
初识爬虫
爬虫的本质是向一个网站或URL发送请求,获取资源后分析并提取有用数据的应用程序。它可以用来获取文本数据,也可以用来下载图片或音乐,还可以用来抢票。
爬虫的工作程序(三步走):
- 请求发送:确定需要爬取数据的目标url以及发送请求(request)时所需要携带的数据和各种HTTP头部信息。python3最常用的库 urllib和requests
- 数据解析:对返回的数据进行解析,提取我们所需要的信息。常用的库有:html.parser, beautifulsoup, lxml
- 数据存储:对第2步提取的数据,存入数据库或者写入磁盘文件(如csv文件)或缓存
例子:
简单的使用urllib库爬csdn首页的html代码:
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request if __name__ == '__main__': response = request.urlopen("https://www.csdn.net/") html = response.read() print(html)
运行上面的代码会爬出csdn首页的源代码。但是遇到中文字符时都是乱码。是因为python在解析网页时默认使用Unicode去解析,而大多数网站是utf-8格式的。我们需要使用html.decode('utf-8')对返回的数据进行解码。
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request if __name__ == '__main__': response = request.urlopen("https://www.csdn.net/") html = response.read() html = html.decode('utf-8') print(html)
如果不知道目标网页的编码格式,我们可以通过第三方库chardet自动获取目标网页的编码。常见的网页编码有 GB2312, GBK, utf-8 和unicode.
代码样例:
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request import chardet if __name__ == '__main__': response = request.urlopen("https://www.csdn.net/") html = response.read() chardet = chardet.detect(html) #返回字典 print(chardet['encoding']) html = html.decode(chardet['encoding']) print(html)
python3 的 urllib库介绍:
urllib库主要包含四个模块:
- urllib.request 基本的http请求模块。可以模拟浏览器向目标服务器发送请求
- urllib.error 异常处理模块。可以捕获异常
- urllib.parse 工具模块,提供url 处理方法。比如对URL进行编码和解码
- urllib.robopaser 用来判断哪些网站可以爬,哪些网站不可以爬
在刚才的例子中,我们用urlopen方法打开了一个实际的链接url。但在实际开发爬虫过程中,我们一般先构建request对象,再通过urlopen方法发送请求。这是因为构建的request url 可以包含GET参数或POST 数据以及头部信息。这些信息是普通的url 不能包含的。
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 #使用request_url from urllib import request import chardet if __name__ == '__main__': request_url = request.Request("https://www.csdn.net") response = request.urlopen(request_url) html = response.read() chardet = chardet.detect(html) print(chardet['encoding']) html = html.decode(chardet['encoding']) print(html)
使用urllib发送带参数的get请求:
例子:向csdn网站搜索页面模拟发送带参数get请求。 请求参数是 q=大江狗.返回数据是搜索结果。
- 使用urllib.urlencode方法对需要发送的get参数进行url编码
- 对url 进行拼接
- 添加请求头信息 (添加请求头的原因是很多网站服务器有反爬机制,一般不带请求头的访问都会被认为是爬虫,从而禁止它们的访问)
csdn搜索页面的链接和搜索参数:

代码:
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request import urllib.parse import chardet if __name__ == '__main__': url = "https://so.csdn.net/so/search/s.do" params = {'q':'大江狗',} header = { "User-Agent": " Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", } #使用parse方法对参数进行URL编码 encoded_params = urllib.parse.urlencode(params) #拼接后的request地址 request_url = request.Request(url+"?"+encoded_params,headers=header) response = request.urlopen(request_url) html = response.read() chardet = chardet.detect(html) print(chardet['encoding']) html = html.decode(chardet['encoding']) print(html)
使用urlib发送post数据:
模拟向一个网站提交表单数据。可以通过构建request对象并加入POST数据,然后使用urlopen方法发送请求。与get请求不同的是url无需要拼接。需要发送的参数也不会出现在url里
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request import urllib.parse import chardet if __name__ == '__main__': url = "some_url" post_data = {'name':'大江狗',} header = { "User-Agent": " Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", } #使用parse方法对参数进行URL编码 encoded_data = urllib.parse.urlencode(post_data).encode('utf-8') #使用urllib发送POST数据无需拼接URL request_url = request.Request(url,headers=header,data=encoded_data) response = request.urlopen(request_url) html = response.read() chardet = chardet.detect(html) print(chardet['encoding']) html = html.decode(chardet['encoding']) print(html)
爬取有道翻译上的英文翻译的例子:(在debug的network中查看真正的url)
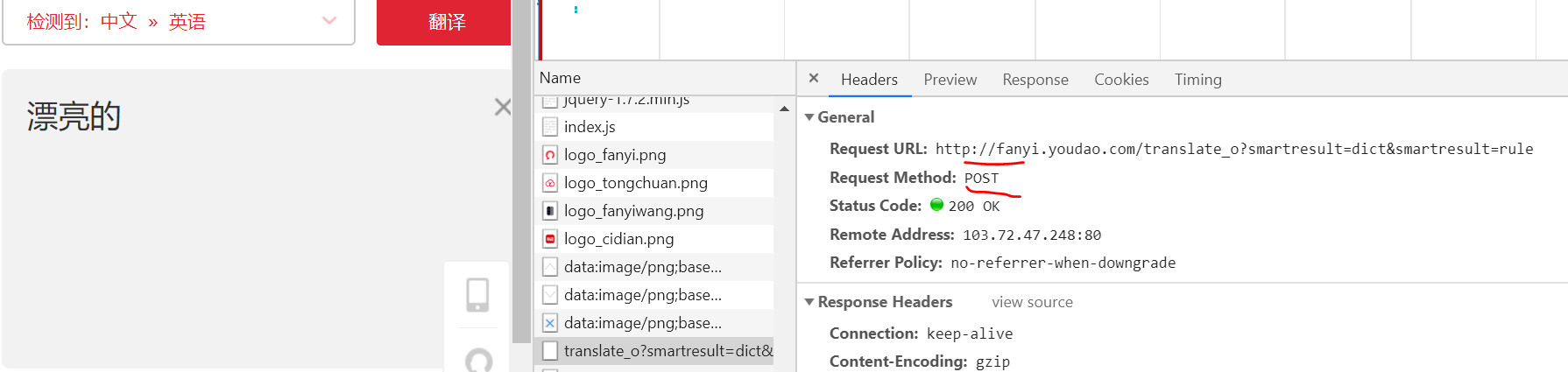

如果请求方式是POST,我们一定还有了解POST什么数据,服务器才会返回正确的响应:network的 header 可以找到:词,salt和sign.我们在请求里必须把这些data加进去,有道才会返回反应结果。
#-*- coding: UTF-8 -*- #使用 urllib库开发一个最简单的爬虫 爬csdn首页的html代码 from urllib import request from urllib import parse import time import random import hashlib import json import chardet '''使用urlopen(request_url,data)发送参数''' if __name__ == '__main__': url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" header = { 'Accept': 'application / json, text / javascript, * / *; q = 0.01', 'Accept - Encoding': 'gzip, deflate', 'Accept - Language': 'zh - CN, zh;q = 0.9', 'Connection': 'keep - alive', 'Content - Length': 251, 'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8', 'Host': 'fanyi.youdao.com', 'Origin': 'http: // fanyi.youdao.com', 'Referer': 'http: // fanyi.youdao.com /', 'User - Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0.3683.86 Safari / 537.36', 'X - Requested - With': 'XMLHttpRequest', } i = input("Translation for: ") client = "fanyideskweb" t = str(int(time.time()*1000)) salt = t+ str(random.randint(1,10)) c ='n%A-rKaT5fb[Gy?;N5@Tj' md5 = hashlib.md5() md5.update(client.encode('utf-8')) md5.update(i.encode('utf-8')) md5.update(salt.encode('utf-8')) md5.update(c.encode('utf-8')) sign = md5.hexdigest() print(salt) print(t) print(sign) data = { 'i': i, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client':client, 'salt': salt, 'sign': sign, 'ts': t, 'bv': '140f03b6cc43b5b1fabe089d78dc366f', 'doctype': 'json', 'version': '2.1', 'keyfrom':'fanyi.web', 'action':'FY_BY_REALTlME', } #使用parse方法对参数进行URL编码 data = parse.urlencode(data).encode('utf-8') #使用urllib发送POST数据无需拼接URL request_url = request.Request(url,data=data,headers=header) response = request.urlopen(request_url) print(response.getcode()) #200 表示成功 json_result = json.load(response) print(json_result) translation_result = json_result['translateResult'][0][0]['tgt'] print("翻译的结果是:%s" % translation_result)
'''
如何破解有道翻译:
1. 找到相应的 js 文件
2. 格式化 js 文件: http://tool.chinaz.com/Tools/jsformat.aspx
3. 找到关键字 salt (加密盐),然后实验和提取 sign参数
4. 有道翻译的链接是去掉_o。 参考:https://www.jianshu.com/p/2ae887299080
'''

异常处理:
我们必须学会如何捕获那些异常和处理那些异常。urllib.error的模块包括两种主要错误:URLError(坏链接)和 HTTPError. (没有相应的权限).
import urllib.error try: urllib.request.urlopen('htt://www.baidu.com') except urllib.error.URLError as e: print(e.reason) try: urllib.request.urlopen('http://www.baidu.com/admin') except urllib.error.HTTPError as e1: print(e1.reason) print(e1.code)
显示本机ip的爬虫例子:(爬 whatismyip.com 站点)
# -*- coding: UTF-8 -*- from urllib import request import re if __name__ == "__main__": # 访问网址获取IP url = 'https://www.whatismyip.com/ip-address-lookup/' header = { "User-Agent": " Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", } # 构建request对象 request_url = request.Request(url, headers=header) # 发送请求获取返回数据 response = request.urlopen(request_url) # 读取相应信息并解码,并利用正则提取IP html = response.read().decode("utf-8") pattern = re.compile(r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b') ip_list = re.findall(pattern, html) print(ip_list[0])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号