
Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据
日志文件使用log4j生成,滚动生成!
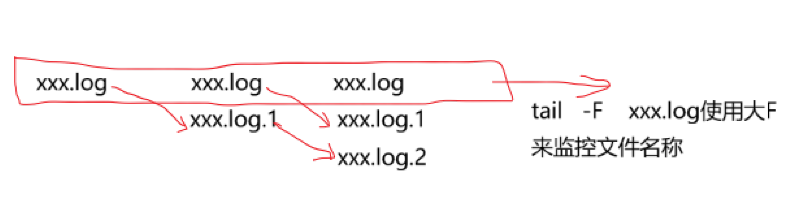
当前正在写入的文件在满足一定的数量阈值之后,需要重命名!!!
flume+Kafka整合步骤及相关配置:(先安装好zookeeper集群和Kafka集群)
配置flume:
1、下载flume
2、解压flume安装包
cd /export/servers/
tar -zxvf apache-flume-1.6.0-bin.tar.gz
ln -s apache-flume-1.6.0-bin flume
3、创建flume配置文件
cd /export/servers/flume/conf/
mkdir myconf
vi exec.conf
输入一下内容:
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /export/data/flume_sources/click_log/1.log
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic=test
a1.sinks.k1.brokerList=kafka01:9092
a1.sinks.k1.requiredAcks=1
a1.sinks.k1.batchSize=20
a1.sinks.k1.channel=c1
4、准备目标数据的目录
mkdir -p /export/data/flume_sources/click_log
5、通过脚本创建目标文件并生产数据
for((i=0;i<=50000;i++));
do echo "message-" + $i >> /export/data/flume_sources/click_log/1.log;
done
注:脚本名称为click_log_out.sh,需要使用root用户赋权,chmod +x click_log_out.sh
6、开始打通所有流程
一:启动Kafka集群
kafka-server-start.sh /export/servers/kafka/config/server.properties
二:创建一个topic并开启consumer
kafka-console-consumer.sh --topic=test --zookeeper zk01:2181
三:执行数据生产的脚本
sh click_log_out.sh
四:启动flume客户端
./bin/flume_ng agent -n a1 -c conf -f conf/myconf/exec.conf -Dflume.root.logger=INFO,console
五:在第三步启动的kafka consumer窗口查看效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号