高性能队列Disruptor系列2--浅析Disruptor
目录
1. Disruptor简单介绍
2. 为什么Disruptor如此之快
3. Disruptor结构分析
1. Disruptor简单介绍
Disruptor是一个由LMAX开源的Java并发框架。LMAX是一种新型零售金融交易平台,这个系统是建立在 JVM 平台上,核心是一个业务逻辑处理器,它能够在一个线程里每秒处理 6 百万订单。业务逻辑处理器完全是运行在内存中(in-memory),使用事件源驱动方式(event sourcing),具有低延迟,高吞吐的特性。
disruptor有多快?官方给出了和ArrayBlockingQueue的比较图表:
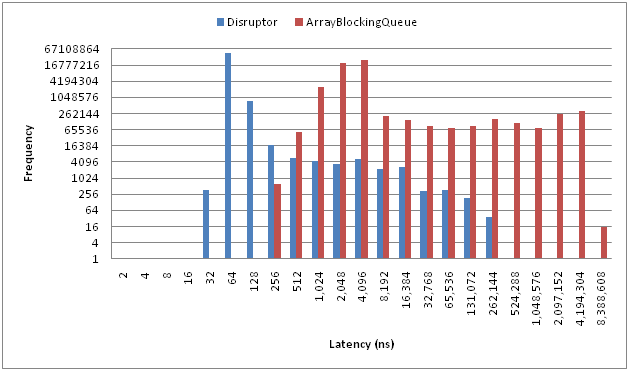
Disruptor可以用来解决并发编程中的一个普遍的问题: 消息队列的处理(producer和consumer)。
2. 为什么Disruptor如此之快
Disruptor 相对于传统方式的优点:
- 无锁,没有竞争
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构
- 缓存行填充,解决伪共享,提高cache命中率
- 环形数组RingBuffer,避免GC开销
3. Disruptor结构分析
在了解disruptor如何工作之前,我们先看一下disruptor一些重要组件的介绍(翻译自官方文档,略有修改):
- Ring Buffer:Ring Buffer通常被认为是Disruptor的主要方面,但是从3.0开始Ring Buffer只负责数据(Events)的存储和更新。对于一些高级用例,完全可以由用户自己替换。
- Sequence:Disruptor利用Sequences来标志一个特定的组件,每一个消费者(EventProcessor)都维护一个Sequence。Disruptor中大多数的并发代码都是依赖于这些Sequence的移动,生产者对RingBuffer的互斥访问,生产者与消费者之间的协调以及消费者之间的协调,都是通过Sequence实现。几乎每一个重要的组件都包含Sequence。由于需要在线程间共享,所以Sequence是引用传递,并且是线程安全的;再次,Sequence支持CAS操作;最后,为了提高效率,Sequence通过padding来避免伪共享。
- Sequencer:Sequencer是Disruptor的真正的核心,此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。
- Sequence Barriers:Sequence Barriers是由Sequencer创建的,包含Sequencer主发布的Sequence的引用和任何一个依赖消费者的Sequences。它包含了判断是否有任何事件可供消费者处理的逻辑。
- Wait Strategy:等待策略决定了消费者会等待event被生产者放入Disruptor。Disruptor提供了多个等待策略的实现。1. BusySpinWaitStrategy:自旋等待,类似Linux Kernel使用的自旋锁。低延迟但同时对CPU资源的占用也多。2. BlockingWaitStrategy :使用锁和条件变量。CPU资源的占用少,延迟大。3. SleepingWaitStrategy :在多次循环尝试不成功后,选择让出CPU,等待下次调度,多次调度后仍不成功,尝试前睡眠一个纳秒级别的时间再尝试。这种策略平衡了延迟和CPU资源占用,但延迟不均匀。5. YieldingWaitStrategy :在多次循环尝试不成功后,选择让出CPU,等待下次调度。平衡了延迟和CPU资源占用,但延迟比较均匀。6. PhasedBackoffWaitStrategy :上面多种策略的综合,CPU资源的占用少,延迟大。
- Event:数据从生产者传递给消费者的数据单元。
- EventProcessor:处理Disruptor中的events的主事件循环,拥有消费者Sequence的所有权。其中BatchEventProcessor即实现了有效率的event loop,而且可以回调给实现了EventHandler接口的类。
- EventHandler:Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是Consumer的真正实现。
- Producer:即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
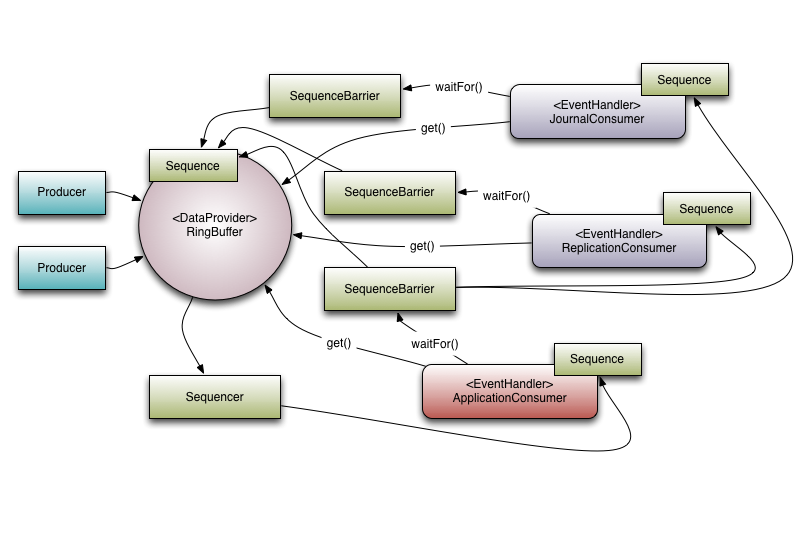
将这些元素放入Disruptor的context中,Disruptor的整体结构图如下:
多播事件
Queue和Disruptor之间最大的差异。当有多个消费者监听在同一Disruptor的所有事件,一个单一的事件只会被发送到一个单一的消费者。Disruptor一个使用的case是当你需要对同样的数据进行不一样的操作的时候。LMAX典型的例子是,我们有三个操作,日志(输入数据写入持久性日志文件),复制(将输入数据发送到另一台机器以确保有数据的远程复制),和业务逻辑(实际处理工作)。普通的Executor-style处理,可能是利用WorkPool并行的来处理这些不同的事件。这样却不是实现这个目标最有效的途径。
如上图所示,我们有三个EventHandler(JournalConsumer, ReplicationConsumer and ApplicationConsumer)监听着Disruptor,每一个Handler都会顺序的收到Disruptor里所有可用的消息,这样就使得这些消费者可以并行的处理这些消息了。
为了支持现实中并行处理的应用,必须支持消费者之间的协调。回到上面的例子,防止业务逻辑的消费还在继续,日志和复制的消费者已经完成了他们的任务是必须的。我们把这个概念称为门,或者更准确地说,这个行为的超级集合的特征叫做门。门发生在两个地方。首先,我们需要确保生产者不超过消费者。这是通过添加有关消费者到Disruptor时通过调用RingBuffer.addgatingconsumers() 实现的。其次,通过实现一个SequenceBarrier(内存屏障)的结构可以实现必须先完成某些操作的需求。
参考图1,有三个消费者监听唤醒队列中的事件,在图中有一个依赖图,ApplicationConsumer依赖于 JournalConsumer 和 ReplicationConsumer,这就说明 JournalConsumer 和 ReplicationConsumer可以互相自由的并发,这层依赖关系可以从 ApplicationConsumer的 SequenceBarrier连接到 JournalConsumer和 ReplicationConsumer的 Sequences看出来。值得注意的是 Sequencer和下游消费者之间的关系。作用之一就是确保发布不会覆盖Ring Buffer。为了做到这一点,下游消费者没有一个序列比RingBuffer的Sequence还要小,比RingBuffer的size还要小,然而,利用这个依赖图可以做一些有意思的操作,因为ApplicationConsumers Sequence是小于JournalConsumer 和 ReplicationConsumer(这就是依赖图所保证的),Sequencer只用关注ApplicationConsumer的Sequence即可,其实一般意义上,Sequencer只用知道消费者的Sequences依赖树中的叶子节点即可。
事件预分配
Disruptor的设计的一个目标就是能被用在一个低延迟的环境中。在低延迟系统中,必须减少或移除内存分配操作,基于Java开发的目的就是减少垃圾回收。(在低延迟的C/C++系统中,大内存分配也存在问题,因为内存分配器也会存在竞争)
为了实现低延迟,Disruptor允许用户对事件的内存进行预分配,在构造过程和用户提供的EventFactory中都会在Disruptor 的 RingBuffer中为每个实体分配。当发布新数据到Disruptor中,API就会允许用户获取构造方法的对象,以至于可以调用方法或者更新字段。Disruptor对这些操作提供并发安全性的保障。
可选的无锁操作
另一个关键的实现低延迟的细节就是在Disruptor中利用无锁的算法,所有内存的可见性和正确性都是利用内存屏障或者CAS操作。使用CAS来保证多线程安全,与大部分并发队列使用的锁相比,CAS显然要快很多。CAS是CPU级别的指令,更加轻量,不必像锁一样需要操作系统提供支持,所以每次调用不需要在用户态与内核态之间切换,也不需要上下文切换。
只有一个用例中锁是必须的,那就是BlockingWaitStrategy(阻塞等待策略),唯一的实现方法就是使用Condition实现消费者在新事件到来前等待。许多低延迟系统使用忙等待去避免Condition的抖动,然而在系统忙等待的操作中,性能可能会显著降低,尤其是在CPU资源严重受限的情况下,例如虚拟环境下的WEB服务器。
参考资料:
LMAX Disruptor
Spark性能优化指南——基础篇- - 美团点评技术团队
Disruptor入门


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?