
Resnet以及相应的变体
在过去的几年里,ResNet网络可以说是一篇开创新的工作,ResNet使得训练更深的网络成为可能。除了图像分类任务以外,在目标检测以及人脸识别等领域发光发热。
AlexNet架构只有5层卷积,而VGG和GoogleNet分别有19和22层。网络层数越深,拟合能力就越强,但是网络的深度不能通过层与层的直接叠加得到,因为这样会导致梯度消失和网络难以训练。
1. ResNet的核心思想是加入一个恒等映射(identity shortcut connection),直接跳过一个或者多个网络层,如下图1.所示的残差快
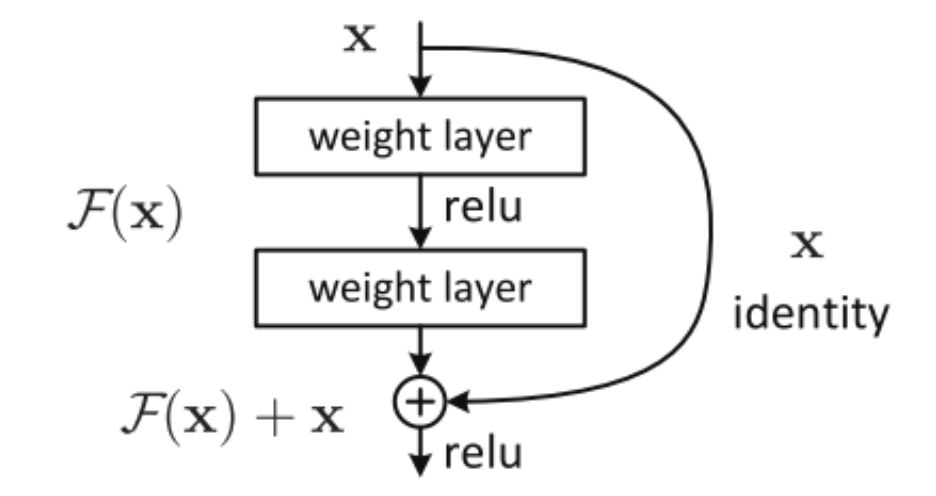
图1. 残差快
2.残差快的变体
2.1ResNeXt, 网络结构如下右图
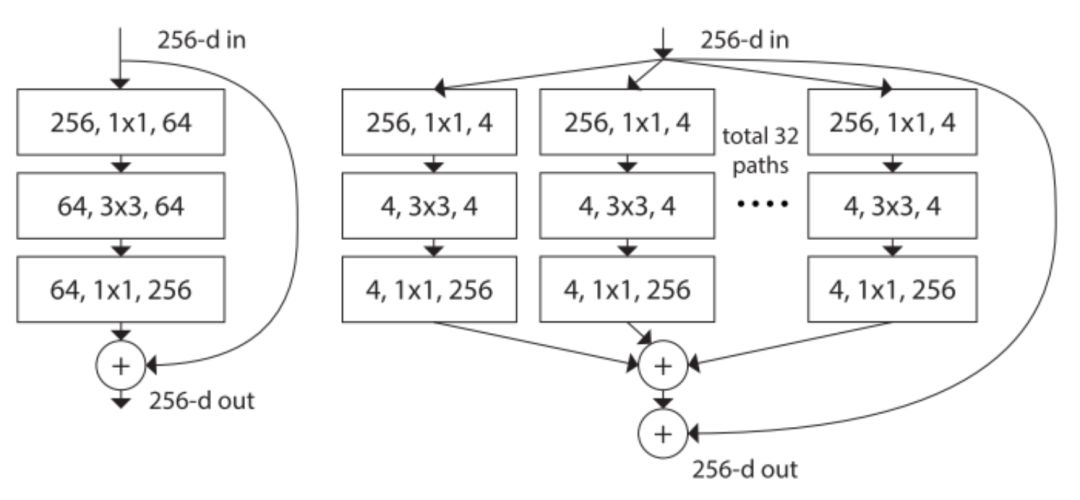
图2. 左图是ResNet,右图是ResNeXt,基数是32
ResNeXt看起来和inception比较相似,都采用的是 分割->转换->合并的结构。但是在ResNeXt中,不同路径的输出是通过相加合并,而在inception中深度级联的,还有就是Inception中的每一个路径互不相同(1*1,3*3,5*5),在ResNeXt中,所有的路径都有相同的拓扑结构。基数是网络中的一个超参数,这样提供了一种调整模型容量的新思路,作者表明这种网络结构与inception相比,更容易适应新的数据集或者任务,因为每个路径一样,而且只有一个需要调整的超参数,而inception需要调整很多超参数(比如每个路径的卷积核的大小等等)。
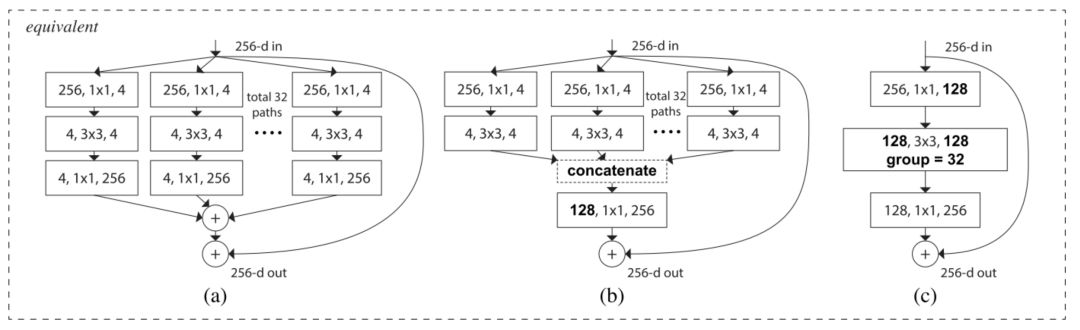
这种结构有三种等价形式,如图3:
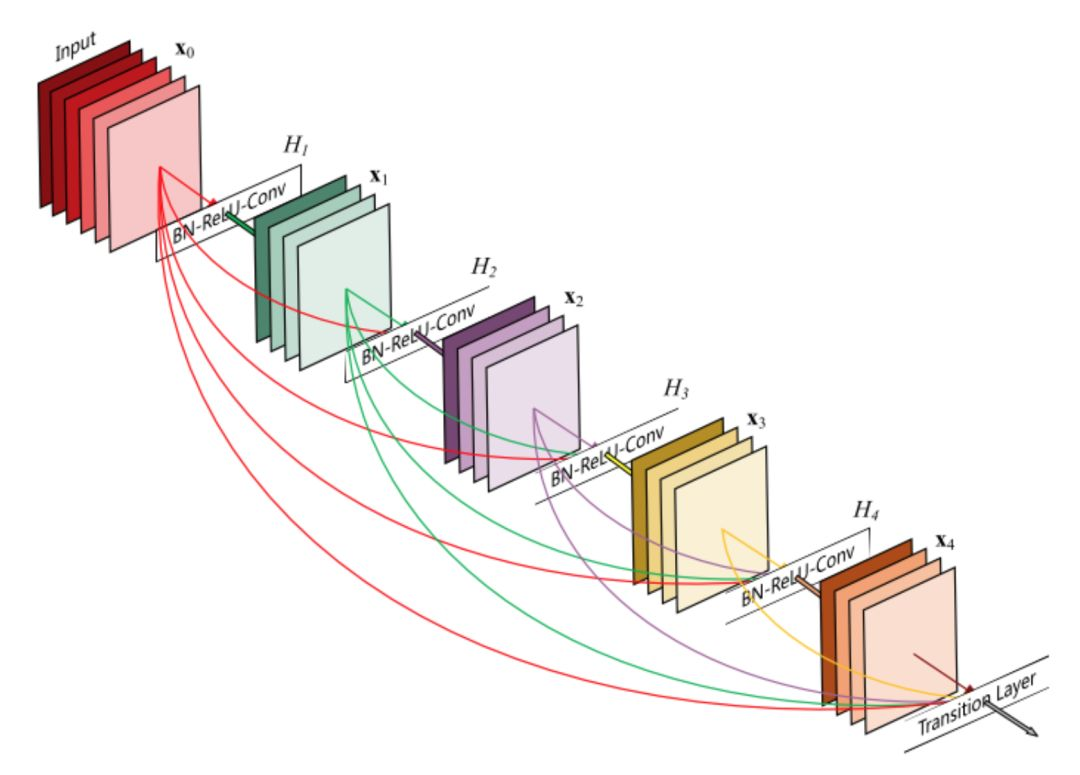
2.2DenseNet,将所有的层直接联系在一起,在这种架构中,每层的输入由之前所有的层特征映射组成,其输出将传递给后续的每个层。网络结构如下图4.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号