
hadoop日志数据分析开发步骤及代码
日志数据分析:
1.背景
1.1 hm论坛日志,数据分为两部分组成,原来是一个大文件,是56GB;以后每天生成一个文件,大约是150-200MB之间;
1.2 日志格式是apache common日志格式;每行记录有5部分组成:访问ip、访问时间、访问资源、访问状态、本次流量;27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
1.3 分析一些核心指标,供运营决策者使用;
1.4 开发该系统的目的是分了获取一些业务相关的指标,这些指标在第三方工具中无法获得的;(第三方工具:百度统计)
2.开发步骤
2.1 把日志数据上传到HDFS中进行处理
如果是日志服务器数据较小、压力较小,可以直接使用shell命令把数据上传到HDFS中;
如果是日志服务器数据较大、压力较大,使用NFS在另一台服务器上上传数据;(NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。)
如果日志服务器非常多、数据量大,使用flume进行数据处理;
2.2 使用MapReduce对HDFS中的原始数据进行清洗;
2.3 使用Hive对清洗后的数据进行统计分析;
2.4 使用Sqoop把Hive产生的统计结果导出到mysql中;指标查询--mysql
2.5 如果用户需要查看详细数据的话,可以使用HBase进行展现;明细查询--HBase
3.流程代码(具体实际操作步骤见下面)
3.1 使用shell命令把数据从linux磁盘上传到HDFS中
3.1.1 在hdfs中创建目录,命令如下
$HADOOP_HOME/bin/hadoop fs -mkdir /hmbbs_logs
3.1.2 写一个shell脚本,叫做upload_to_hdfs.sh,内容大体如下
yesterday=`date --date='1 days ago' +%Y_%m_%d`
hadoop fs -put /apache_logs/access_${yesterday}.log /hmbbs_logs
3.1.3 把脚本upload_to_hdfs.sh配置到crontab中,执行命令crontab -e, 写法如下
* 1 * * * upload_to_hdfs.sh
3.2 使用MapReduce对数据进行清洗,把原始处理清洗后,放到hdfs的/hmbbs_cleaned目录下,每天产生一个子目录。
3.3 使用hive对清洗后的数据进行统计。
3.3.1 建立一个外部分区表,脚本如下
CREATE EXTERNAL TABLE hmbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/hmbbs_cleaned';
3.3.2 增加分区,脚本如下
ALTER TABLE hmbbs ADD PARTITION(logdate='2013_05_30') LOCATION '/hmbbs_cleaned/2013_05_30';
把代码增加到upload_to_hdfs.sh中,内容如下
hive -e "ALTER TABLE hmbbs ADD PARTITION(logdate='${yesterday}') LOCATION '/hmbbs_cleaned/${yesterday}';"
3.3.3 统计每日的pv,代码如下
CREATE TABLE hmbbs_pv_2013_05_30 AS SELECT COUNT(1) AS PV FROM hmbbs WHERE logdate='2013_05_30';
统计每日的注册用户数,代码如下
CREATE TABLE hmbbs_reguser_2013_05_30 AS SELECT COUNT(1) AS REGUSER FROM hmbbs WHERE logdate='2013_05_30' AND INSTR(url,'member.php?mod=register')>0;
统计每日的独立ip,代码如下
CREATE TABLE hmbbs_ip_2013_05_30 AS SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate='2013_05_30';
统计每日的跳出用户,代码如下
CREATE TABLE hmbbs_jumper_2013_05_30 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate='2013_05_30' GROUP BY ip HAVING times=1) e;
把每天统计的数据放入一张表
CREATE TABLE hmbbs_2013_05_30 AS SELECT '2013_05_30', a.pv, b.reguser, c.ip, d.jumper FROM hmbbs_pv_2013_05_30 a JOIN hmbbs_reguser_2013_05_30 b ON 1=1 JOIN hmbbs_ip_2013_05_30 c ON 1=1 JOIN hmbbs_jumper_2013_05_30 d ON 1=1 ;
3.4 使用sqoop把数据导出到mysql中
*********************************************
日志数据分析详细步骤(自己实际操作成功的步骤):
1、使用shell把数据从Linux磁盘上上传到HDFS中
在Linux上/usr/local/下创建一个目录:mkdir apache_logs/,然后复制两天的日志数据放到此文件夹下。
在HDFS中创建存放数据的目录:hadoop fs -mkdir /hmbbs_logs
hadoop fs -put /usr/local/apache_logs/* /hmbbs_logs
上传结束了,在hadoop0:50070中观察到在/hmbbs/目录下有两个日志文件。

在/apache_logs目录下创建一个上传数据的shell脚本:vi upload_to_hdfs.sh
#!/bin/sh
#get yesterday format string
yesterday=`date --date='1 days ago' +%Y_%m_%d`
#upload logs to hdfs
hadoop fs -put /apache_logs/access_${yesterday}.log /hmbbs_logs
把脚本upload_to_hdfs.sh配置到crontab中,执行命令crontab -e(在每天的1点钟会准时执行脚本文件)
* 1 * * * upload_to_hdfs.sh
2、在eclipse中书写代码,使用MapReduce清洗数据。打包cleaned.jar导出到linux下的/apache_logs目录下。
1 package hmbbs; 2 3 import java.text.ParseException; 4 import java.text.SimpleDateFormat; 5 import java.util.Date; 6 import java.util.Locale; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.conf.Configured; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.LongWritable; 12 import org.apache.hadoop.io.NullWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 import org.apache.hadoop.util.Tool; 20 import org.apache.hadoop.util.ToolRunner; 21 /** 22 * 源数据的清洗 23 * @author ahu_lichang 24 * 25 */ 26 public class HmbbsCleaner extends Configured implements Tool { 27 public int run(String[] args) throws Exception { 28 final Job job = new Job(new Configuration(), 29 HmbbsCleaner.class.getSimpleName()); 30 job.setJarByClass(HmbbsCleaner.class); 31 FileInputFormat.setInputPaths(job, args[0]); 32 job.setMapperClass(MyMapper.class); 33 job.setMapOutputKeyClass(LongWritable.class); 34 job.setMapOutputValueClass(Text.class); 35 job.setReducerClass(MyReducer.class); 36 job.setOutputKeyClass(Text.class); 37 job.setOutputValueClass(NullWritable.class); 38 FileOutputFormat.setOutputPath(job, new Path(args[1])); 39 job.waitForCompletion(true); 40 return 0; 41 } 42 43 public static void main(String[] args) throws Exception { 44 ToolRunner.run(new HmbbsCleaner(), args); 45 } 46 47 static class MyMapper extends 48 Mapper<LongWritable, Text, LongWritable, Text> { 49 LogParser logParser = new LogParser(); 50 Text v2 = new Text(); 51 52 protected void map( 53 LongWritable key, 54 Text value, 55 org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, Text>.Context context) 56 throws java.io.IOException, InterruptedException { 57 final String[] parsed = logParser.parse(value.toString()); 58 59 // 过滤掉静态信息 60 if (parsed[2].startsWith("GET /static/") 61 || parsed[2].startsWith("GET /uc_server")) { 62 return; 63 } 64 65 // 过掉开头的特定格式字符串 66 if (parsed[2].startsWith("GET /")) { 67 parsed[2] = parsed[2].substring("GET /".length()); 68 } else if (parsed[2].startsWith("POST /")) { 69 parsed[2] = parsed[2].substring("POST /".length()); 70 } 71 72 // 过滤结尾的特定格式字符串 73 if (parsed[2].endsWith(" HTTP/1.1")) { 74 parsed[2] = parsed[2].substring(0, parsed[2].length() 75 - " HTTP/1.1".length()); 76 } 77 78 v2.set(parsed[0] + "\t" + parsed[1] + "\t" + parsed[2]); 79 context.write(key, v2); 80 }; 81 } 82 83 static class MyReducer extends 84 Reducer<LongWritable, Text, Text, NullWritable> { 85 protected void reduce( 86 LongWritable k2, 87 java.lang.Iterable<Text> v2s, 88 org.apache.hadoop.mapreduce.Reducer<LongWritable, Text, Text, NullWritable>.Context context) 89 throws java.io.IOException, InterruptedException { 90 for (Text v2 : v2s) { 91 context.write(v2, NullWritable.get()); 92 } 93 }; 94 } 95 96 static class LogParser { 97 public static final SimpleDateFormat FORMAT = new SimpleDateFormat( 98 "d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); 99 public static final SimpleDateFormat dateformat1 = new SimpleDateFormat( 100 "yyyyMMddHHmmss"); 101 102 public static void main(String[] args) throws ParseException { 103 final String S1 = "27.19.74.143 - - [30/May/2013:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127"; 104 LogParser parser = new LogParser(); 105 final String[] array = parser.parse(S1); 106 System.out.println("样例数据: " + S1); 107 System.out.format( 108 "解析结果: ip=%s, time=%s, url=%s, status=%s, traffic=%s", 109 array[0], array[1], array[2], array[3], array[4]); 110 } 111 112 /** 113 * 解析英文时间字符串 114 * 115 * @param string 116 * @return 117 * @throws ParseException 118 */ 119 private Date parseDateFormat(String string) { 120 Date parse = null; 121 try { 122 parse = FORMAT.parse(string); 123 } catch (ParseException e) { 124 e.printStackTrace(); 125 } 126 return parse; 127 } 128 129 /** 130 * 解析日志的行记录 131 * 132 * @param line 133 * @return 数组含有5个元素,分别是ip、时间、url、状态、流量 134 */ 135 public String[] parse(String line) { 136 String ip = parseIP(line); 137 String time = parseTime(line); 138 String url = parseURL(line); 139 String status = parseStatus(line); 140 String traffic = parseTraffic(line); 141 142 return new String[] { ip, time, url, status, traffic }; 143 } 144 145 private String parseTraffic(String line) { 146 final String trim = line.substring(line.lastIndexOf("\"") + 1) 147 .trim(); 148 String traffic = trim.split(" ")[1]; 149 return traffic; 150 } 151 152 private String parseStatus(String line) { 153 final String trim = line.substring(line.lastIndexOf("\"") + 1) 154 .trim(); 155 String status = trim.split(" ")[0]; 156 return status; 157 } 158 159 private String parseURL(String line) { 160 final int first = line.indexOf("\""); 161 final int last = line.lastIndexOf("\""); 162 String url = line.substring(first + 1, last); 163 return url; 164 } 165 166 private String parseTime(String line) { 167 final int first = line.indexOf("["); 168 final int last = line.indexOf("+0800]"); 169 String time = line.substring(first + 1, last).trim(); 170 Date date = parseDateFormat(time); 171 return dateformat1.format(date); 172 } 173 174 private String parseIP(String line) { 175 String ip = line.split("- -")[0].trim(); 176 return ip; 177 } 178 } 179 180 }
vi upload_to_hdfs.sh
#!/bin/sh
#get yesterday format string
#yesterday=`date --date='1 days ago' +%Y_%m_%d`
#testing cleaning data
yesterday=$1
#upload logs to hdfs
hadoop fs -put /apache_logs/access_${yesterday}.log /hmbbs_logs
#cleanning data
hadoop jar cleaned.jar /hmbbs_logs/access_${yesterday}.log /hmbbs_cleaned/${yesterday}
权限chmod u+x upload_to_hdfs.sh
执行upload_to_hdfs.sh 2013_05_30
然后在浏览器中hadoop0:50070中就能观察到上传到HDFS中的清洗过后的数据了。

3、使用hive对清洗后的数据进行统计。
建立一个外部分区表,脚本如下
CREATE EXTERNAL TABLE hmbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/hmbbs_cleaned';

增加分区,脚本如下
ALTER TABLE hmbbs ADD PARTITION(logdate='2013_05_30') LOCATION '/hmbbs_cleaned/2013_05_30';

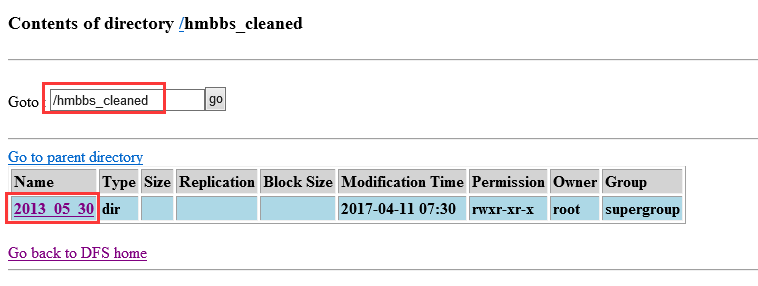
把代码增加到upload_to_hdfs.sh中,内容如下(每天产生一个分区)
#alter hive table and then add partition to existed table
hive -e "ALTER TABLE hmbbs ADD PARTITION(logdate='${yesterday}') LOCATION '/hmbbs_cleaned/${yesterday}';"
------hive -e "执行语句;" hive -e的作用就是不用在hive命令行下,可以在外面执行。
可以在外面执行hive -e "ALTER TABLE hmbbs ADD PARTITION(logdate='2013_05_31') LOCATION '/hmbbs_cleaned/2013_05_31';"
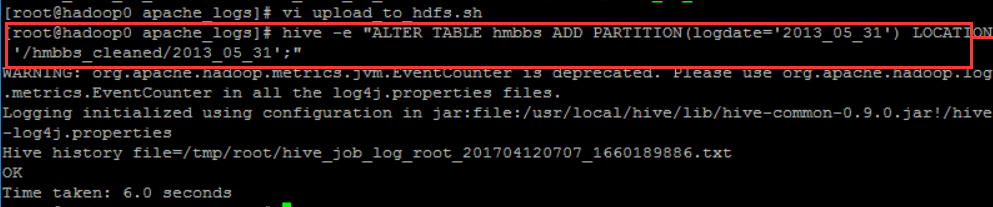
这样在/hmbbs表下面就多了一个2013_05_31文件
select count(1) form hmbbs -----通过观察数字大小变化,就可判断出是否添加成功。


统计每日的pv,代码如下
CREATE TABLE hmbbs_pv_2013_05_30 AS SELECT COUNT(1) AS PV FROM hmbbs WHERE logdate='2013_05_30';
执行hive -e "SELECT COUNT(1) FROM hmbbs WHERE logdate='2013_05_30';" 得到表中的数据大小,待后面验证用。
执行hive -e "CREATE TABLE hmbbs_pv_2013_05_30 AS SELECT COUNT(1) AS PV FROM hmbbs WHERE logdate='2013_05_30';" 将查询到的PV(别名)数据存到表hmbbs_pv_2013_05_30中。
验证表中是否添加成功了数据:hive -e "select * from hmbbs_pv_2013_05_30;"
统计每日的注册用户数,代码如下
CREATE TABLE hmbbs_reguser_2013_05_30 AS SELECT COUNT(1) AS REGUSER FROM hmbbs WHERE logdate='2013_05_30' AND INSTR(url,'member.php?mod=register')>0;
INSTR(url,'member.php?mod=register')是一个函数,用来判断url字符串中所包含的子串member.php?mod=register的个数
执行hive -e "SELECT COUNT(1) AS REGUSER FROM hmbbs WHERE logdate='2013_05_30' AND INSTR(url,'member.php?mod=register')>0;" 可以统计出其中一天的用户注册数。这个数字肯定比之前的pv数小!
统计每日的独立ip(去重),代码如下
CREATE TABLE hmbbs_ip_2013_05_30 AS SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate='2013_05_30';
在hive中查询有多少个独立ip:SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate='2013_05_30';
执行hive -e "CREATE TABLE hmbbs_ip_2013_05_30 AS SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate='2013_05_30';"
统计每日的跳出用户,代码如下
CREATE TABLE hmbbs_jumper_2013_05_30 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate='2013_05_30' GROUP BY ip HAVING times=1) e;
在hive下查询登录次数只有一次的ip有哪些:SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate='2013_05_30' GROUP BY ip HAVING times=1) e; ---e是别名
执行hive -e "CREATE TABLE hmbbs_jumper_2013_05_30 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate='2013_05_30' GROUP BY ip HAVING times=1) e;"
把每天统计的数据放入一张表 (表连接)
CREATE TABLE hmbbs_2013_05_30 AS SELECT '2013_05_30', a.pv, b.reguser, c.ip, d.jumper FROM hmbbs_pv_2013_05_30 a JOIN hmbbs_reguser_2013_05_30 b ON 1=1 JOIN hmbbs_ip_2013_05_30 c ON 1=1 JOIN hmbbs_jumper_2013_05_30 d ON 1=1 ;
创建完了,查看一下:
show tables;
select * from hmbbs_2013_05_30 ;
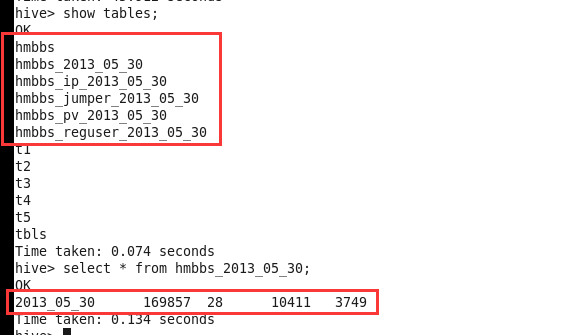
使用sqoop把hmbbs_2013_05_30表中数据导出到mysql中。(数据导出成功了以后,就可以删除掉之前的5个表了)
在MySQL第三方工具上连接hadoop0,在里面创建一个数据库hmbbs,再创建一个表hmbbs_logs_stat,表中有导出数据的5个字段:logdate varchar 非空 ,pv int, reguser int, ip int, jumper int


注意:创建数据库时,出现错误:远程登录权限问题!

sqoop export --connect jdbc:mysql://hadoop0:3306/hmbbs --username root --password admin --table hmbbs_logs_stat --fields-terminated-by '\001'--export-dir ‘/hive/hmbbs_2013_05_30’
----'\001'是默认的列分隔符 /user/hive/warehouse/hmbbs_2013_05_30这个目录根据自己的设置,不一定都是这样的!
导出成功以后,可以在工具中刷新表,就能观察到表中的数据了。

统计数据和导出操作也都应该放在脚本文件中:
vi upload_to_hdfs.sh
#create hive table everyday
hive -e "CREATE TABLE hmbbs_pv_${yesterday} AS SELECT COUNT(1) AS PV FROM hmbbs WHERE logdate='${yesterday}';"
hive -e "SELECT COUNT(1) AS REGUSER FROM hmbbs WHERE logdate='${yesterday}' AND INSTR(url,'member.php?mod=register')>0;"
hive -e "CREATE TABLE hmbbs_ip_${yesterday} AS SELECT COUNT(DISTINCT ip) AS IP FROM hmbbs WHERE logdate='${yesterday}';"
hive -e "CREATE TABLE hmbbs_jumper_${yesterday} AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM hmbbs WHERE logdate='${yesterday}' GROUP BY ip HAVING times=1) e;"
hive -e "CREATE TABLE hmbbs_${yesterday} AS SELECT '${yesterday}', a.pv, b.reguser, c.ip, d.jumper FROM hmbbs_pv_${yesterday} a JOIN hmbbs_reguser_${yesterday} b ON 1=1 JOIN hmbbs_ip_${yesterday} c ON 1=1 JOIN hmbbs_jumper_${yesterday} d ON 1=1 ;"
#delete hive tables
hive -e "drop table hmbbs_pv_${yesterday}"
hive -e "drop table hmbbs_reguser_${yesterday}"
hive -e "drop table hmbbs_ip_${yesterday}"
hive -e "drop table hmbbs_jumper_${yesterday}"
#sqoop export to mysql
sqoop export --connect jdbc:mysql://hadoop0:3306/hmbbs --username root --password admin --table hmbbs_logs_stat --fields-terminated-by '\001'--export-dir ‘/hive/hmbbs_${yesterday}’
#delete hive tables
hive -e "drop table hmbbs_${yesterday}"
完善执行的shell脚本:
1、初始化数据的脚本(历史数据)
2、每日执行的脚本
mv upload_to_hdfs.sh hmbbs_core.sh
vi hmbbs_daily.sh
#!/bin/sh
yesterday=`date --date='1 days ago' +%Y_%m_%d`
hmbbs_core.sh $yesterday
chmod u+x hmbbs_daily.sh
crontab -e
* 1 * * * /apache_logs/hmbbs_daily.sh
vi hmbbs_init.sh
#!/bin/sh
#hive -e "CREATE EXTERNAL TABLE hmbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/hmbbs_cleaned';"
s1=`date --date="$1" +%s`
s2=`date +%s`
s3=$(((s2-s1)/3600/24))
for ((i=$s3;i>0;i--))
do
tmp=`date --date="$i days ago" +%Y_%m_%d`
echo $tmp
done

 浙公网安备 33010602011771号
浙公网安备 33010602011771号