逻辑回归
分类问题
假设预测的变量y是离散的值,需要使用逻辑回归(Logistic Regression,LR)的算法,实际上它是一种分类算法。
二元分类
二元分类问题是指y只有两个离散值的情况,例如:
- 垃圾邮件分类:y=1表示是垃圾邮件,y=0表示不是垃圾邮件
- 癌症检测:y=1表示患有癌症,y=0表示没有癌症
假说表示
对于二元分类问题,我们可以使用线性回归的假说表示:
\[h_\theta(x) = \theta^Tx
\]
但是,这样的假说表示有一个问题,就是\(h_\theta(x)\)的值可能大于1或者小于0,而我们需要的是0到1之间的值,因为我们的y只有0和1两个值。
为了解决上面的问题,我们需要一个函数,这个函数的值域是0到1之间的,这样我们就可以把\(h_\theta(x)\)的值限制在0到1之间,这个函数就是Sigmoid函数:
\[g(z) = \frac{1}{1+e^{-z}}
\]
Sigmoid函数的图像如下:
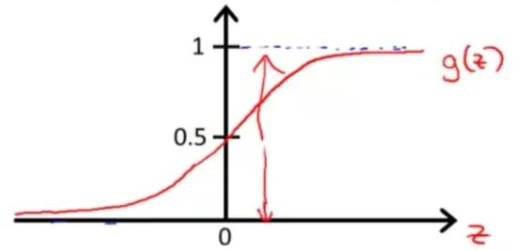
我们把\(h_\theta(x)\)代入Sigmoid函数,得到:
\[h_\theta(x) = g(\theta^Tx) = \frac{1}{1+e^{-\theta^Tx}}
\]
\(h_\theta(x)\)的值域是0到1之间的,把\(h_\theta(x)\)看成是一个概率值,例如\(h_\theta(x)=0.7\),表示有70%的概率是垃圾邮件,有30%的概率不是垃圾邮件。
决策边界
二元分类的决策边界

对于图中的二元分类问题,设
\[h_\theta(x) = g(\theta_0 + \theta_1x_1 + \theta_2x_2)
\]
当参数\(\theta\)取值为\([-3, 1, 1]\)时,决策边界为:
\[-3 + x_1 + x_2 = 0
\]
此时,决策边界是一条直线。
多元分类的决策边界
根据训练集的不同,决策边界可能是一条直线,也可能是一条曲线,例如:
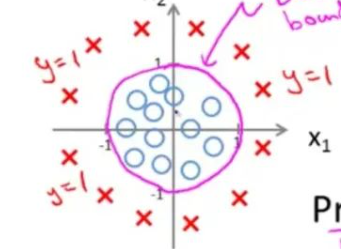
\(h_\theta(x)\)也可能是其他多项式函数。
代价函数
逻辑回归的参数
逻辑回归的参数是\(\theta\),我们需要找到最优的\(\theta\),使得\(h_\theta(x)\)尽可能的接近y。
代价函数的选择
如果我们使用线性回归的代价函数,即平方误差代价函数,得到的代价函数是非凸函数,这样的话,我们使用梯度下降法得到的结果可能是局部最优解,而不是全局最优解。
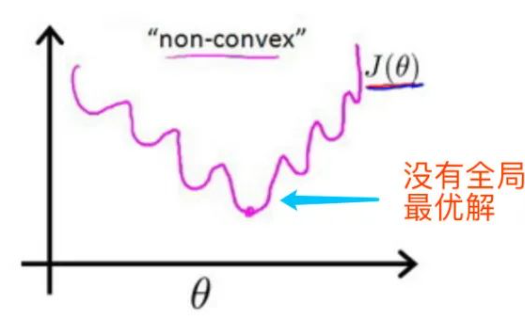
为了解决上面的问题,我们需要选择一个新的代价函数,使得代价函数是凸函数。
定义逻辑回归的代价函数为:
\[J(\theta) = \frac{1}{m}\sum_{i=1}^mCost(h_\theta(x^{(i)}), y^{(i)}) \\
\]
其中,对\(Cost\)函数的定义为:
\[Cost(h_\theta(x), y) = \begin{cases}
-log(h_\theta(x)) & \text{if } y=1 \\
-log(1-h_\theta(x)) & \text{if } y=0
\end{cases}
\]
或者合并写作
\[Cost(h_\theta(x), y) = -ylog(h_\theta(x)) - (1-y)log(1-h_\theta(x))
\]
在这个代价函数中,当y=1时,如果\(h_\theta(x)\)越接近1,\(Cost\)函数的值越小;当y=0时,如果\(h_\theta(x)\)越接近0,\(Cost\)函数的值越小。
梯度下降法
代价函数合并写作:
\[J(\theta)=-\frac{1}{m}\sum_{i=1}^m[y^{(i)}log(h_\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)}))]
\]
为使用梯度下降法,我们需要求出代价函数的偏导数:推导过程如下:
\[\begin{aligned}
\frac{\partial J(\theta)}{\partial \theta_j} &= -\frac{1}{m}\sum_{i=1}^m[y^{(i)}\frac{1}{h_\theta(x^{(i)})}\frac{\partial h_\theta(x^{(i)})}{\partial \theta_j} + (1-y^{(i)})\frac{1}{1-h_\theta(x^{(i)})}\frac{\partial h_\theta(x^{(i)})}{\partial \theta_j}] \\
&= -\frac{1}{m}\sum_{i=1}^m[y^{(i)}\frac{1}{h_\theta(x^{(i)})} - (1-y^{(i)})\frac{1}{1-h_\theta(x^{(i)})}]\frac{\partial h_\theta(x^{(i)})}{\partial \theta_j} \\
&= -\frac{1}{m}\sum_{i=1}^m[y^{(i)}\frac{1}{h_\theta(x^{(i)})} - (1-y^{(i)})\frac{1}{1-h_\theta(x^{(i)})}]h_\theta(x^{(i)})(1-h_\theta(x^{(i)}))\frac{\partial \theta^Tx^{(i)}}{\partial \theta_j} \\
&= -\frac{1}{m}\sum_{i=1}^m[y^{(i)}(1-h_\theta(x^{(i)})) - (1-y^{(i)})h_\theta(x^{(i)})]x_j^{(i)} \\
&= -\frac{1}{m}\sum_{i=1}^m[y^{(i)} - y^{(i)}h_\theta(x^{(i)}) - h_\theta(x^{(i)}) + y^{(i)}h_\theta(x^{(i)})]x_j^{(i)} \\
&= -\frac{1}{m}\sum_{i=1}^m[y^{(i)} - h_\theta(x^{(i)})]x_j^{(i)} \\
&= \frac{1}{m}\sum_{i=1}^m[h_\theta(x^{(i)}) - y^{(i)}]x_j^{(i)}
\end{aligned}
\]
不断迭代,直到收敛,得到最优的\(\theta\)。
\[\theta_j := \theta_j - \alpha\frac{\partial J(\theta)}{\partial \theta_j}
\]
正则化问题
过拟合
过拟合是指模型在训练集上表现良好,但是在测试集上表现不好的情况。以线性回归为例,如果我们使用高阶多项式函数来拟合数据,就会出现过拟合的情况。
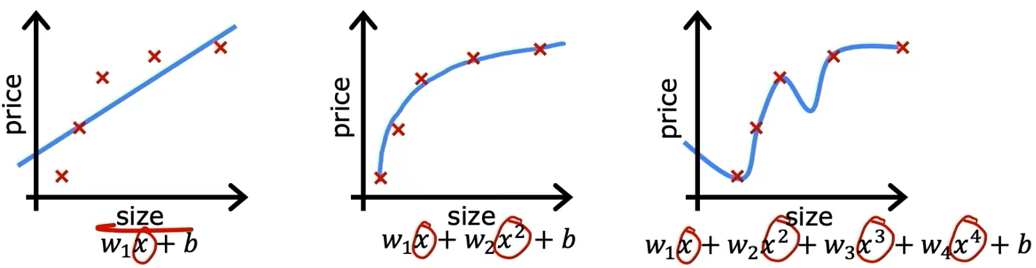
在多项式拟合中,\(x\)的次数越高,拟合效果越好,但是相应的预测能力就可能变差。
解决过拟合的方法
解决过拟合的方法有:
正则化
正则化是解决过拟合的一种方法,减少特征的数量防止过拟合的方法是一种特殊的正则化。即将对应参数的值设为0;
正则化是指在代价函数中增加一项,使得参数\(\theta\)的值尽量小,当参数降低到一定程度时,可以视为这个参数对结果的影响可以忽略不计,这样就可以减少特征的数量,防止过拟合。
代价函数
为了防止参数\(\theta\)的值过大,我们需要对代价函数进行修改,对参数添加一个很大的倍数,当参数变大后,代价函数会随之变大,这样就可以防止参数过大。
代价函数的正则化形式为:
\[J(\theta) = \frac{1}{2m}[\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})^2 + \lambda\sum_{j=1}^n\theta_j^2]
\]
其中,\(\lambda\)是正则化参数,用来控制正则化的程度,\(\lambda\)越大,正则化的程度越大。
\(\lambda\)的选择
\(\lambda\)的选择需要根据实际情况来确定,一般来说,我们可以从一个较小的值开始,然后不断增大\(\lambda\),直到达到我们的要求。
- 如果\(\lambda\)太大,会导致模型欠拟合,因为模型的参数都很小,不能很好的拟合数据。
- 如果\(\lambda\)太小,会导致模型过拟合,因为模型的参数都很大,会导致模型过于复杂,不能很好的拟合数据。
梯度下降法
线性回归的梯度下降法带入新的代价函数,得到:
\[\theta_j := \theta_j - \alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\lambda}{m}\theta_j]
\]
逻辑回归的梯度下降法带入新的代价函数,得到:
\[\theta_j := \theta_j - \alpha[\frac{1}{m}\sum_{i=1}^m(h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} + \frac{\lambda}{m}\theta_j]
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号