
Pandas库的学习使用(一)
Pandas DataFrame基础知识
本章主要讲述pandas一些Pandas DataFrame的基础知识
1.1简介
Pandas [1] 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
1.2加载数据集
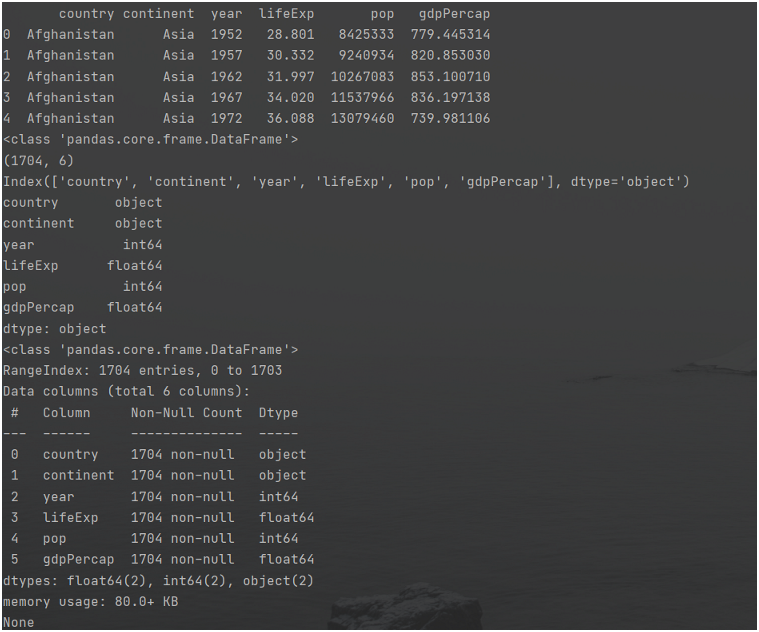
1 import pandas as pd 2 # file_path=(r'data/gapminder.tsv') 3 # df=pd.read_csv(r'C:\Users\123\Desktop\pandas_exerices\data\gapminder.tsv',sep=',')#输出的数据其中的符号为, 4 df=pd.read_csv(r'C:\Users\123\Desktop\pandas_exerices\data\gapminder.tsv',sep='\t')#输出的数据多一个table 5 print(df.head())#读取前5行的数据 6 print(type(df))#检查返回的数据是否为DataFrame 7 print(df.shape)#Read the shape of the data, namely rows and columns(rows,columns) 8 print(df.columns)#读取列名 9 print(df.dtypes)#读取每列的dtype 10 print(df.info())#获取更多信息
1.2查看列和行&单元格
1.2.1获取列子集
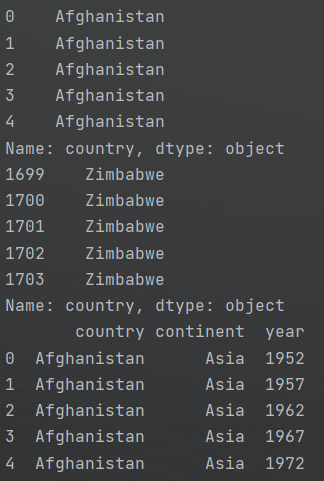
1 country_1=df['country']#读取数据集中名为country的一列的所有内容并且命名为country_1 2 print(country_1.head())#打印前五列 3 print(country_1.tail())#打印后五列 4 5 subset=df[['country', 'continent', 'year']]#通过列名指定多列 6 print(subset.head())
1.2.2获取行子集
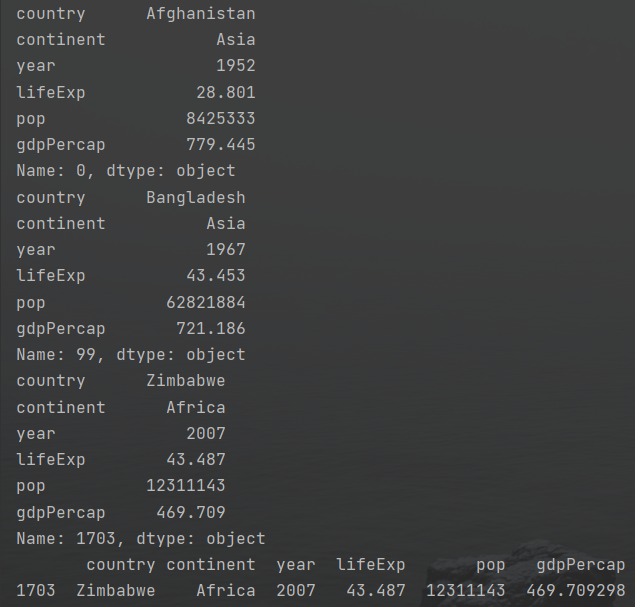
1 print(df.loc[0])#读取第一行,python从0开始计数 2 print(df.loc[99])#读取第100行 3 # print(df.loc[-1])无法读取该数据集,因为该数据集会从搜索-1行 4 number_of_rows=df.shape[0] 5 last_row=number_of_rows-1 6 print(df.loc[last_row]) 7 print(df.tail(n=1))#tail和loc输出的最后一行数据类型不同\
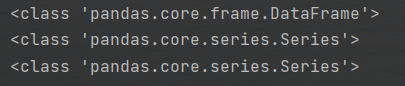
1 #tail和loc输出的最后一行数据类型不同 2 subset_1=df.loc[0] 3 subset_2=df.tail(1) 4 subset_3=df.iloc[0] 5 print(type(subset_2)) 6 print(type(subset_1)) 7 print(type(subset_3))
1.2.2.2

1.2.3混合
1.2.3.1 获取列子集
1 #使用loc获取列子集 2 #注意冒号使用位置 3 #冒号用于选择所有行 4 #df.iloc[:,[列]]获取列子集 5 subset = df.loc[:, ['year', 'pop']] 6 print(subset.head()) 7 #iloc支持使用整数 8 #iloc支持-1选择最后一列 9 subset = df.iloc[:,[1,0,-1]] 10 print(subset.head()) 11 #通过范围选择列子集 12 print("*"*100) 13 small_range =list(range(0,6)) 14 print(small_range) 15 subset = df.iloc[:,small_range] 16 print(subset.head()) 17 18 large_range =list(range(3,6)) 19 print(large_range) 20 subset =df.iloc[:,large_range] 21 print(subset.head()) 22 # super_range =list(range(100)) 23 # subse_big =df.iloc[:,super_range] 24 # print(subse_big.head()) 25 # IndexError: positional indexers are out-of-bounds 26 print(df.columns) 27 subset = df.iloc[:,:3]#获取前三列 28 print(subset.head()) 29 subset = df.iloc[:,3:6]#获取第4 5 6列数据 30 print(subset.head()) 31 subset = df.iloc[:,0:6:2]#2为步长,此处获取的是1,3,5 32 subset = df.iloc[:,0:6:3]#3为步长,此处获取的是1,4列 33 subset = df.iloc[:,::] 34 print(subset.head())
1 #使用loc 2 print(df.loc[42,'country']) 3 #使用iloc 4 print(df.iloc[42,0])
df.iloc[:,:0:6:1]=df,iloc[:,::]=df.iloc[:,0:6:]=df.iloc[:,0::1]=…
1.2.4获取行和列的子集
1 #使用loc 2 print(df.loc[42,'country']) 3 #使用iloc 4 print(df.iloc[42,0])
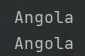
1 #获取continentpopgdpPercap 2 print(df.iloc[[99,98,64],[1,4,5]]) 3 print(df.loc[[99,98,64],['continent','pop','gdpPercap']]) 4 #注意,在iloc和loc行部分可以使用切片语法 5 print(df.iloc[10:15,[2,4,5]]) 6 print(df.loc[10:15,['year','pop','gdpPercap']])
1.4分组和聚合计算
1.4.1分组方式
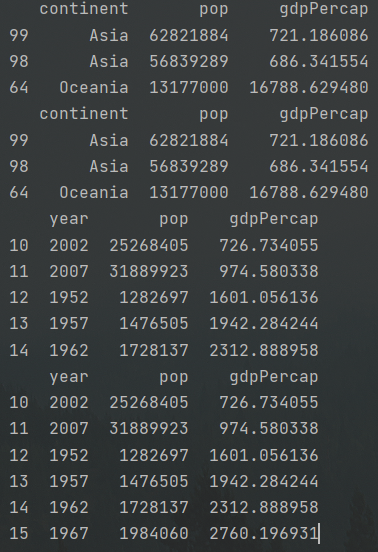
1 #分组计算 2 print(df.groupby('year')['lifeExp'].mean()) 3 #详细解释 4 groupby_year_df=df.groupby('year') 5 print(groupby_year_df) 6 print(type(groupby_year_df)) 7 #step2 8 print("*"*100) 9 groupby_year_df_lifeExp=groupby_year_df['lifeExp'] 10 print(groupby_year_df_lifeExp) 11 print(type(groupby_year_df_lifeExp)) 12 13 mean_lifeExp_by_year=groupby_year_df_lifeExp.mean() 14 print(mean_lifeExp_by_year)
#计算每个国家的平均寿命 print(df.groupby('country')['lifeExp'].mean().head(10))
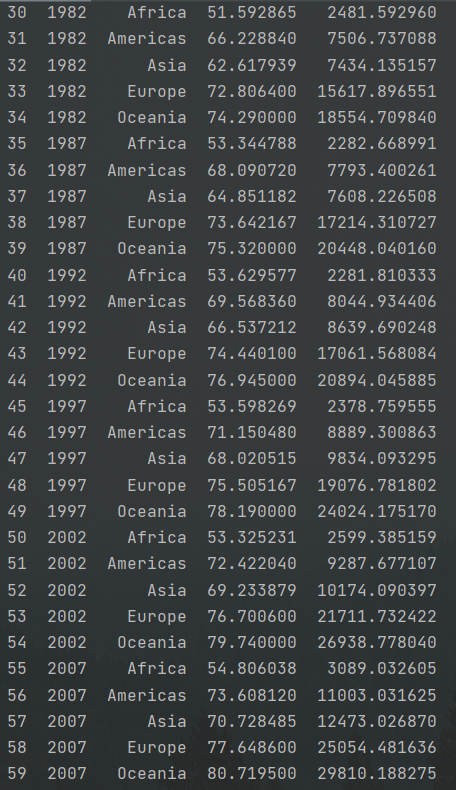
#计算国家gdp和平均年龄 print(df.groupby(['year','continent'])[['lifeExp','gdpPercap']].mean())
#平铺数据 falt=df.groupby(['year','continent'])[['lifeExp','gdpPercap']].mean().reset_index() print(falt)
1.4.2分组频率计数
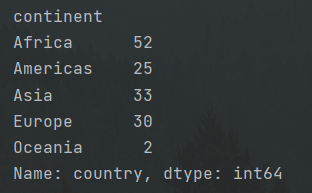
#计算频率各大洲国家出现的频率 print(df.groupby('continent')['country'].nunique())
1.5基本绘图
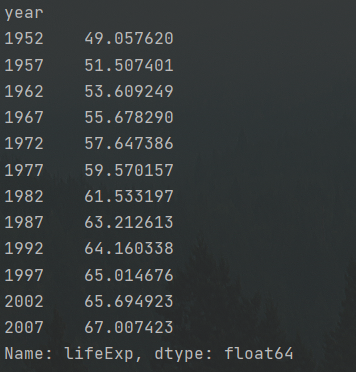
1 global_yearly_life_expectancy=df.groupby('year')['lifeExp'].mean() 2 print(global_yearly_life_expectancy) 3 global_yearly_life_expectancy.plot()
Day 2复习
1 import pandas as pd 2 df=pd.read_csv(r'C:\Users\123\Desktop\pandas_exerices\data\housing.csv',sep=',') 3 print(df.head())#读取头文件前5行 4 print(df.columns)#读取列名 5 #计算'Neighborhood'的平均、'Year.Built' 6 year_groupby = df.groupby('Neighborhood')['Year.Built'].mean().reset_index() 7 print(year_groupby) 8 year = df.groupby('Year.Built')['Boro'].nunique() 9 print(year) 10 print(df.iloc[:,::]) 11 print('*'*100) 12 print(df.iloc[:,[1,2,3]])#读取第二三四列 13 print('*'*100) 14 print(df.loc[10:15,['Building.Classification', 'Total.Units', 'Year.Built']]) 15 #读取第10-15行(row+1和'Building.Classification', 'Total.Units', 'Year.Built'列 16 print(df.tail(5))#读取倒数5行
