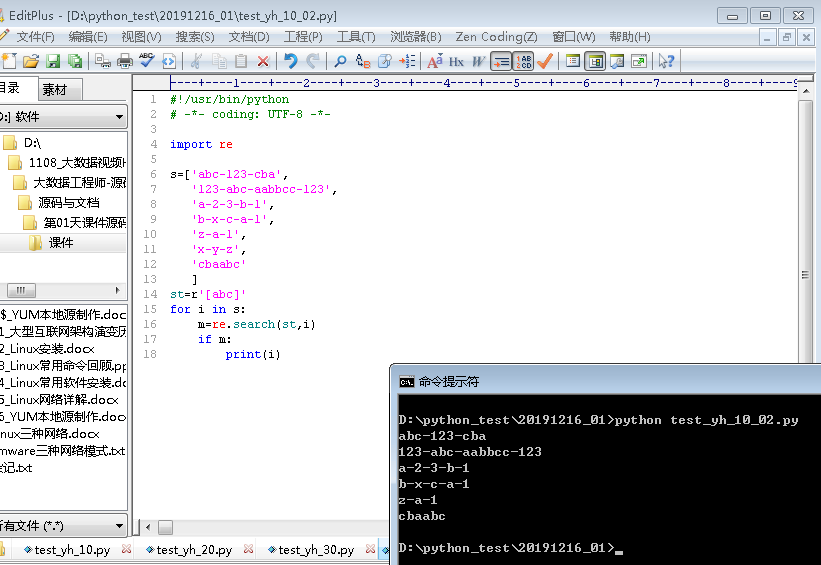
2.当st = r'[abc]'时,执行python文件得到的结果如下
abc-123-cba
123-abc-aabbcc-123
a-2-3-b-1
b-x-c-a-1
z-a-1
cbaabc
字符串中只要有'a'或'b'或'c',就匹配出来
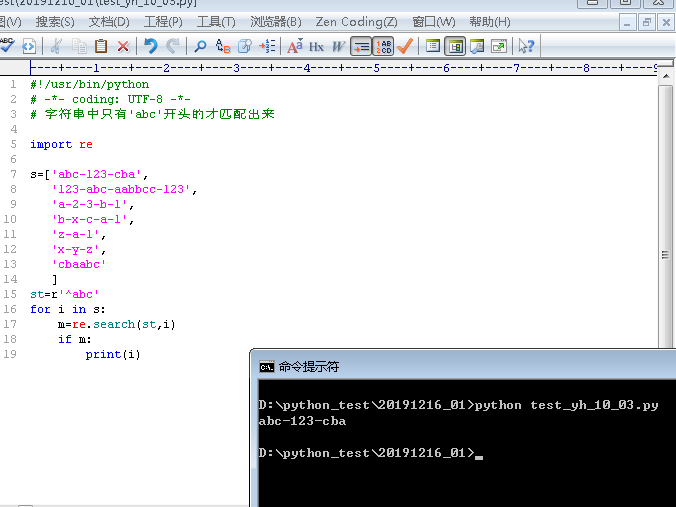
3.当st = r'^abc'时,执行python文件得到的结果如下
abc-123-cba
字符串中只有'abc'开头的才匹配出来
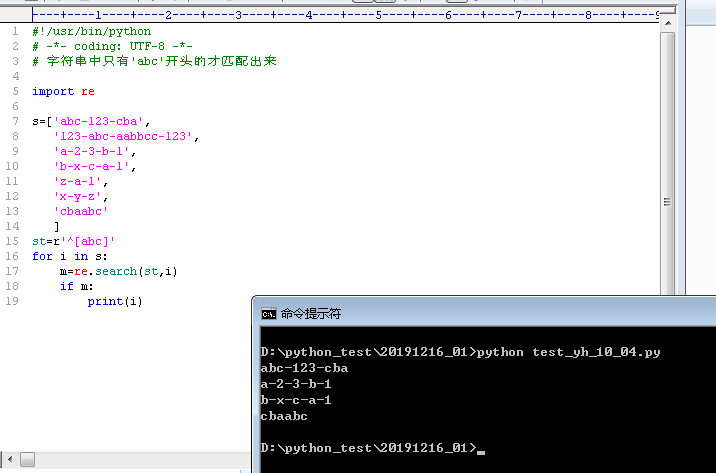
4.当st = '^[abc]'时,执行python文件得到的结果如下
abc-123-cba
a-2-3-b-1
b-x-c-a-1
cbaabc
字符串由'a'或'b'或'c'开头的都匹配出来了
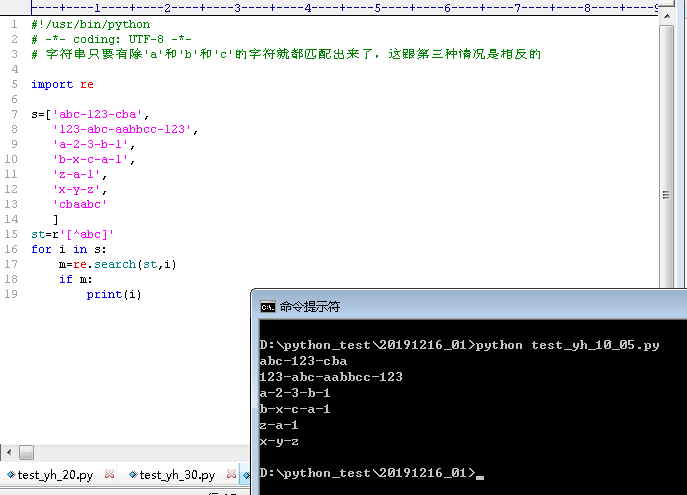
5.当st = '[^abc]'时,执行python文件得到的结果如下
abc-123-cba
123-abc-aabbcc-123
a-2-3-b-1
b-x-c-a-1
z-a-1
x-y-z
字符串只要有除'a'和'b'和'c'的字符就都匹配出来了,这跟第三种情况是相反的
总结:
'abc'表示字符串中有'abc'就匹配成功
'[abc]'表示字符串中有'a'或'b'或'c'就匹配成功
'^abc'表示字符串由'abc'开头就匹配成功
'^[abc]'表示字符串由'a'或'b'或'c'开头的,
'[^abc]'表示匹配'a','b','c'之外的字符。如果一个字符串是由'a','b','c'组合起来的,那就是假
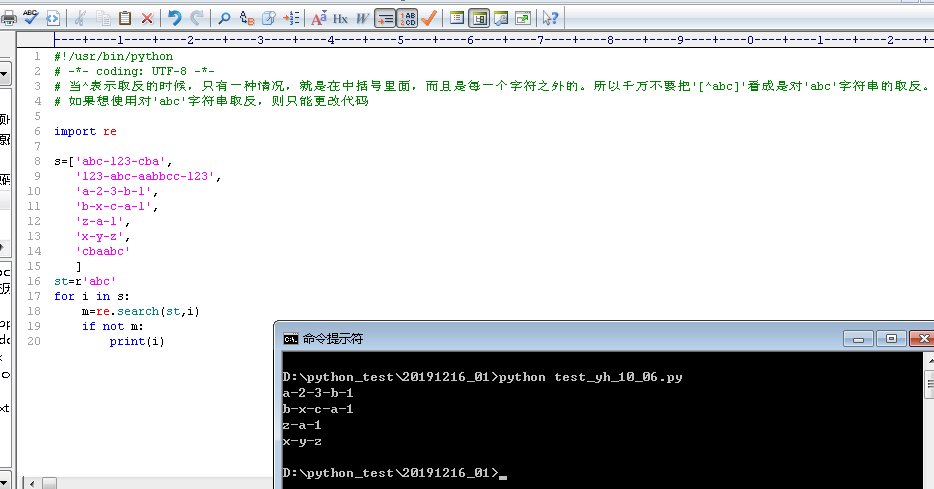
当^表示取反的时候,只有一种情况,就是在中括号里面,而且是每一个字符之外的。所以千万不要把'[^abc]'看成是对'abc'字符串的取反。
如果想使用对'abc'字符串取反,则只能更改代码
st = r'abc'
for i in s:
m = re.search(st, i)
if not m
列举常用的取反:
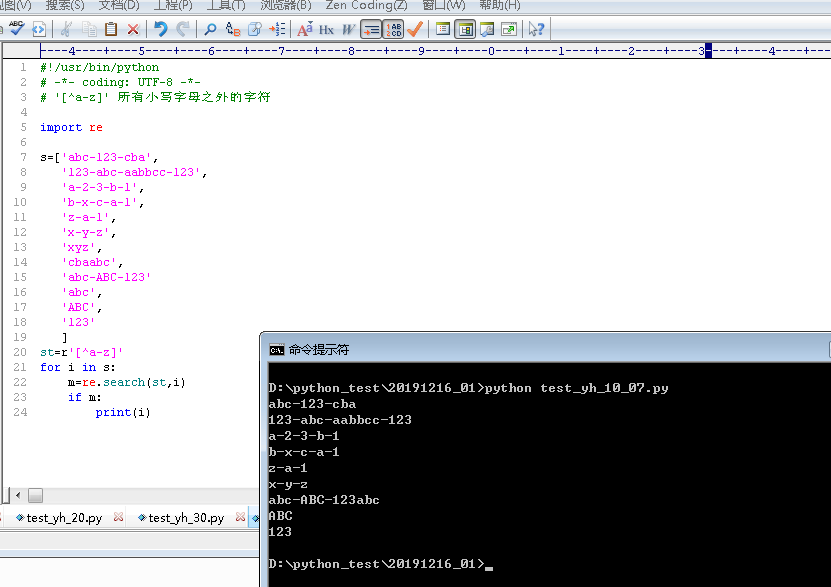
(一)、'[^a-z]' 所有小写字母之外的字符
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# '[^a-z]' 所有小写字母之外的字符
import re
s=['abc-123-cba',
'123-abc-aabbcc-123',
'a-2-3-b-1',
'b-x-c-a-1',
'z-a-1',
'x-y-z',
'xyz',
'cbaabc',
'abc-ABC-123'
'abc',
'ABC',
'123'
]
st=r'[^a-z]'
for i in s:
m=re.search(st,i)
if m:
print(i)
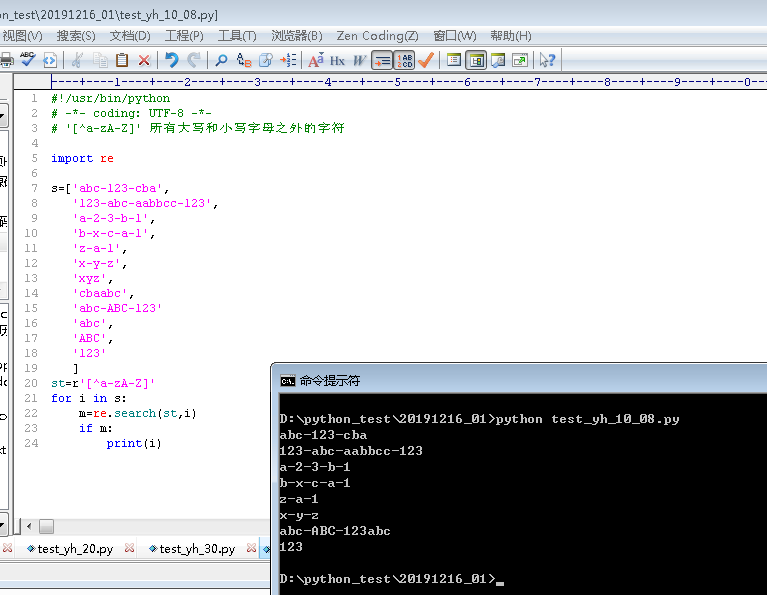
(二)、'[^a-zA-Z]' 所有大写和小写字母之外的字符
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# '[^a-zA-Z]' 所有大写和小写字母之外的字符
import re
s=['abc-123-cba',
'123-abc-aabbcc-123',
'a-2-3-b-1',
'b-x-c-a-1',
'z-a-1',
'x-y-z',
'xyz',
'cbaabc',
'abc-ABC-123'
'abc',
'ABC',
'123'
]
st=r'[^a-zA-Z]'
for i in s:
m=re.search(st,i)
if m:
print(i)
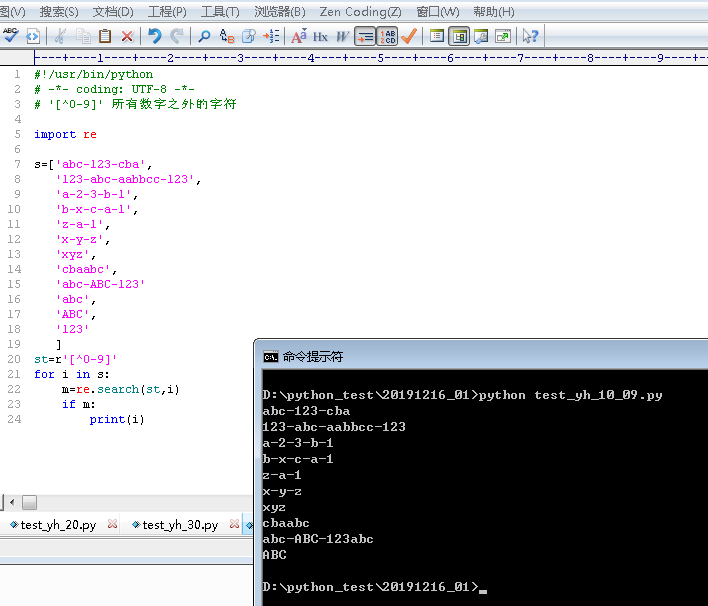
(三)、'[^0-9]' 所有数字之外的字符
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# '[^0-9]' 所有数字之外的字符
import re
s=['abc-123-cba',
'123-abc-aabbcc-123',
'a-2-3-b-1',
'b-x-c-a-1',
'z-a-1',
'x-y-z',
'xyz',
'cbaabc',
'abc-ABC-123'
'abc',
'ABC',
'123'
]
st=r'[^0-9]'
for i in s:
m=re.search(st,i)
if m:
print(i)
如果文章有错误,还望您指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号