【无监督机器学习】10.强化学习
强化学习
强化学习概念
强化学习是一种无监督学习,它的目标是从环境中学习,以达成某种目标。强化学习的核心是奖励函数,通过与环境的交互,获得环境的反馈,从而学习到奖励函数,最终达成目标。
与监督学习不同的是,强化学习并未给出正确的答案,而是根据奖励一步步学习,因此强化学习的训练过程是一个不断试错的过程。
强化学习的回报
回报
强化学习的目标是最大化回报,回报的定义为:
其中,\(\gamma\)为折扣因子,\(0\leq\gamma\leq1\),\(\gamma\)越大,越重视未来的奖励,\(\gamma\)越小,越重视当前的奖励。
当激励为负值时,折扣因子会将负激励推的尽可能远。
策略
策略\(\pi\)是在每个状态下,采取哪个行动可以获得最大回报的概率,即:
马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process,MDP)是强化学习的数学框架,他说明了未来仅仅与当前状态有关,与过去无关。
马尔可夫决策过程由五元组\((S,A,P,R,\gamma)\)组成:
- \(S\):状态集合
- \(A\):行动集合
- \(P\):状态转移概率矩阵,\(P_{ss'}^a=P(s_{t+1}=s'|s_t=s,a_t=a)\)
- \(R\):奖励函数,\(R_s^a=E[r_{t+1}|s_t=s,a_t=a]\)
- \(\gamma\):折扣因子
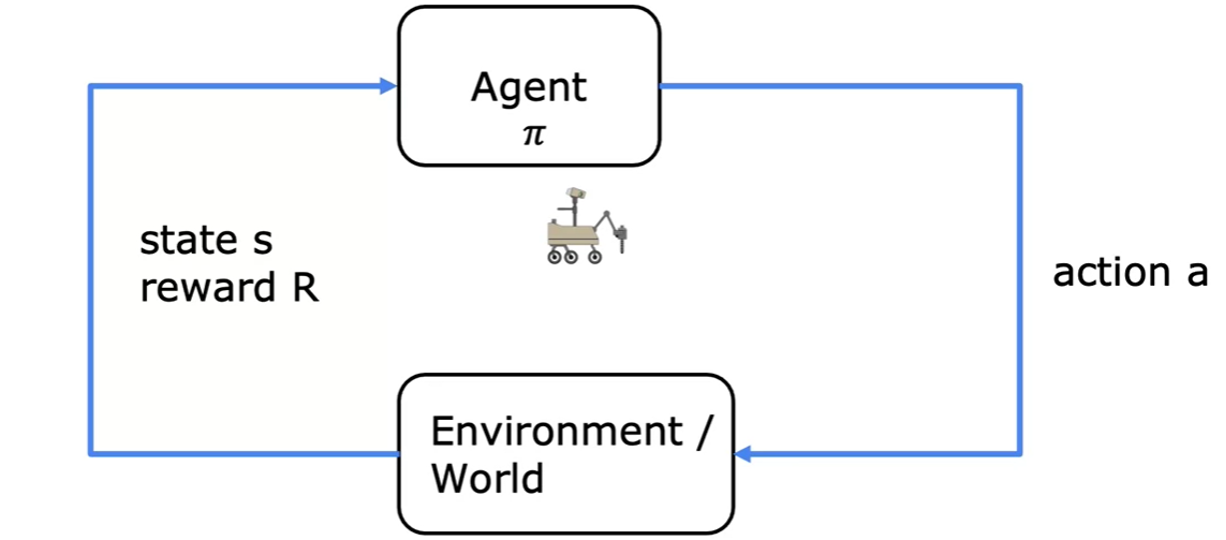
状态动作值函数
状态动作值函数定义
状态动作值函数(State-Action Value Function,Q函数)是在状态\(s\)下,采取行动\(a\),之后按最优策略继续执行,获得的回报值,即:
期望的原因是:在同一个状态下,采取同一个行动,获得的回报值不一定相同,因为环境是随机的。例如:策略为左移,但是环境中的障碍导致无法左移而选择了其他行动。
贝尔曼方程
贝尔曼方程是状态动作值函数的递归表达式,它表示当前状态动作值函数等于下一个状态动作值函数加上当前的奖励,即:
离散状态和连续状态
对于状态\(S\),有两种情况:
- 离散状态:状态\(S\)是离散的,例如:棋盘游戏中的棋子位置
- 连续状态:状态\(S\)是连续的,例如:机器人的位置
在离散状态里,状态可以直接记录为一个整数,例如:棋盘游戏中的棋子位置可以记录为棋盘上的行列坐标。
在连续状态里,状态可以记录为一个向量,包括当前位置以及趋势等信息。例如飞行中的直升机,可以记录坐标位、左右转向、上下转向、罗盘方向等,同时也可以记录速度等信息。
深度强化学习
深度强化学习是强化学习和深度学习的结合,它的目标是使用深度学习来解决强化学习中的问题。
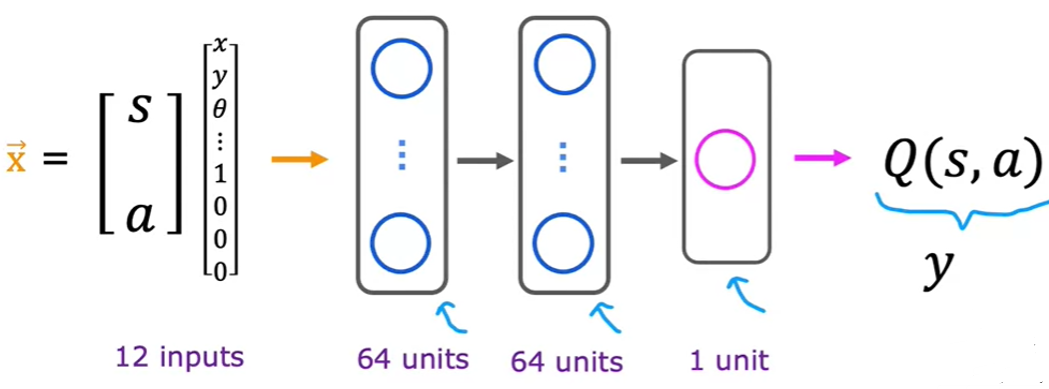
在深度深度学习中,可以将状态和行动映射为状态动作值函数,通过计算得到不同行动的状态动作值函数,然后选择状态动作值函数最大的行动,作为当前状态下的最优行动。
训练集的构建
利用贝尔曼方程,可以构建训练集,训练集的输入为状态\(s\),输出为状态动作值函数\(Q(s,a)\)。
通过不断的尝试,可以产生大量的状态\(s\)和行动\(a\),然后通过贝尔曼方程,计算状态动作值函数\(Q(s,a)\),从而构建训练集。
神经网络的构建
- 以一个随机的\(Q(s,a)\)初始化神经网络
- 创建训练集
- 采取行动,获得\((s,a,R(s),s')\)
- 记录最近的\(N\)个\((s,a,R(s),s')\)
- 训练神经网络
- 从最近的\(N\)个\((s,a,R(s),s')\)中选择训练集
- 训练得到\(Q_{new}(s,a)\)
- \(Q_{new}(s,a)\)替换\(Q(s,a)\)
- 重复2-4步骤
神经网络的优化
神经网络架构的优化
在上图中的神经网络架构中,输出为某一个动作的\(Q(s,a)\),但是这样的架构有一个缺点,就是每次只能计算一个动作的\(Q(s,a)\),而实际上,可以同时计算多个动作的\(Q(s,a)\),从而提高计算效率。
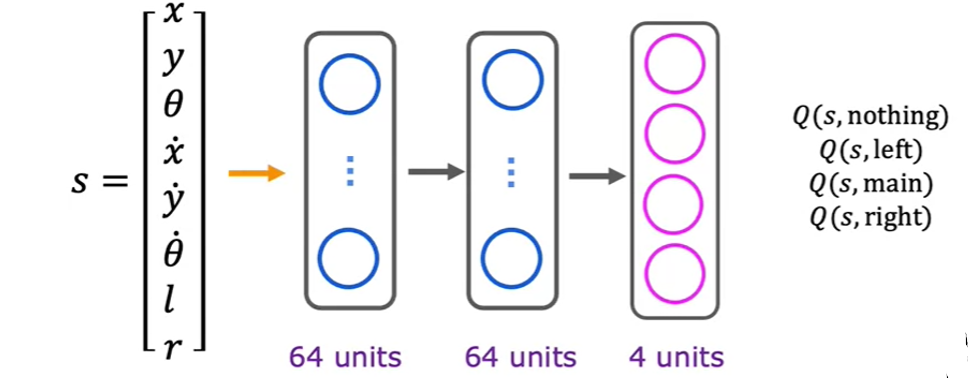
\(\epsilon\)-贪婪策略
在训练过程中,可以使用\(\epsilon\)-贪婪策略,即以\(\epsilon\)的概率随机选择行动,以\(1-\epsilon\)的概率选择最优行动。
采取这个策略的原因是:在训练过程中,需要一定的随机性,从而避免陷入局部最优。
小批量训练和软更新
当数据集很大时,每次更新神经网络的参数,需要计算所有的数据,这样的计算量很大,因此在训练过程中,可以使用小批量训练,即每次从训练集中随机选择一小批数据进行训练。
由于每次训练的数据都是随机选择的,因此每次训练的结果都不同,这样会导致训练结果不稳定,因此可以使用软更新,即每次更新时,使用一小部分的新参数,和一大部分的旧参数,从而保证训练结果的稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号