
数据库系统知识点总结
一、数据库概论
1. 数据库阶段的数据管理特点
- 采用数据模型(数据本身的特征和数据直接的联系)表示复杂的数据结构
- 有较高的数据独立性
- 为用户提供了方便的接口
- 提供数据控制功能
- 数据库的恢复
- 数据库的并发控制
- 数据库的完整性
- 数据安全性
- 增加了系统的灵活性
2. 数据库概念
- 数据库(DB):相关数据集合
- 数据库管理系统(DBMS) 用户与操作系统直接的数据管理软件
- 数据库系统(DBS) 采用数据库技术的计算机系统
- 数据库技术 研究数据库结构、存储、设计、管理、使用
3. 数据模型
- 概念模型 表达用户观点需求
- 现在采用的概念模型主要是E-R模型
- 逻辑模型 表达计算机实现的全局逻辑结构
- 层次模型
- 网状模型
- 关系模型
- 对象模型
- 外部模型 表达用户使用观点
- 视图
- 内部模型 表达物理结构

4. 三层模式和两层映像
1.三次模式
- 外模式
- 用户和数据库系统的结构
- 逻辑模式
- 数据库中全部数据的整体逻辑结构
- 内模式
- 数据库在物理存储方面的描述
2.两层映像
- 外模式/逻辑模式映像
- 逻辑模式/内模式映像

二、关系模型
1. 基本术语
-
表
术语 理解 元组 行 属性 列 元数 属性的个数/列数 基数 元组的个数/行数 -
超键、候选键、主键
- 超键(super key):在关系中能唯一标识元组的属性集称为关系模式的超键
- 候选键(candidate key):不含有多余属性的超键称为候选键
- 主键(primary key):用户选作元组标识的一个候选键程序主键
考虑以下属性:
身份证 姓名 性别 年龄
身份证唯一,所以是一个超键
姓名唯一,所以是一个超键
(姓名,性别)唯一,所以是一个超键
(姓名,性别,年龄)唯一,所以是一个超键身份证唯一,而且没有多余属性,所以是一个候选键
姓名唯一,而且没有多余属性,所以是一个候选键
候选键是没有多余属性的超键考虑输入查询方便性,可以选择 身份证 为主键
也可以 考虑习惯 选择 姓名 为主键
主键是选中的一个候选键
2. 完整性规则
- 实体完整性规则
- 组成主键的属性上不能有空值
- 参照完整性规则
- 不允许引用不存在的实体
- 用户定义完整性规则
- 用户定义具体的数据约束
如:年龄限制在15~30之间
3.关系模型的3层体系结构
- 关系模式
- 关系模式的定义包括:模式名、属性名、值域名以及模式的主键,不含物理存储方面的描述
- 子模式
- 用户所用到的数据的描述
- 存储模式
三、关系运算
1. 关系代数
对于以下两个关系:
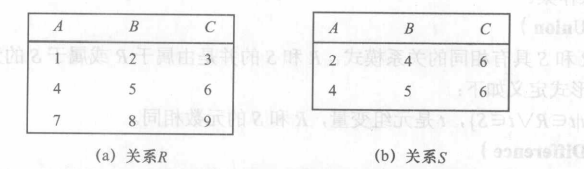
进行以下5个基本操作:
-
并(Union)
- 合并两个关系
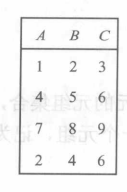
- 合并两个关系
-
差(Difference)
- 取两个关系的差集
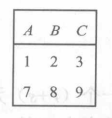
- 取两个关系的差集
-
笛卡尔积(Cartesian Product)
- 每个元组的前 r个分量(属性值)来自 R 的一个元组,后 s 个分量来自 S的一个元组,记为R×S
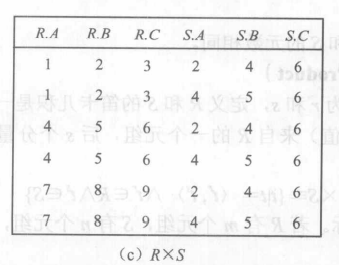
- 每个元组的前 r个分量(属性值)来自 R 的一个元组,后 s 个分量来自 S的一个元组,记为R×S
-
投影(Projection)
- 只保留关系 R 的一些属性,并修改顺序,记为πR
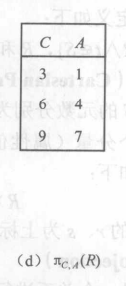
- 只保留关系 R 的一些属性,并修改顺序,记为πR
-
选择(Selection)
- 根据条件做水平切割,保留符合条件的元组,记为σR

- 根据条件做水平切割,保留符合条件的元组,记为σR
进行以下4个组合操作:
- 交(Intersection)
- 取两个关系的交集
- 连接(Join)
- 笛卡尔积后选择部分属性
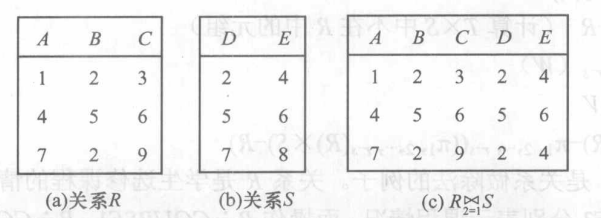
- 笛卡尔积后选择部分属性
- 自然连接(Natural Join)
- 取两个关系的笛卡儿积,并且投影公共属性相同两个关系的所有属性
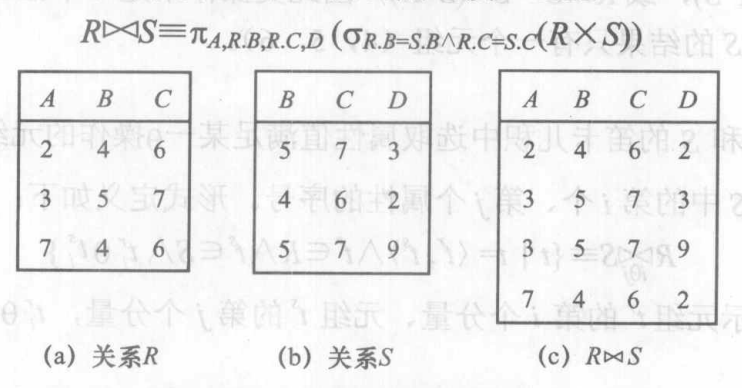
- 取两个关系的笛卡儿积,并且投影公共属性相同两个关系的所有属性
- 除法(Division)
- 在R和S的联系RS中,找出与S中所有的元组有关系的R元组
如:在以下表中找出选修所有课程的学生
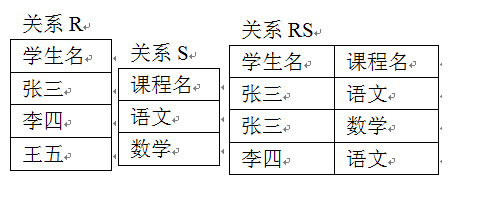
使用R÷S可以得到(张三)
四、关系数据库语言SQL
1. SQL的组成
- 数据定义语言
- 数据操作语言
- 嵌入式SQL语言的使用规定
- 数据控制语言
2. SQL的数据定义
SQL模式
一个数据库可以建立多个模式,一个模式通常包括多个表、视图、索引等数据库对象。创建了一个模式就建立了一个数据库的命名空间,一个框架
- SQL模式的创建
create schema schema_name authorization user_name; - SQL模式的删除
drop schema schema_name [CASCADE | RESTRICT];- CASCADE:删除模式时,删除模式下的所有表和视图
- RESTRICT:删除模式时,删除模式下的所有表和视图,但是不允许删除模式下的表和视图
基本数据类型
- 数值型
- 长整数:Integer
- 短整数:Smallint
- 浮点数:Real
- 浮点数(确定位数):Float(n)
- 双精度浮点数:Double(n)
- 定点数:Numberic(n,m)
- 字符串型
- 字符串:Char(n)
- 字符串:Varchar(n)
- 位串型
- 位串:Bit(n)
- 变长位串:Bit Varbit(n)
- 日期型
- 日期:Date
- 时间:Time
基本表的创建、修改和撤销
- 创建表
create table table_name ( <列表类型>, ... <完整性约束>, ... ); - 修改表
alter table table_name add column column_name data_type;alter table table_name drop column column_name;alter table table_name alter column column_name data_type; - 撤销表
drop table table_name[CASCADE | RESTRICT];
索引
索引是一种结构化的数据结构,用于快速定位数据行,以提高数据库的查询效率。
- 创建索引
create index index_name on table_name (column_name); - 修改索引
alter index index_name on table_name (column_name); - 撤销索引
drop index index_name on table_name;
视图
视图是一种特殊的表,它可以提供一个视图的查询结果,而不是一个完整的表。
视图的定义存放在数据字典中,并不存储视图对应的数据,因此称为"虚表"。
- 创建视图
create view view_name as select * from table_name; - 修改视图
alter view view_name as select * from table_name; - 撤销视图
drop view view_name;
3. SQL的数据查询
查询语句
- select
select [distinct | all] select_list from table_name [where condition] [group by column_name] [order by column_name] [limit number];- distinct:只查询不同的数据
all:查询所有数据,默认 - select_list:查询的列
- 可以是多个列,用逗号分隔
- 可以是*,表示查询所有列
- 允许使用表达式:+、-、*、/以及列名、常数的算数表达式
- table_name:查询的表
- 可以是多个表,用逗号分隔
- 可以使用as进行改名
- 可以进行连接操作,用于查询多个表的数据,运算符为:union、union all、except、except all、intersect、intersect all
- condition:查询条件
查询条件的组成
- 比较表达式:=、<>、>、<、>=、<=
- 逻辑表达式:and、or、not
- 谓词:exists、in、between、like、is null、is not null
- 聚合函数:count、sum、avg、min、max、distinct
- 子查询:(select ...)
- group:分组
分组的组成
- 分组的列
- 分组的条件 having
- order:排序
排序的组成
- 排序列:column_name
- 排序方式:asc、desc
- limit:分页限制
分页限制的组成
- 分页限制的数量
- 分页限制的起始位置
- distinct:只查询不同的数据
表达式中的比较操作
- 比较表达式
column_name = value column_name <> value column_name > value column_name < value column_name >= value column_name <= value - 谓词表达式
exists (select ...) not exists (select ...) in (value1, value2, ...) not in (value1, value2, ...) between value1 and value2 not between value1 and value2 like '%value%' not like '%value%' is null is not null
嵌套查询
- 导出表
在From中使用子查询,给子查询的结果起表名和列名
select * from (select ...) as table_name - With字句
使用With子句定义一个临时视图,置于Select之前
with table_name as (select ...) select ... - 基本表的连接
- 连接类型
- inner join:内连接
- left join:左连接
- right join:右连接
- full join:全连接
- 连接条件
- on:连接条件
- using:连接条件
- natural:自然连接
- 连接类型
4. SQL的数据更新
数据插入
- 插入语句
insert into table_name (column_name1, column_name2, ...) values (value1, value2, ...) - 插入多行数据
insert into table_name (column_name1, column_name2, ...) values (value1, value2, ...), (value1, value2, ...), (value1, value2, ...) - 插入多个表
insert into table_name1 (column_name1, column_name2, ...) values (value1, value2, ...), (value1, value2, ...), (value1, value2, ...) - 插入多个表,并且插入多行数据
insert into table_name1 (column_name1, column_name2, ...) values (value1, value2, ...), (value1, value2, ...), (value1, value2, ...) - 插入多个表,并且插入多行数据
insert into table_name1 (column_name1, column_name2, ...) values (value1, value2, ...), (value1, value2, ...), (value1, value2, ...) - 插入多个表,并且插入多行数据
insert into table_name1 (column_name1, column_name2, ...) values (value1, value2, ...), (value1, value2, ...), (value1, value2, ...) ```
数据删除
- 删除语句
delete from table_name where condition
数据修改
- 修改语句
update table_name set column_name1 = value1, column_name2 = value2, ... where condition
五、关系数据库的规范化设计
1. 关系模式的外延和内涵
- 外延:通常说的关系、表、当前值;外延与时间有关,随着时间的推移在不断变化
- 内涵(关系模式):对数据的定义和数据完整性的定义,时间独立。对数据完整性的定义包括:
- 静态约束
涉及数据之间的联系、主键、值域的设计
- 动态约束
定义各种操作对关系值的影响
2. 函数依赖
函数依赖
函数依赖(Functional Dependency,FD):属性值之间会发生联系,这种联系称为函数依赖。
- 定义:设有关系模式\(R(U)\),\(X\)和\(Y\)是属性集
U的子集,函数依赖是形为\(X→Y\)的一个命题,只要\(r\)是\(R\)的当前关系,对\(r\)中任意两个元组\(t\)和\(s\),都有\(t[X]=s[X]\)蕴涵\(t[Y] =s[Y]\),那么称\(FD X→Y\)在关系模式\(R(U)\)中成立。 - 理解:若有\(FD X→Y\)成立,则有两元组\(X\)属性值相同,\(Y\)属性值也相同。
如下图:

\(A→B\)在关系1中成立,在关系2中不成立。 - 图形化表示:每个函数依赖用一个箭头表示,箭尾表示函数依赖左边的属性,箭头处表示函数依赖右边的属性。

FD的逻辑蕴含
- \(F\)是关系模式\(R\)上成立的函数依赖集合,\(X→Y\)是一个函数依赖。若对\(R\)上每个满足\(F\)的关系\(r\)也满足\(X→Y\),则称\(F\)逻辑蕴含\(X→Y\),记为 \(F \vDash X→Y\)
- 被\(F\)逻辑蕴含的函数依赖全体构成的集合,称为函数依赖\(F\)的闭包(Closure),记为\(F^+\)
FD的推理规则
- 自反性:若\(Y \subseteq X\subseteq U\),则\(X→Y\)在\(R\)上成立。
- 增广性:若\(X→Y\)在\(R\)上成立,且\(Z \subseteq U\) 则\(XZ→YZ\)在\(R\)上成立。
- 传递性:若\(X→Y\)和\(Y→Z\)在\(R\)上成立,则\(X→Z\)在\(R\)上成立。
- 合并性:\(\{X→Y,X→Z\}\vDash X→YZ\)
- 分解性:\(\{X→Y,Z\subseteq Y\}\vDash X→Z\)
- 伪传递性 :\(\{X→Y,WY→Z\}\vDash WX→Z\)
- 复合性:\(\{X→Y,W→Z\}\vDash XW→YZ\)
- \(\{X→Y,W→Z\}\vDash X \cup(W-Y)→YZ\)
FD和关键码的关系
设关系模式\(R\)的属性集是\(U\),\(X\)是\(U\)的一个子集。如果\(X→U\)在\(R\)上成立,那么称\(X\)是\(R\)的一个超键。如果\(X→U\)在\(R\)上成立,但对于\(X\)的任一真子集\(X\)都有\(X→U\)不成立,那么称\(X\)是\(R\)上的一个候选键。
3. 关系模式的范式
模式的范式(Normal Form,NF) 是衡量关系模式好坏的标准。
第一范式
如果关系模式\(R\)的每个关系\(r\)的属性值都是不可分的原子值,那么称R是第一范式(First Normal Form,1NF) 的模式。
例如关系模式R(NAME,ADDRESS,PHONE),如果一个人有两个电话号码(PHONE),那么在关系中至少要出现两个元组,以便存储这两个号码。
第二范式
满足第一范式的条件下,每个非主属性完全函数依赖于候选键,那么称\(R\)是第二范式(Second Normal Form,2NF)的模式。
局部依赖:通过AB能得出C,通过A也能得出C,通过B也能得出C,那么说C部分依赖于AB。
完全依赖::通过AB能得出C,但是AB单独得不出C,那么说C完全依赖于AB.
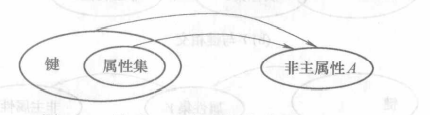
简而言之,不需要全部的候选键,就能确定一个非主属性,这种模式即违反了第二范式。
例如:(身份证号,学号)→(姓名),(学号)→(姓名),姓名部分依赖于主属性,这样的模式即违反了第二范式。
只有一个主属性的表若符合1NF,必然符合2NF。
第三范式
满足第一范式的条件下,每个非主属性都不传递依赖(只能完全依赖)于\(R\)的候选键,那么称R是第三范式(3NF) 的模式。
传递依赖:通过A得到B,通过B得到C,但是C得不到B,B得不到A,那么成C传递依赖于A
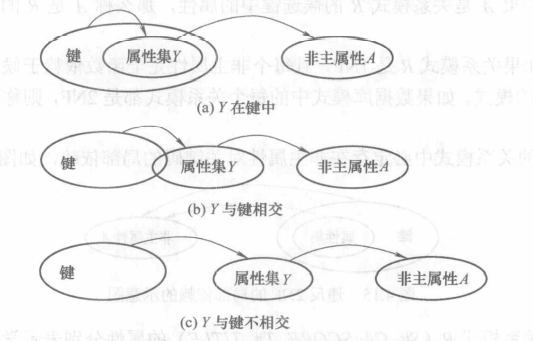
简而言之,第三范式就是属性不依赖于其它非主属性。
例如:(身份证号)→(学号),(学号)→(姓名),姓名传递依赖于主属性身份证号,那么这样的模式即违反了第三范式。
BCNF
满足第一范式的条件下,且每个属性都不传递依赖于\(R\)的候选键,那么称\(R\)是BCNF的模式。
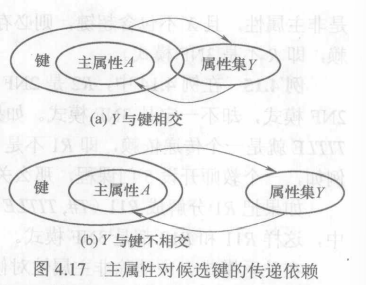
也就是说在第三范式的基础上去除主属性对候选键的部分或传递依赖。
换句话说就是不能选择超键做主键。
4. 关系模式的分解
五、数据库设计与E-R模型
1.数据库设计过程
数据库应用系统是生存周期可以划分为以下7个阶段:
- 规划
- 需求分析
- 概念设计
- 逻辑设计
- 物理设计
- 实现
- 运行维护
规划阶段
- 系统调查
- 可行性分析
- 制定开发计划
需求分析阶段
- 分析用户活动,产生业务流程图
- 确定系统范围,产生系统关联图
- 分析用户活动涉及的数据,产生数据流图(Data Flow Diagram,DFD)
- 分析系统数据,产生数据字典
概念设计阶段
产生反应用户单位信息需求的数据库概念结构,即概念模型(可以采用E-R图)。
逻辑设计阶段
- 分析数据库概念结构,产生逻辑模型
- 设计外模型
外模型是逻辑模型的逻辑子集。外模型是应用程序和数据库系统的接口,它能允许应用程序有效地访问数据库中的数据,而不破坏数据库的安全性。
- 设计应用程序与数据库的接口
- 评价模型
- 修正模型
物理设计阶段
- 存储记录结构设计
- 确定数据存放位置
- 存取方法的设计
- 完整性和安全性考虑
- 程序设计
数据库实现
数据库运行和维护
2. ER模型
ER模型是一种简单的数据库模型,它是一个实体与实体之间的关系,实体与属性之间的关系,实体与关系之间的关系。
基本元素
- 实体
- 实体:实体是数据库中的数据对象
- 实体集:实体集是实体的集合
- 实体类型:对实体集中实体定义
- 联系(关系)
- 关系:关系是实体之间的联系
- 关系集:关系集是实体之间的联系的集合
- 关系类型:对关系集中关系定义
- 属性:属性是实体的某一特征
属性
- 简单属性和复合属性
- 简单属性:简单属性是一个值,它是实体的一个特
- 复合属性:可分解为多个简单属性的属性(嵌套属性)
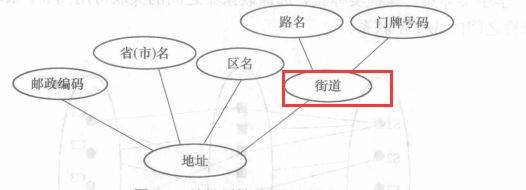
- 单值属性和多值属性
- 单值属性:同一实体的属性只能有一个值
- 多值属性:同一实体的属性可以有多个值
不符合1NF,可以
- 多值属性拆分为多个单值属性
- 多值属性用一个独立实体表示
- 存储属性和派生属性
有时候,两个(或两个以上)属性值是相关的。此时可从其他属性值推导出值的属性,称为派生属性(Derived Attribute)。派生属性的值不必存储在数据库内,而其他需要存储值的属性称为存储属性(Stored Attribute)。 - 允许为空的属性
联系
- 联系的元数
一个联系涉及的实体集的个数,称为联系的元数(度数)。 - 联系类型的约束
- 基数约束
对于二元联系,可能的映射基数有:1:1,1:N,M:N。 - 参与约束
如果实体集E中的每个实体都参与联系集R的至少一个联系中,称实体集E“完全参与”联系集R。
如果实体集E中只有部分实体参与联系集R的联系中,称实体集E“部分参与”联系集R。
在ER图中表示时,完全参与用双线边表示,部分参与用单线边表示。
- 基数约束
六、系统实现技术
1. 事务
事务是构成单一逻辑工作单元的操作集合,要么完整的执行,要么不执行。
事务含有ACID性质
- 原子性(Atomicity):事务中的操作是原子性的,即事务中的操作是不会被中断的。
- 一致性(Consistency):事务中的操作是一致性的,即数据不会因事务的执行遭到破坏。
- 隔离性(Isolation):事务中的操作是隔离性的,即多个事务并发时,与这些事务单独执行的结果一致。
- 持久性(Durability):事务中的操作是持久性的,即事务中的操作永久地反映在数据库中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号