
轻量级网络设计
主要根据具体任务的数据集特点以及相关评价指标来确定一个网络结构的输入图像分辨率,深度,每一层宽度,拓扑结构等细节
大部分的论文基于imagenet这种公开数据集进行通用网络结构设计,早期只是通过分类精度来证明设计的优劣,后期进行网络参数量(Params)和计算量(FLOPs)的对比,因为基于imagenet这种大型数据集进行训练的模型具有一定的泛化能力,所以在其他视觉任务中有一定的性能保证,但是在实际应用中,还是要结合已公开发表的优秀网络结构和任务特点适当进行修改得到自己需要的模型结构.
一般部署在边缘设备上的网络需要轻量级的网络结构,因此目前最好的办法是直接设计轻量级的架构,然后结合剪枝量化进行模型的进一步压缩
基本概念:
1.感受野
感受野指的是卷积神经网络每一层输出的特征图(feature map)上每个像素点映射回输入图像上的区域大小,神经元感受野的范围越大表示其能接触到的原始图像范围就越大,也意味着它能学习更为全局,语义层次更高的特征信息,相反,范围越小则表示其所包含的特征越趋向局部和细节。因此感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显地知道网络越深,神经元的感受野越大。
2.分辨率
分辨率指的是输入模型的图像尺寸,即长宽大小。通常情况会根据模型下采样次数n和最后一次下采样后feature map的分辨率k×k来决定输入分辨率的大小,即: r=k*2^n
从输入r×r到最后一个卷积特征feature map的k×k,整个过程是一个信息逐渐抽象化的过程,即网络学习到的信息逐渐由低级的几何信息转变为高级的语义信息,这个feature map的大小可以是3×3,5×5,7×7,9×9等等,k太大会增加后续的计算量且信息抽象层次不够高,影响网络性能,k太小会造成非常严重的信息丢失,如原始分辨率映射到最后一层的feature map有效区域可能不到一个像素点,使得训练无法收敛。
在ImageNet分类任务中,通常设置的5次下采样,并且考虑到其原始图像大多数在300分辨率左右,所以把最后一个卷积特征大小设定为7×7,将输入尺寸固定为224×224×3。在目标检测任务中,很多采用的是416×416×3的输入尺寸,当然由于很多目标检测模型是全卷积的结构,通常可以使用多尺寸训练的方式,即每次输入只需要保证是32×的图像尺寸大小就行,不固定具体数值。但这种多尺度训练的方式在图像分类当中是不通用的,因为分类模型最后一层是全连接结构,即矩阵乘法,需要固定输入数据的维度。
3.深度
神经网络的深度决定了网络的表达能力,它有两种计算方法,早期的backbone设计都是直接使用卷积层堆叠的方式,它的深度即神经网络的层数,后来的backbone设计采用了更高效的module(或block)堆叠的方式,每个module是由多个卷积层组成,它的深度也可以指module的个数,这种说法在神经架构搜索(NAS)中出现的更为频繁。通常而言网络越深表达能力越强,但深度大于某个值可能会带来相反的效果,所以它的具体设定需要不断调参得到。
4.宽度
宽度决定了网络在某一层学到的信息量,但网络的宽度时指的是卷积神经网络中最大的通道数,由卷积核数量最多的层决定。通常的结构设计中卷积核的数量随着层数越来越多的,直到最后一层feature map达到最大,这是因为越到深层,feature map的分辨率越小,所包含的信息越高级,所以需要更多的卷积核来进行学习。通道越多效果越好,但带来的计算量也会大大增加,所以具体设定也是一个调参的过程,并且各层通道数会按照8×的倍数来确定,这样有利于GPU的并行计算。

5.下采样
下采样层有两个作用,一是减少计算量,防止过拟合,二是增大感受野,使得后面的卷积核能够学到更加全局的信息。下采样的设计有两种:
1.采用stride为2的池化层,如Max-pooling或Average-pooling,目前通常使用Max-pooling,因为它计算简单且最大响应能更好保留纹理特征;
2.采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
6.上采样
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作,叫做上采样,它的实现一般有三种方式:
- 插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提;
- 转置卷积又或是说反卷积,通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;
- Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0;
7.参数量
参数量指的网络中可学习变量的数量,包括卷积核的权重weight,批归一化(BN)的缩放系数γ,偏移系数β,有些没有BN的层可能有偏置bias,这些都是可学习的参数 ,即在模型训练开始前被赋予初值,在训练过程根据链式法则中不断迭代更新,整个模型的参数量主要由卷积核的权重weight的数量决定,参数量越大,则该结构对运行平台的内存要求越高,参数量的大小是轻量化网络设计的一个重要评价指标。
8.计算量
神经网络的前向推理过程基本上都是乘累加计算,所以它的计算量也是指的前向推理过程中乘加运算的次数,通常用FLOPs来表示,即floating point operations(浮点运算数)。计算量越大,在同一平台上模型运行延时越长,尤其是在移动端/嵌入式这种资源受限的平台上想要达到实时性的要求就必须要求模型的计算量尽可能地低,但这个不是严格成正比关系,也跟具体算子的计算密集程度(即计算时间与IO时间占比)和该算子底层优化的程度有关。
卷积计算类型
1.标准卷积
2.深度卷积
3.分组卷积
4.空洞卷积
5.转置卷积
6.可变形卷积
其他算子
池化---(最大池化,平均池化,全局平均池化,最大向上池化)
全链接计算
addition/concatenate分支
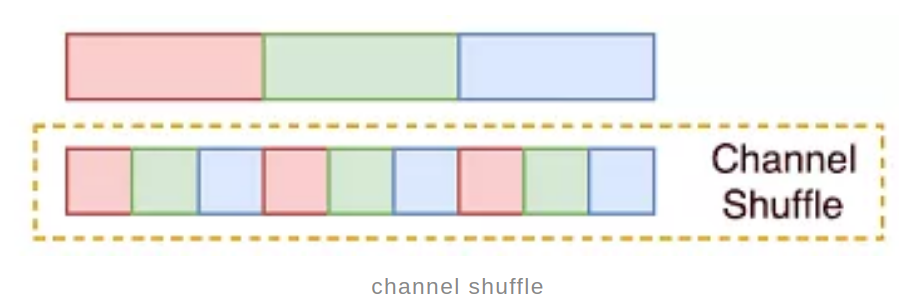
channel shuffle
channel shuffle是ShuffleNet中首次提出,主要是针对分组卷积中不同组之间信息不流通,对不同组的feature map进行混洗的一个操作,如下图所示,假设原始的feature map维度为(1,9,H,W),被分成了3个组,每个组有三个通道,那么首先将这个feature map进行reshape操作,得到(1,3,3,H,W),然后对中间的两个大小为3的维度进行转置,依然是(1,3,3,H,W),最后将通道拉平,变回(1,9,H,W),就完成了通道混洗,使得不同组的feature map间隔保存,增强了信息的交互。
常用激活函数
relu系列---(relu,relu6,leaky relu)
sigmiod系列
金典轻量化模型
squeezeNet
mobilenet系列
shufflenet系列
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
Ghostnet
efficientdet
yolov*-tiny
基于特定硬件的神经架构搜索
基于特定硬件的神经架构搜索(MIT HAN Lab论文总结
https://zhuanlan.zhihu.com/p/320290820)
设计方法总结
该总结来自极市平台的Ironboy
轻量级CNN架构设计总的思路:选定合适的结构+通道剪枝+量化
训练:imagenet pretrain model + data normalization(统计自己数据集的均值和方差)+BN+大batch size+一堆数据增强tricks+尝试各种花里胡哨的loss function和optimizer
1. 绝对贫穷人口
a) 输入分辨率要小,如128,160,192或者256
b) 下采样使用maxpooling
c) 特征学习层使用depthwise separable convolution
d)激活函数使用relu
(推荐阅读 MCUNet)
2.相对贫穷人口
a)输入分辨率依旧要小,分辨率对计算量的影响是翻倍的
b)下采样使用maxpooling或者stride 为2的depthwise separable convolotion
c)特征学习使用depthwise separable convolution 或者mobilenbet v2的倒残差结构,由或是shufflenet v2的unit,1*1的group conv能处理的比较好的话也比较推荐使用
d)激活函数使用relu或者relu6
3.低收入人口
a) 输入使用小分辨率,如果对精度要求较高可以适当增大
b)下采样可以使用maxpooling或者stride为2 的depthwise separable conv
c)特征学习可以使用mobilenet v2的倒残差结构,又或是shufflenet v2的unit,也可以使用通道数小点的3*3标准卷积
d)激活函数使用relu,relu6或者leaky relu
4.一般收入人口
a)输入可以稍微大一点,280,320,384
b)下采样使用stride为2的depthwise separable conv或者stride为2 的3*3卷积
c)特征学习即可以使用上述的,也可以使用3*3标准卷积+1*1标准卷积的堆叠形式,se block这种硬件支持的还不错的可以考虑加上
d)激活函数除了上上述的可以试试H-sigmoi和H-swish
5.高收入人口
a) 输入数据的分辨率可以往500-600靠拢
b)下采样和上述一样
c)特征学习可以使用resnet+se block,资源较多可以增加通道数和深度
d)激活函数使用H-swish
另外使用mobilenetv2的倒残差模块+se block+H-swish,MIt han lab在很多比赛中都拿到了冠军
以上内容摘自:极市平台 综述:轻量级CNN架构设计(https://mp.weixin.qq.com/s?__biz=MzI5MDUyMDIxNA==&mid=2247525207&idx=1&sn=6cc236e12d4e12233e602c4c4799f1d2&exportkey=AfvZMyUGPnNgi6Or3FL5S8s%3D&pass_ticket=cKLS6DEwmLKBKlYmdU%2B1PU1NN%2FN9MAg%2BC9oQPyVamkGrCtpJmcVXCKuNXRM5iJGa&wx_header=0)
以下内容为根据相关论文的阅读以及项目经验进行的总结:
汇总|目标检测中的数据增强、backbone、head、neck、损失函数
一、数据增强方式
1. random erase
2. CutOut
3. MixUp
4. CutMix
5. 色彩、对比度增强
6. 旋转、裁剪
解决数据不均衡:
- Focal loss
- hard negative example mining
- OHEM
- S-OHEM
- GHM(较大关注easy和正常hard样本,较少关注outliners)
- PISA
二、常用backbone
1. VGG
2. ResNet(ResNet18,50,100)
3. ResNeXt
4. DenseNet
5. SqueezeNet
6. Darknet(Darknet19,53)
7. MobileNet
8. ShuffleNet
9. DetNet
10. DetNAS
11. SpineNet
12. EfficientNet(EfficientNet-B0/B7)
13. CSPResNeXt50
14. CSPDarknet53
15. Thundernet
16. Ghostnet
三、常用Head
Dense Prediction (one-stage):
1. RPN
2. SSD
3. YOLO
4. RetinaNet
5. (anchor based)
6. CornerNet
7. CenterNet
8. MatrixNet
9. FCOS(anchor free)
10. GFCOS
Sparse Prediction (two-stage):
1. Faster R-CNN
2. R-FCN
3. Mask RCNN (anchor based)
4. RepPoints(anchor free)
四、常用neck
Additional blocks:
1. SPP
2. ASPP
3. RFB
4. SAM
Path-aggregation blocks:
1. FPN
2. PAN
3. NAS-FPN
4. Fully-connected FPN
5. BiFPN
6. ASFF
7. SFAM
8. NAS-FPN
五、Skip-connections
1. Residual connections
2. Weighted residual connections
3. Multi-input weighted residual connections
4. Cross stage partial connections (CSP)
六、常用激活函数和loss
激活函数:
- ReLU
- LReLU
- PReLU
- ReLU6
- Scaled Exponential Linear Unit (SELU)
- Swish
- hard-Swish
- Mish
loss:
- MSE
- Smooth L1
- Balanced L1
- KL Loss
- GHM loss
- IoU Loss
- Bounded IoU Loss
- GIoU Loss
- CIoU Loss
- DIoU Loss
- Generalized Focal Loss v1 v2
- ATSS
七、正则化和BN方式
正则化:
- DropOut
- DropPath
- Spatial DropOut
- DropBlock
BN:
- Batch Normalization (BN)
- Cross-GPU Batch Normalization (CGBN or SyncBN)
- Filter Response Normalization (FRN)
- Cross-Iteration Batch Normalization (CBN)
八、训练技巧
- Label Smoothing
- Warm Up
若有不对或者表述不正确的地方请指出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号