
Guided Anchoring: 物体检测器也能自己学 Anchor(Region Proposal by Guided Anchoring)
Guided anchor: 通过图像特征来指导anchor的生成,通过预测anchor的位置和形状,来生成稀疏而且形状任意的anchor,并且设计了Feature Adaption模块修正特征图,使之与anchor形状更加匹配。
预先定义anchor的缺点:
需要预先定义anchor的尺度和长宽比,改参数对性能影响较大,而且对于不同的数据集合方法需要单独调整。如果尺度和长宽比设置不合适,可能会导致recall不够高,或者anchor过多,会影响分类性能和速度。一方面,大部分的anchor分布在背景区域,对proposal 或者检测不会有任何的正面作用;另一方面,预先定义好的anchor不一定能够满足极端大小或者长宽比比较悬殊的物体,所以期待anchor比较稀疏,但是形状可以根据位置可变。
anchor的生成方式:
通常使用4个数(x,y,w,h)描述一个anchor,即中心点坐标和宽高。将anchor的分布formulate成如下公式:
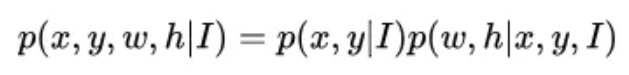
anchor的概率分布可以被分解成两个条件概略分布,也就是给定图像特征之后anchor中心点的概率分布和给定图像特征和中心点之后的形状概率分布。Sliding window可以看成p(x,y|I)是均匀分布,而p(w,h|x,y,I)是冲激函数的特例。根据该公式,anchor可以分解为两个步骤,anchor位置预测和形状预测。
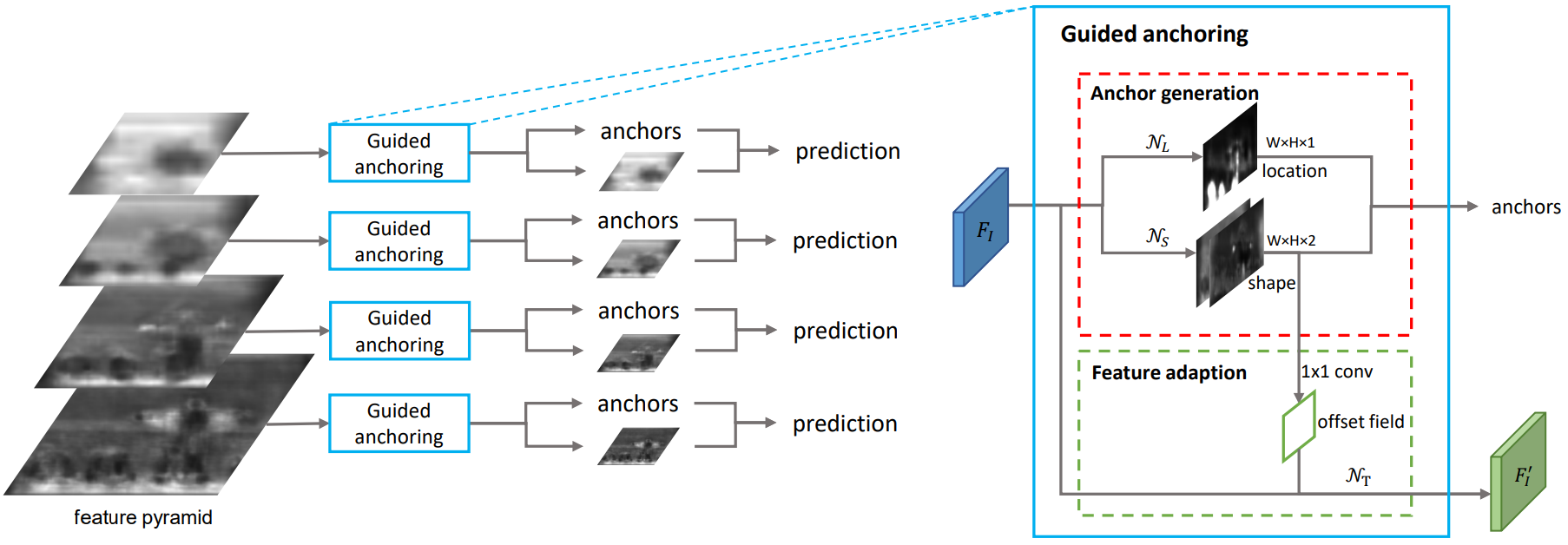
如图所示,在RPN的特征图基础上,论文采用两个分支分别预测anchor的位置和形状,然后结合在一起得到anchors,之后采用一个Feature Adaption模块进行anchor特征的调整,得到新的特征图供之后的预测(anchor的分类和回归)使用。相比之前的网络只是增加了3个1X1 conv和一个3X3 defomable conv,模型参数量的变化比较小。
位置预测:
位置预测分支的目标是预测那些区域应该作为中心点来生成anchor,是一个二分类问题,与RPN或者segmentation的分类不同,论文并不是预测每个点是前景还是背景,而是预测是不是物体的中心。
我们将整个feature map 的区域分为物体中心区域,外围区域和忽略区域,大概思路就是将ground truth框的中心一小块对应在feature map上的区域,在训练的时候作为正样本,其余区域按照距离中心的距离标为忽略或者负样本。通过为止预测,可以筛选出一小部分区域作为anchor的候选中心点位置,使得anchor数量大大降低。在inference的时候,预测完位置之后,我们可以采用masked conv替代普通的conv,只在有anchor的地方进行计算,实现加速。
形状预测:
形状预测分支的目标是给定anchor中心点,预测最佳的长和宽,这是一个回归问题,常规做法是先算出target,也就是该中心点的anchor最优的w和h,然后用L1/L2/Smooth L1这类loss来监督。但是这个target并不好算,而且实现起来比较困难,所以我们直接使用IOU作为监督,来学习w和h。既然算不出来最优的w和h,而计算IOU又是可导的操作,就让网络自己去使得IOU最大,后来改用了bounded IOU Loss,但是原理也是一样的。
这里面还有一个问题需要解决,就是对于某个anchor,应该优化和哪个ground truth的IOU,也就是说应该把这个anchor分配给哪个ground truth.对于以前常规的anchor,我们可以直接计算它和所有的ground truth的IOU,然后将它分配给IOU最大的那个GT。但是很不幸的是现在的anchor的w和h是不确定的,是一个需要预测的变量。我们将这个anchor和某个gt的IOU表示为![]() 。当热an我们不可能把所有的可能的w和h遍历一遍然后求IOU的最大值,因此采用的 近似的方法,也就是sample一些可能的w和h,理论上sample的越多越好,但是考虑效率问题,论文sample了常见的9组w和h。通过实验发现,最终的结果对sample的组数这个超参数并不敏感。
。当热an我们不可能把所有的可能的w和h遍历一遍然后求IOU的最大值,因此采用的 近似的方法,也就是sample一些可能的w和h,理论上sample的越多越好,但是考虑效率问题,论文sample了常见的9组w和h。通过实验发现,最终的结果对sample的组数这个超参数并不敏感。
生成anchor:
在得到anchor位置和形状预测之后,就可以生成anchor了,如下图所示,这时的anchor是稀疏而且每个位置不一样,采用生成的anchor取代sliding window,AR(Average Recall)已经可以超过普通RPN4个点,代价仅仅是增加了两个1X1的conv。

Feature adaption:
发现一个不合理的地方,都是用同一层conv的特征,为什么比其他的方法优秀一些,代表一个又长又大的anchor,你就只能代表一个小小的anchor。
不合理的一方面在于在同一层conv的不同位置,feature 的receiptive field的相同的,在原来的RPN里面,大家都表示相同形状的anchor,所以相安无事,但是现在每个anchor都有自己独特的形状大小,和feature 就不是特别好的match。另一方面,对原本的特征图来说,它并不知道形状预测分支anchor的形状,但是接下来的分类和回归却是基于预测的anchor来做的,可能会比较懵逼。
我们增加了一个Feature adaption模块来解决这个问题,思路比较简单,就是把anchor的形状信息直接融入到特征图中,这样得到的特征图就可以适应每个位置anchor的形状,我们利用一个3X3的deformable convolution来修正原始的特征图,而defoamable convolutionde offset是通过anchor的w和h经过一个1X1 conv的得到的。
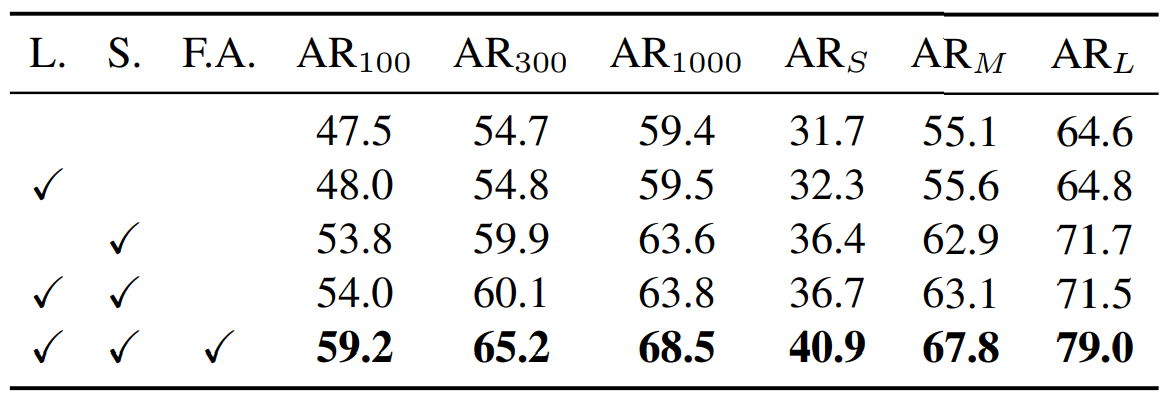
通过这样的操作,达到了让feature的有效范围和anchor形状更加接近的目的,同一个conv的不同位置也可以代表不同形状大小的anchor。从表格中可以看到,Feature adaption还是很给力的,带来了接近5个点的提升。
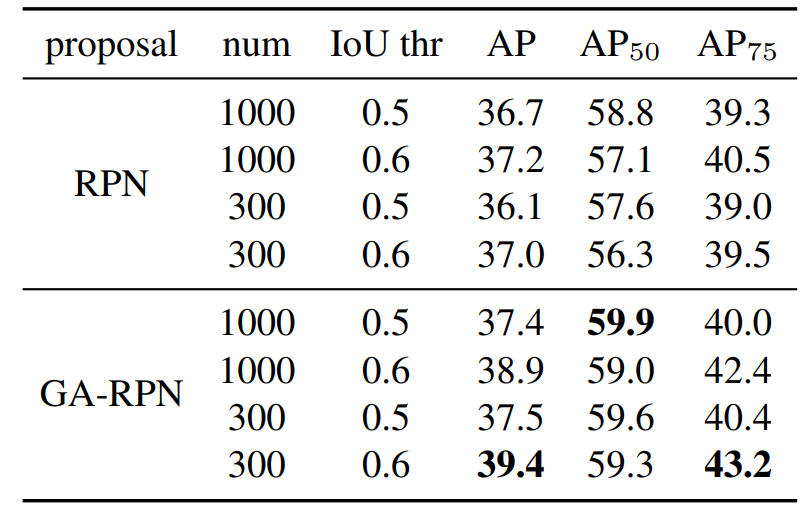
高质量proposal的正确打开方式:
proposal的质量提升了很多,但是是在detector上性能提升比较有限,在不同的检测模型上,使用Guided Anchoring仅仅提升1个点左右,很好的proposal但是mAP涨点不多。经过研究,发现以下两点:1.减少proposal数量,2增大训练时正样本的IOU阈值(这个更重要)。既然top300里面已经有了很多高IOU的proposal,那么何必用1000个框来训练和测试,既然proposal都这么优秀,就可以让IOU标准严格一些。
anchor设计准则:
在论文中提到了anchor设计的两个准则,alignment(中心对齐)和consistency(特征一致)。其中alignment是指anchor的中心要和feature的位置对齐,conxixtency是指anchor的特征要和形状匹配。
>>Alignment
由于每一个anchor都是由feature map 上的一个点表示,那么这个anchor最好以这个点为中心,否则位置偏了的话,这个点的faature和这个anchor就不能很好的对应起来,用该feature来预测anchor的分类和回归会有问题。论文设计了类似cascade/iterative RPN的实验来证明这一点,对anchor进行两次回归,第一次回归采用常规做法,即中心点和长宽都进行回归,这样第一次回归之后,anchor中心点和feature map每一个像素的中心就不再完全对齐,发现两次这样的回归提升十分有限,所以在形状预测分支只对w和h做预测,而不是回归中心点位置。
>>Consistency
由于每个位置anchor形状不同而破坏了特征的一致性,需要用feature adaption来进行修正,这条准则本质上是对于如何准确提取anchor特征的讨论。对于两阶段检测器的第二阶段,可以通过RoI Pooling或者RoI Align来精确的提取RoI的特征。但是对于RPN或者单阶段检测器的anchor来说,由于数量巨大,不可能通过这种heavy的方法来实现特征和框的精确match,还是只能用特征图上一个点,也就是512X1X1的向量来表示。那么feature adaption起到了一个让特征和anchor对应更加精确的作用,这种设计在其他地方也有可以借鉴之处。
总结:
1.在anchor设计中,alignment和consistency这两个准则十分重要
2.采用两个branch分别预测anchor的位置和形状,不需要预先定义
3.利用anchor形状来adapt特征图
4.高质量proposal可以使用更少的数量和更高的IOU进行训练
论文:https://arxiv.org/abs/1901.03278
代码:https://github.com/open-mmlab/mmdetection
来自https://mp.weixin.qq.com/s/Sl958JkcJjy-HW9_c-SH4g(知乎)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号