Tesseract-OCR
Tesseract
- 介绍
- 安装
- 语言支持
- 运行命令
- hello world
- 字符识别准确率的影响因素
- Tesseract的控制参数
- Java中使用libtesseract引擎
- 训练自己的语言库
介绍
Tesseract 是一套开源的光学字符识别引擎。它可以将图片中的文字转换成可以编辑的字符,并支持多种语言(uicode字符集)。所在github主页:https://github.com/tesseract-ocr
Tesseract没有内置的GUI工具,但是可以使用其它一些第三方的工具:点击查看第三方使用工具
安装
安装包括两个部分:1、Tesseract引擎(libtesseract)。2、语言库。
Windows下的安装:
1.Tesseract 3.05-dev 和 Tesseract 4.00-dev两个版本的安装文件可以在此下载: Tesseract at UB Mannheim。
2.下载需要的语言库,放在tessdata目录下即可(语言库下载见下文)。
语言支持
1、Tesseract支持多种语言,可在此语言库下载:https://github.com/tesseract-ocr/tessdata
2、可以使用自己的训练集来支持其它语言。参考文档:https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract
语言包下载:
运行命令
命令:
tesseract imagename/stdin outputbase/stdout [-l lang] [-psm pagesegmode] [configfile...]
运行命令选项
| 参数 | 解释 |
|---|---|
| imagename | 要转换的图片,支持大部分的图片格式 |
| outputbase | 生成的txt文件名,默认为outbase |
| --tessdata-dir /path | 指定语言库路径 |
| --user-words /path/to/file | 指定 |
| --user-patterns /path/to/file | specify The location of user patterns file |
| -c configvar=value | Set value for control parameter. Multiple -c arguments are allowed. |
| -l lang | 指定语言,(默认为英文) |
| --psm N | Set Tesseract to only run a subset of layout analysis and assume a certain form of image. The options for N are:(取值:0-9 ) |
| --oem N | 指定OCR 引擎所使用的模式(取值:0,1,2,3) |
| configfile | 指定(hocr ,pdf) |
单独的命令选项
| 参数 | 解释 |
|---|---|
| -h | 帮助信息 |
| --help-psm | 显示分页模式 |
| --help-oem | 显示引擎模式 |
| -v | 版本信息 |
| --list-langs | 查看当前可以使用的语言库 |
| --print-parameters | 打印tesseract的控制参数 |
命令使用举例
指定语言识别:
tesseract myscan.png out -l chi_sim (解释:使用中文简体识别图片myscan.png,将识别的字符输出到out.txt文件中)
多语言共同识别:
tesseract myscan.png out -l eng+chi_sim (解释:使用英文、中文简体进行字符识别......)
hello world
以识别中文字符为例:
1.安装程序
2.添加中文语言库
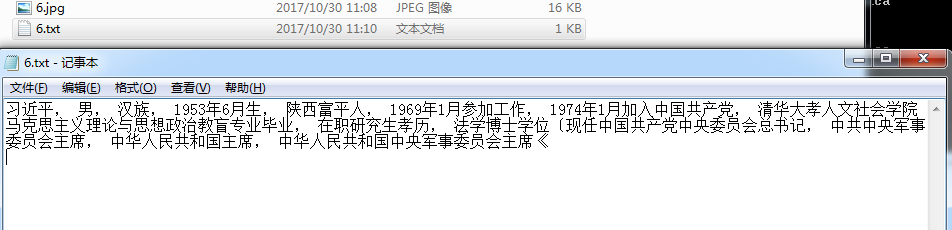
3.找一张中文图片,如下
4.执行识别命令:tesseract 6.jpg 6 -l chi_sim。 生成6.txt文件,内容如下
5.结果:完美,在图片清晰的情况下,基本可以比较完美识别中文字符。
6.(同一个图片降低清晰度,识别精准度将大打折扣)。

字符识别准确率的影响因素
在线文档:https://github.com/tesseract-ocr/tesseract/wiki/ImproveQuality
一、图像字符识别的影响因素
1.调整图像比例
图像DPI至少为300时,识别效果会更好。
2.图像二值化
tesseract内部会自动将图像二值化。但是,如果图片明暗不均匀,则最终的识别效果不会很好。

3.消除噪点
噪点主要是指将光线作为接收信号并输出的过程中所产生的图像中的粗糙部分,也指图像中不该出现的外来像素,通常由电子干扰产生。如果能够在拍摄期间就把噪点控制到最低,那么降噪工具就可能会退居二线了。
进行二值化处理的时候,一些噪点是无法消除的,所以噪点的大量存在会增加文字识别难度。
4.旋转和去偏移
Tesseract是进行直线扫描的。如果图像中的文字歪歪斜斜,会严重影响字符的识别精准度。如下:

5.祛除边界
很多时候,通过扫描得到的图片,周围会有黑色的边框(如下图)。Tesseract很可能会将边框转换为字符,当边框颜色渐进变化时,这种现象会更加严重。

二、Tools / Libraries (提高识别精准度可以使用的工具和库)
[Leptonica](http://leptonica.com/) (tesseract的内置库)
[OpenCV](https://opencv.org/)
[Scan Tailor](http://scantailor.sourceforge.net/)
[ImageMagick](http://www.imagemagick.org/script/index.php)
[unpaper](https://www.flameeyes.eu/projects/unpaper)
[ImageJ](https://imagej.nih.gov/ij/)
[Gimp](https://www.gimp.org)
三、使用合适的页面切割模式
使用 -psm 参数:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR.
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
四、字典、单词列表和模式
Tesseract内部仅仅默认,对句子中单词的识别进行优化。当需要识别收据、价格列表、代码等其它类型字符的时候,要使用一些设置并结合适合的页面分隔方法来提高识别的精确度。
1.如果识别的大部分内容不属于字典,禁用Tesseract使用的字典。将配置变量:load_system_dawg和load_freq_dawg设置为false来禁用它们。
2.在Tesseract的单词列表中添加词语来帮助识别,或者添加常用的字符模式。
3.如果之别的内容只有数字,可以指定仅识别数字:tesseract a.jpg out digits
Tesseract的控制参数
查看控制参数默认值及简单功能描述命令
tesseract --print-parameters
参数分为三种类型:
init only tesseract的初始化参数
general parameters 控制tesseract各方面的执行功能。
debug parameters 调试
Java中使用libtesseract引擎
tess4j
Tesseract 在多种语言上实现了封装接口。可以使用C、C++、C#、python、java等多种语言来使用libtesseract引擎来进行图像字符的识别。
其中,JAVA使用JNA包装器tess4j来实现对Tesseract OCR API的使用。可以在maven 中心仓库中找到tess4j。
tess4j主页地址http://tess4j.sourceforge.net/
tess4j支持
1、TIFF, JPEG, GIF, PNG, and BMP 格式的图片
2、多页 TIFF 图片
3、PDF 文档格式
tess4j包提供的图像识别及处理功能
1)用于图像处理的功能
生成tif、合并tif、获取像素数据、进行图像缩放、图像旋转、改变图像颜色、灰度化图像等
2)用于图像字符识别的功能
执行图像识别、设置tesseract初始化参数、设置语言库路径、指定识别语言、引擎模式、页面切割方法等
使用tess4j进行图像字符识别
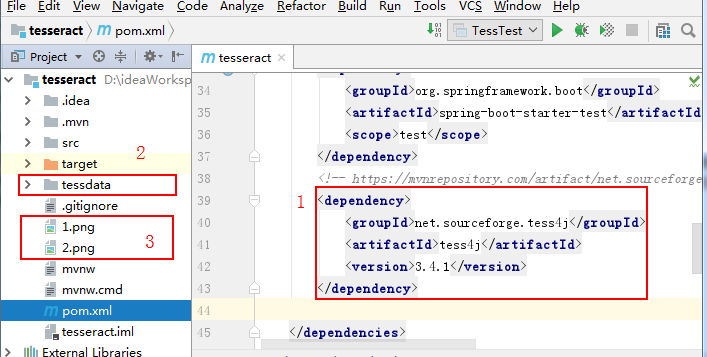
1、新建项目tesseract,使用maven引入tess4j。
2、将所需语言包tessdata文件夹放到根目录。
3、将要识别的图片放到根目录。如下图:
注:tess4j.jar and lept4j.jar包中内嵌了Tesseract, Ghostscript 和 Leptonica Windows 32- and 64-bit DLLs。因此,windows平台上不需要单独安装tesseract,在其它平台使用则要首先安装tesseract程序。
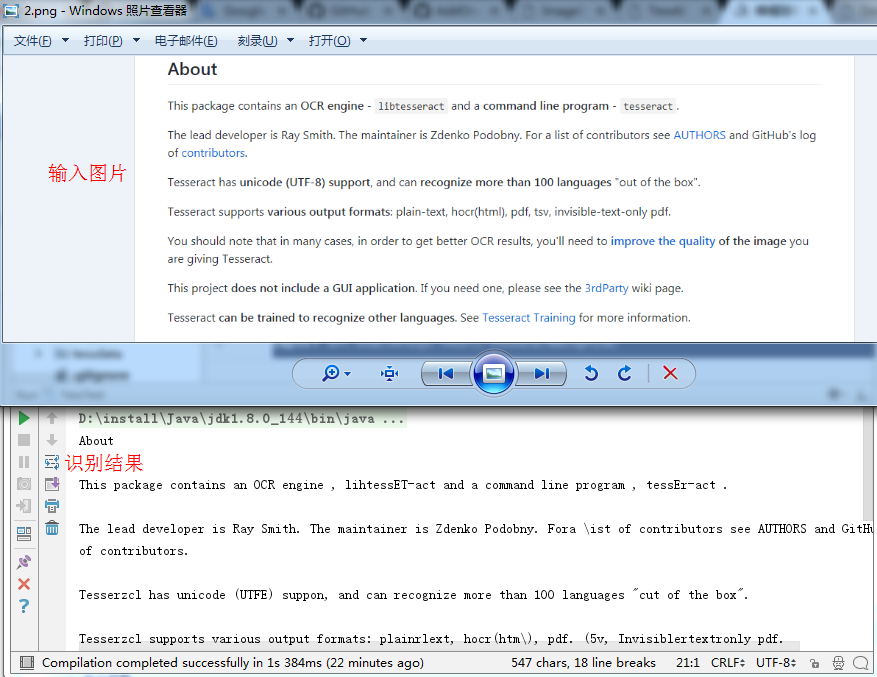
4、使用官网CodeDemo进行字符识别测试
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
public class TessTest {
public static void main(String [] args){
File imageFile=new File("2.png");
ITesseract instance=new Tesseract();//JNA Interface Mapping
try {
String result=instance.doOCR(imageFile);
System.out.println(result);
}catch (TesseractException e){
System.err.println(e.getMessage());
}
}
}
识别结果如下:
训练自己的语言库
一、Tesseract的语言库训练机制
1)Tesseract最初只是设计用来识别英文的。现在,tesseract内置的训练系统已经可以支持其它语言。
2)Tesseract提供了约一百种语言库供我们使用。但是,如果有需要,我们可以使用tesseract的训练机制来创建自己的语言库。
3)Tesseract 3.0开始,支持任何用UTF-8编码的Unicode字符。
4)在处理拥有大量字符集的语言时速度很慢(比如中文),但是依然可以良好的进行识别。
5)Tesseract需要将不同的字体分开,来识别相同字符的不同形状。训练的字体种类限制在64种。运行时的状态严重依赖于所提供字体的数量,一般、使用32个以上字体进行训练就会导入运行速度的显著降低。
二、数据文件的准备
1)要训练自己的语言库,需要构建一系列的基础数据文件,然后使用combine_tessdata命令将基础数据文件合并为语言库lang.traineddata即可。
2)例如:英文语言库--》eng.traineddata的基础数据文件如下,有些数据文件是必须的、有一些是可选的(虽然是可选的,但是在必要的时候可以提高语言库的准确性)
eng.config
eng.unicharset(必须)
eng.unicharambigs
eng.inttemp(必须)
eng.pffmtable(必须)
eng.normproto(必须)
eng.punc-dawg
eng.word-dawg
eng.number-dawg
eng.freq-dawg
三、训练程序
1、创建训练要使用的图片和box file
1)图片为训练需要的png、jpg、tif等文件。
2)box file 是 包含图片里字符坐标信息(该坐标为字符周围边框的坐标)的文本文件,每一个行一个字符(一个box file和一个图片相对应,称为tif/box文件对)。
使用命令:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
3)最难最关键的一步:打开box文件,将识别错的字符改正,将一个字符识别为多个的改正。
识别错误少的情况下可以手动修改,但是当错误量多而复杂的时候,手工几乎是不可能完成的(下文会给予实例说明)。
需要使用tesseractbox编辑器来完成字符纠错工作。官网推荐基于各种语言的工具:https://github.com/tesseract-ocr/tesseract/wiki/AddOns
2.使用Tesseract的训练模式执行语言库训练
使用训练模式来执行image/box 文件对,使用命令:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] box.train
生成[lang].[fontname].exp[num].tr 文件,该文件包含了语言库中所有字符的特征。
3.生成unicharset文件
该unicode字符集文件包含了经过tesseract引擎训练的每一个unicodez字符的信息。
使用命令:
unicharset_extractor lang.fontname.exp0.box lang.fontname.exp1.box ...
4.对提取的字符特征进行聚类处理,生成字符的形态特征
使用命令:
1)shapeclustering
shapeclustering -F font_properties -U unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr ...' 生成文件: shapetable(对字符聚类生成的主形状表) 2)mftrainingmftraining -F font_properties -U unicharset -O lang.unicharset lang.fontname.exp0.tr lang.fontname.exp1.tr ...生成文件: inttemp(形状原型) pffmtable(每个字符的预期特征数) 3)cntrainingcntraining lang.fontname.exp0.tr lang.fontname.exp1.tr ...`
生成文件:
normproto(字符归一化灵敏度原型)
5.合并数据文件
执行命令:
combin_tessdata lang.
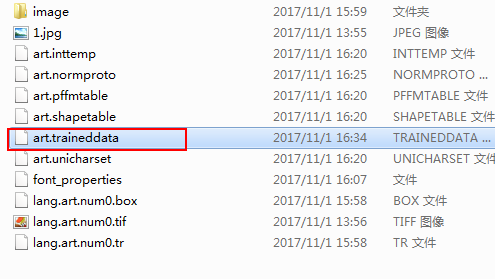
命令完成即可生成语言包 art.traineddata
四、训练实例:
1.创建训练要使用的图片和box file
1)训练字符集:“中、华、人、民、共、和、国”。创建图片,命名为 lang.art.num0.tif :
2)创建对应的box file(使用-l chi_sim指定用中文简体来识别)
tesseract lang.art.num0.tif lang.art.num0 -l chi_sim batch.nochop makebox
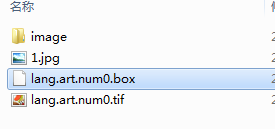
生成lang.art.num0.box文件:
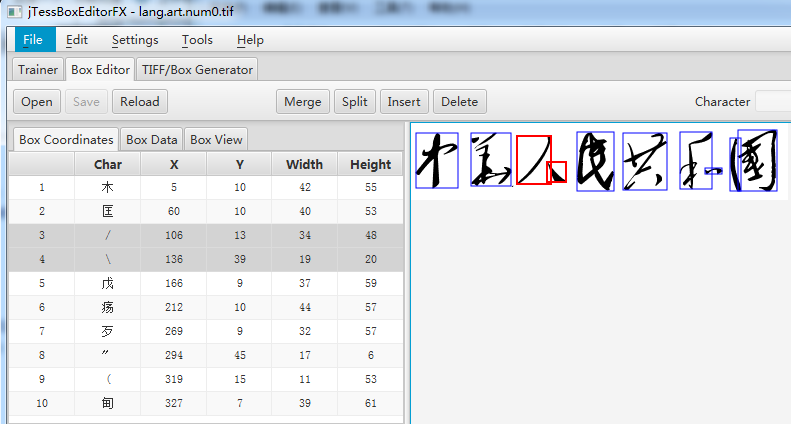
3)打开box文件,进行纠错处理(本文使用jtesseditor),主要分为以下三步:
第一、将下图中错误的文字改正。
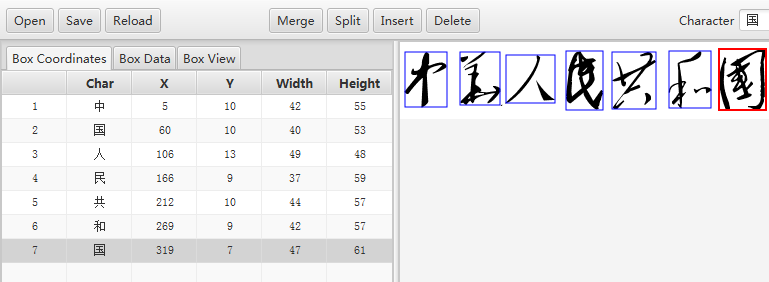
第二、将1个字符识别为多个字符的行合并(例如:合并3、4两行,包括字符和坐标的合并)。
第三、将多个字符识别成一个字符的进行字符分割(此例中没有出现,这种情况将比合并更加复杂)
对于需要合并或者拆分的情况,如果不借助工具,而直接手工编辑box文件来纠错,几乎是不可能完成的事情。
纠错后的box文件如下:

2.训练语言库
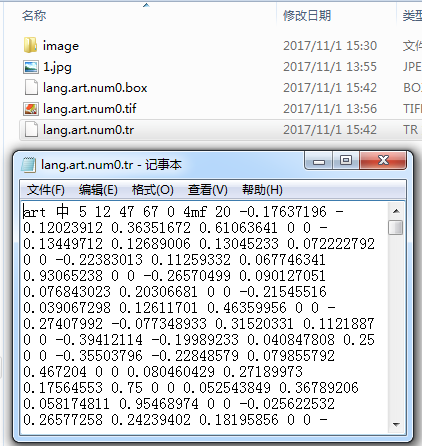
执行命令:
tesseract lang.art.num0.tif lang.art.num0 box.train
生成 lang.art.num0.tr 文件:
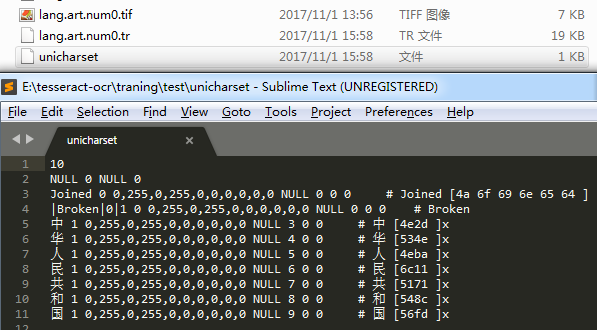
3.生成unicharset文件
unicharset_extractor lang.art.num0.box
4.对提取的字符特征进行聚类处理,生成字符的形态特征
1)执行命令:
shapeclustering -F font_properties -U unicharset lang.art.num0.tr' 2)执行命令:mftraining -F font_properties -U unicharset -O unicharset lang.art.num0.tr3)执行命令:cntraining lang.art.num0.tr`
5.合并数据文件
1)将art.作为上面生成数据文件(shapetable, normproto, inttemp, pffmtable, unicharset)的前缀
2)执行命令:
combine_tessdata art.
生成语言包:
6.使用自己的语言包进行字符识别
1)将art.traineddata语言包放到电脑上安装的tesseract的语言库中
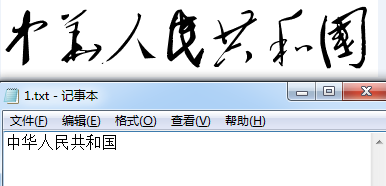
2)识别图像:
tesseract 1.jpg 1 -l art
识别成功:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号