
【无监督机器学习】8.聚类和异常检测
聚类
聚类的定义
聚类是一种无监督学习,它将相似的对象归到同一个簇中。
聚类作为一种无监督学校,和分类的区别在于,分类的目标事先已知,而聚类的目标是事先不知道的。
聚类应用
聚类在很多领域都有应用,比如:
- 新闻文章分组
- 市场细分
- DNA分析
- 天文数据分析
聚类的算法 K-means
K-means是一种典型的聚类算法,它的基本思想是:以空间中K个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直到得到最好的聚类结果。
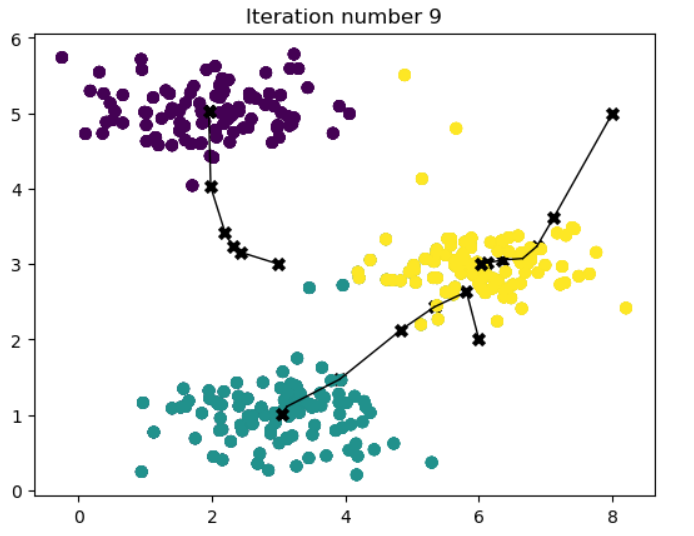
K-means算法流程
- 随机选择K个点作为聚类中心
- 计算每个点到聚类中心的距离,将每个点归到距离最近的聚类中心
- 重新计算每个聚类中心的值
- 重复2、3步骤,直到聚类中心的值不再变化
值得注意的是:
-
如果一个中心没有任何点被分配,那么这个中心就不再变化;在这种情况下,常见做法是消除该中心。如果希望保持K个中心,可以将重新初始化
-
K-means 也经常应用于簇之间没有明显分界的数据集
K-means算法的优化
成本函数
K-means算法的成本函数为:
其中,\(c^{(i)}\)表示样本\(x^{(i)}\)所属的簇,\(\mu_{c^{(i)}}\)表示样本\(x^{(i)}\)所属的簇的中心点。
K-means算法的步骤
- 分配数据点到最近的聚类中心
更新\(c^{(i)}\),使得\(J\)最小
- 重新计算聚类中心
更新\(\mu_k\),使得\(J\)最小
初始化聚类中心
通过随机选择K个点作为聚类中心,然后进行迭代,直到收敛。
但是,这种方法有一个缺点,就是可能会导致K-means算法收敛到局部最优解,而不是全局最优解。
为了解决这个问题,可以多次随机初始化,然后选择代价函数最小的结果。
选择聚类的数量
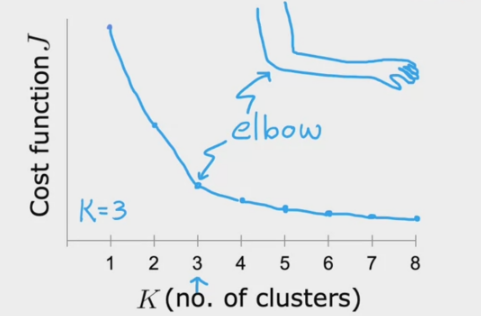
肘部法则
肘部法则是一种常用的方法,它的基本思想是:随着聚类数量的增加,每个点到聚类中心的距离会减小,但是随着聚类数量的增加,每个点到聚类中心的距离的收益会逐渐减小,直到某个点,再增加聚类数量,收益几乎不变。
根据下游任务选择聚类数量
聚类的目的是为了解决下游任务,所以可以根据下游任务的目标,选择聚类的数量。
比如,如果下游任务是对选择T-恤尺寸的用户进行分类,那么可以选择3个聚类,分别对应S、M、L三种尺寸。
异常检测
异常检测的定义
异常检测是一种无监督学习,它的目标是识别出与大多数其他实例显著不同的数据实例。
异常检测通过观察一组未标记的正常实例来学习正常性的概念,然后使用这个概念来识别异常实例。
异常检测的概念定义:
- 特征:算法需要一组特征来描述数据
- 密度估计:异常检测的的常见方法是使用密度估计,即假设正常数据点和异常数据点分布在不同的区域,然后使用概率来描述正常数据点的分布,从而识别异常数据点
- 概率阈值(epsilon,\(\epsilon\)):异常检测的算法需要一个概率阈值,用来判断一个数据点是正常还是异常
异常检测的应用
异常检测在很多领域都有应用,比如:
- 金融欺诈检测
- 制造业
- 机器故障检测
高斯分布
高斯分布也称为正态分布,它的概率密度函数为:
其中,\(\mu\)是均值,\(\sigma^2\)是方差。
高斯分布的图像如下:
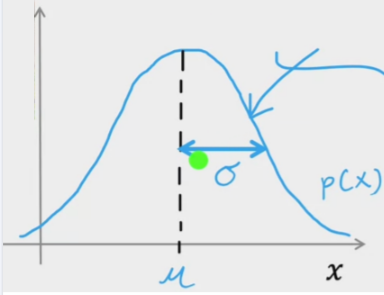
其中,\(\mu\)是均值,决定了图像的中心位置;\(\sigma^2\)是方差,决定了图像的宽度。
异常检测的算法流程
- 根据训练集,计算每个特征的均值和方差
- 使用均值和方差,构建高斯分布模型
- 对于新的数据点,计算概率,如果概率小于\(\epsilon\),则判断为异常
在具有多个特征的异常检测问题中,可以将每个特征看作是独立的,然后计算每个特征的概率,最后将每个特征的概率相乘,得到最终的概率。
开发和评估异常检测系统
- 实数评估:使用真实的异常数据,计算算法的准确率和召回率
- 使用标签数据:虽然异常检测主要关注无标签数据,但在实际应用中,有一小部分标签数据(如已知的异常样本)是非常有帮助的。这些标签数据可以用于创建交叉验证集和测试集,从而评估和改进算法。
- 分割数据集:将数据集分为训练集、交叉验证集和测试集,然后使用交叉验证集来选择\(\epsilon\),使用测试集来评估算法的性能。
- 处理高度偏斜的数据:如果异常数据只占很小的一部分,那么可以使用F1值来评估算法的性能。
异常检测的特征选择
异常检测中,选择恰当的特征非常重要:
高斯特征
确保特征符合高斯分布,如果不符合,可以使用对数函数、平方根函数等进行转换。
可以使用直方图来检查特征是否符合高斯分布。

异常特征
训练异常检测算法后,如果在交叉验证集上表现不佳,可以进行错误分析
创建新特征
可以通过创建新特征来提高算法的性能
异常检测和监督学习
异常检测和监督学习的区别在于:
- 异常检测的目标是识别出与大多数其他实例显著不同的数据实例,这种方法在未来可能出现新异常的情况下表现较好
- 监督学习的目标是识别出已知的类别,适用于已经有较多的正例和负例的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号