669~670 xml的Jsoup快速入门 AND xml解析Jsoup对象
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。
它提供了一套非常省力的API,可通过DOMCSS以及类似于jQuery的操作方法来取出和操作数据但是用来解析xml也没问题
快速入门:
步骤:
1.导入jar包
2.获取Document对象
3.获取对应的标签Element对象
4.获取数据
jsoupDemo01
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/*
Jsoup快速入门
*/
public class jsoupDemo01 {
public static void main(String[] args) throws IOException {
//获取Document对象,根据xml文档来获取
String path = jsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--》Document
Document document = Jsoup.parse(new File(path), "utf-8");
//获取元素对象Element 可以当作一个集合来看
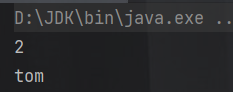
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//获取都一个name的Elements对象
Element element = elements.get(0);
//获取数据
String text = element.text();
System.out.println(text );
}}
----------------------------
student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="heima_0001">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="heima_0002">
<name>cat</name>
<age>18</age>
<sex>female</sex>
</student>
</students>
xml解析Jsoup对象
对象的使用
1.Jsoup:工具类,可以解析html或xml文档,返回Document
parse:解析html或xml文档,返回Document
parse(File in, String charsetName):解析xml或http文件的
parse(String html):解析xml或html字符串
parse(URL url ,int timeotMillis):通过网络路径获取指定的html或xml的文本对象
2.Document:文档对象。代表内存中的dom树
3.Elememts元素Element对象的集合。可以当作ArrayList<Element>来使用
4.Elememts:元素对象
5. Node:节点对象
package cn.itcast.xml.jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URL;
/*
Jsoup快速入门
*/
public class jsoupDemo02 {
public static void main(String[] args) throws IOException {
//获取Document对象,根据xml文档来获取
String path = jsoupDemo02.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--》Document
/*第一种方式
Document document = Jsoup.parse(new File(path), "utf-8");
System.out.println(document );
*/
//第二中方式parse(String html)解析xml或html字符串
/*
String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"\n" +
"<students>\n" +
" \t<student number=\"heima_0001\">\n" +
" \t\t<name>tom</name>\n" +
" \t\t<age>18</age>\n" +
" \t\t<sex>male</sex>\n" +
" \t</student>\n" +
"\n" +
"\t<student number=\"heima_0002\">\n" +
"\t\t<name>cat</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>female</sex>\n" +
"\t</student>\n" +
"\n" +
"</students>";
Document parse = Jsoup.parse(str);
System.out.println(parse);
*/
//第三种 parse(URL url ,int timeotMillis):通过网络路径获取指定的html或xml的文本对象
URL url = new URL("https://www.baidu.com");//代表网络种的一个资源路径
Document parse = Jsoup.parse(url, 10000);
System.out.println(parse);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号