
Flink WordCount Job Submit
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/15127770.html
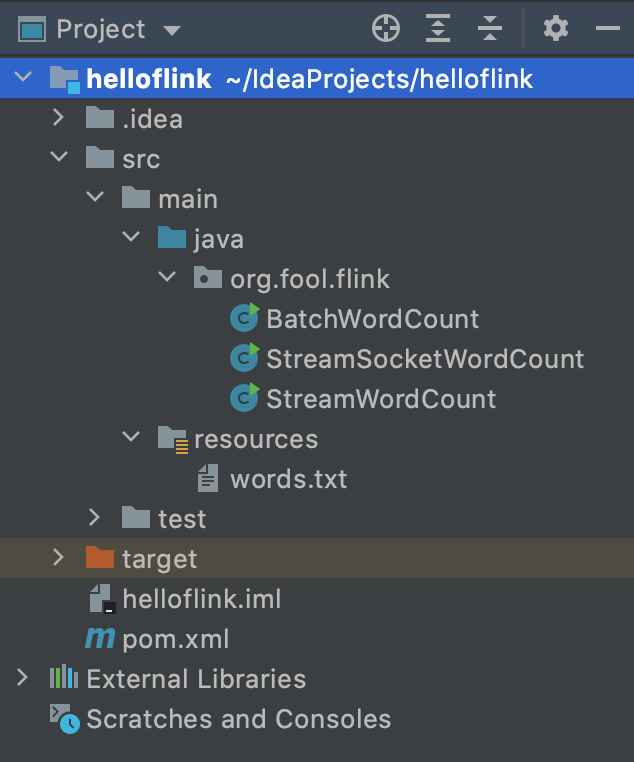
Project Directory
Maven Dependency
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.fool</groupId> <artifactId>flink</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.12.5</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.12.5</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.12</artifactId> <version>1.12.5</version> </dependency> </dependencies> </project>
words.txt
hello world
hello spark
hello fink
hello hadoop
hello es
hello java
批处理
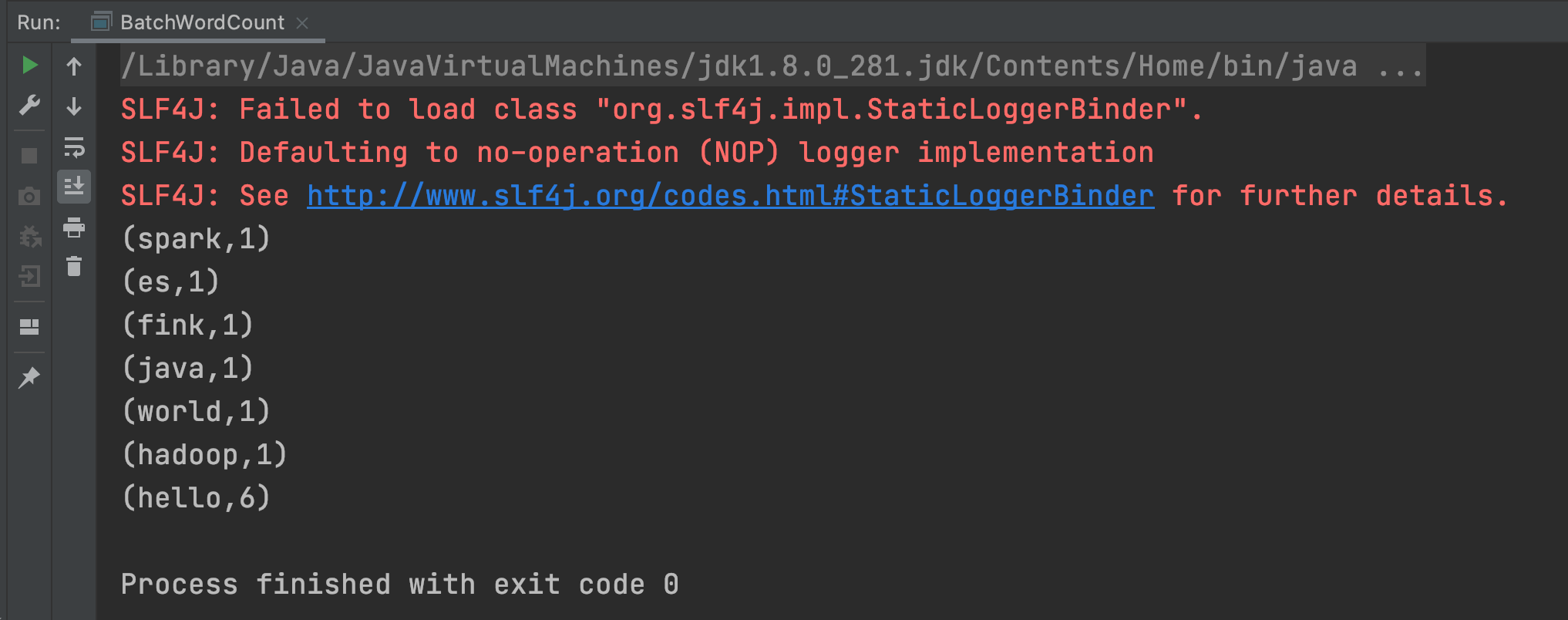
BatchWordCount.java
package org.fool.flink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; import java.util.Objects; public class BatchWordCount { public static void main(String[] args) throws Exception { ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment(); String inputPath = Objects.requireNonNull(ClassLoader.getSystemClassLoader().getResource("words.txt")).getPath(); DataSet<String> inputDataSet = environment.readTextFile(inputPath); DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] words = value.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } } }).groupBy(0).sum(1); resultSet.print(); } }
Run
流处理
使用有界数据来进行流处理
StreamWordCount.java
package org.fool.flink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Objects; public class StreamWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(4); String inputPath = Objects.requireNonNull(ClassLoader.getSystemClassLoader().getResource("words.txt")).getPath(); DataStream<String> inputDataStream = environment.readTextFile(inputPath); DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] words = value.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } } }).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() { @Override public Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception { return stringIntegerTuple2.getField(0); } }).sum(1); resultStream.print(); environment.execute(); } }
Note: 程序中设置了并行度为4,Flink 的每个算子都是可以设置并行度的。
Run
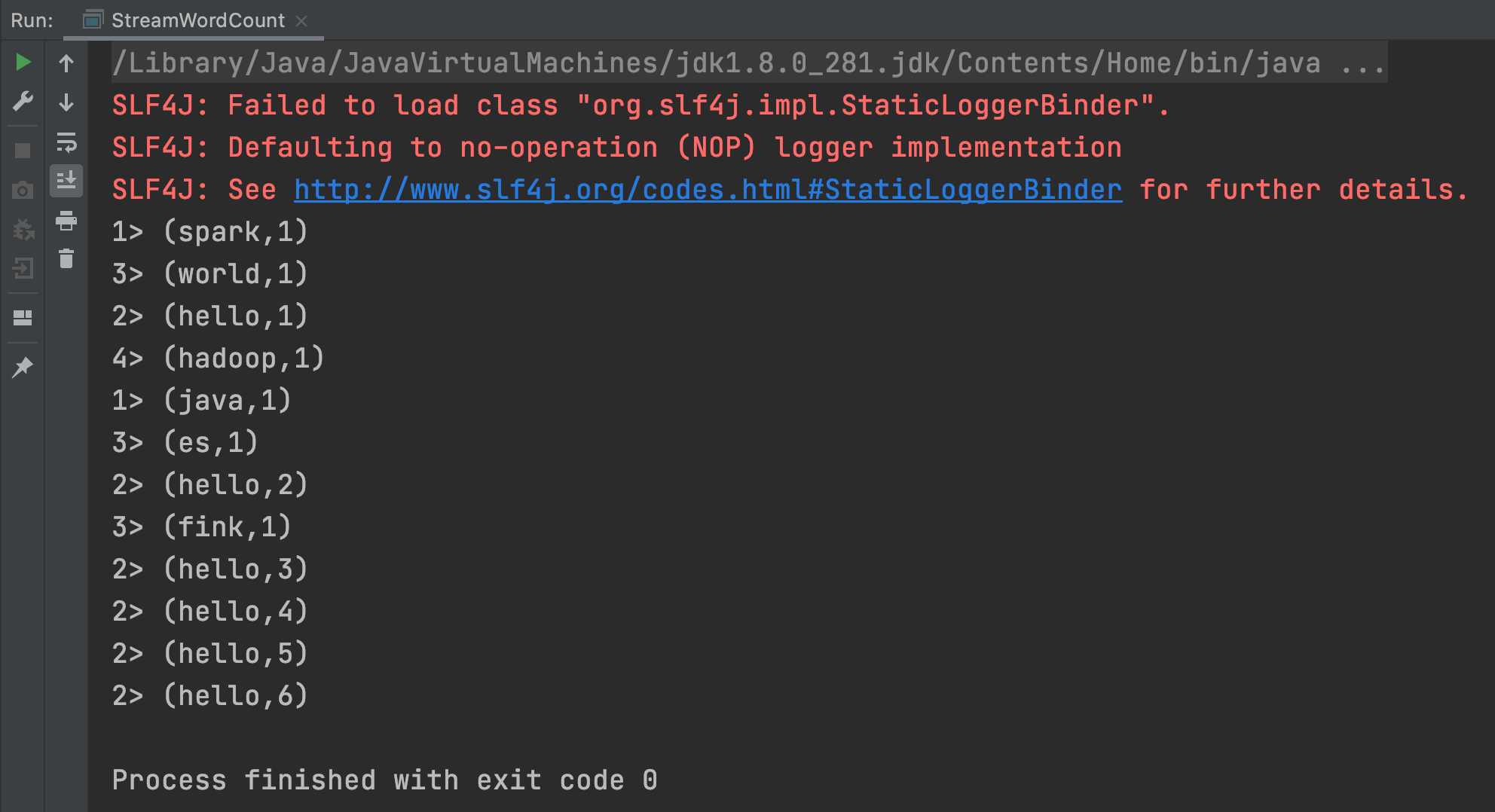
Note:> 左边的 数字 是计算处理的线程号
使用无界数据来进行流处理
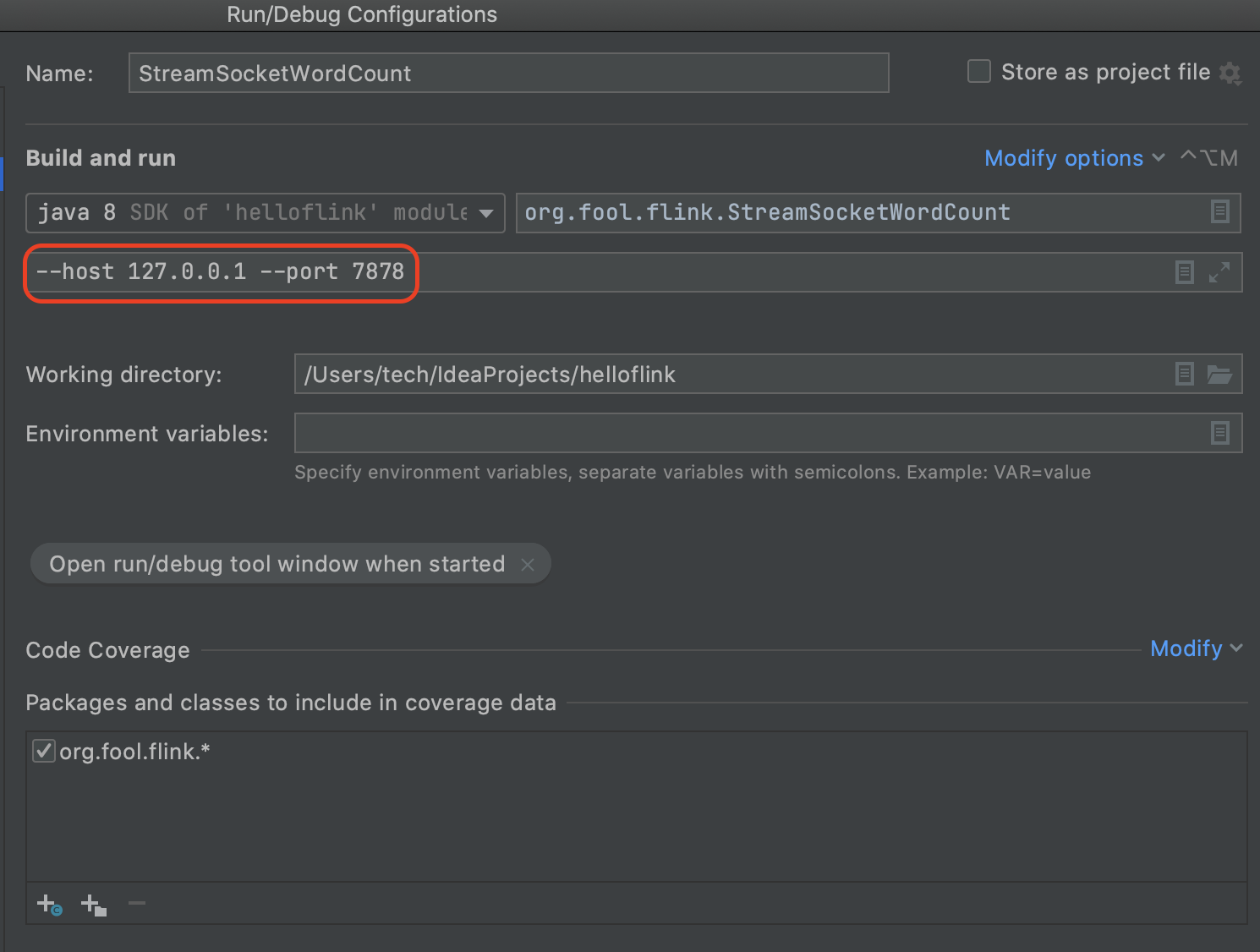
StreamSocketWordCount.java
package org.fool.flink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; public class StreamSocketWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(4); ParameterTool parameterTool = ParameterTool.fromArgs(args); String host = parameterTool.get("host"); int port = parameterTool.getInt("port"); DataStream<String> inputDataStream = environment.socketTextStream(host, port); DataStream<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] words = value.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } } }).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() { @Override public Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception { return stringIntegerTuple2.getField(0); } }).sum(1); resultStream.print(); environment.execute(); } }
Run
使用 nc 开启一个 socket
nc -lk 7878

查看控制台输出
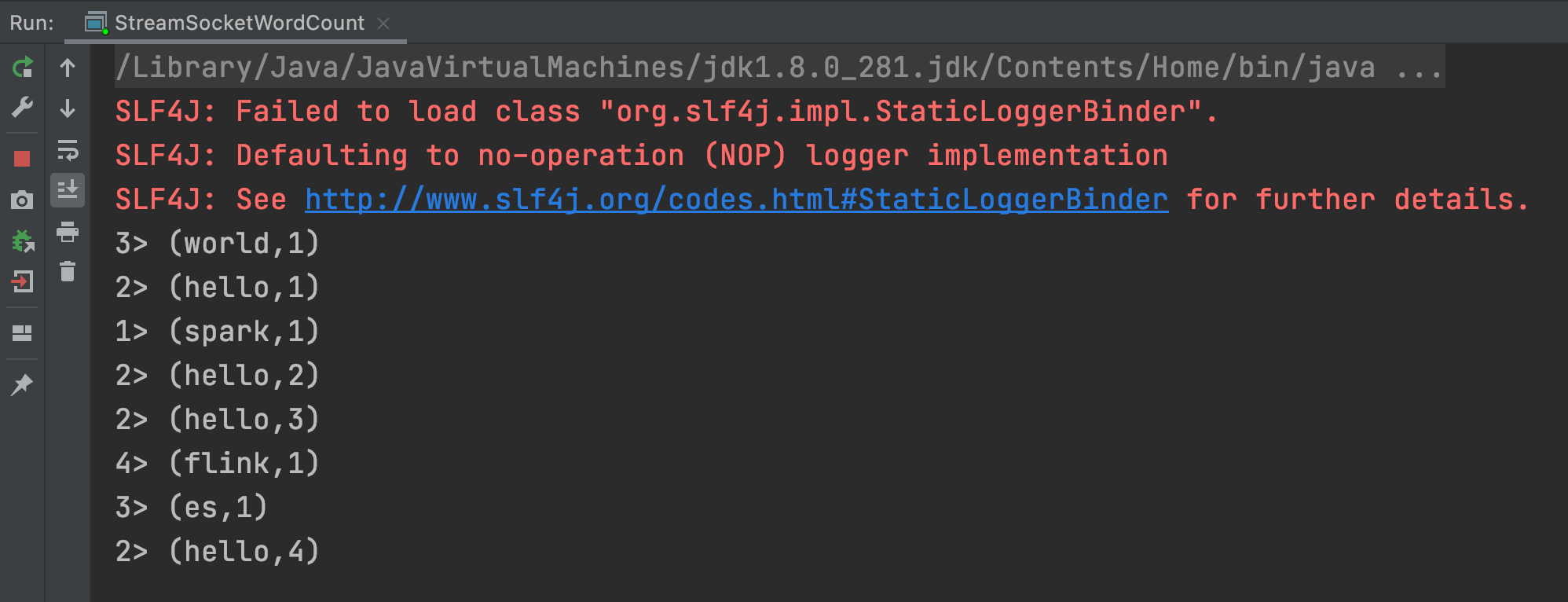
Job 提交运行
使用 UI 提交
停止 IDEA 中的 StreamSocketWordCount 程序,注释掉
// environment.setParallelism(4);
项目根目录下打包
mvn clean package
启动 Flink Cluster
./start-cluster.sh
使用 nc 开启一个 socket
nc -lk 7878

将打包好的 flink-1.0-SNAPSHOT.jar 提交到 Flink Cluster 中
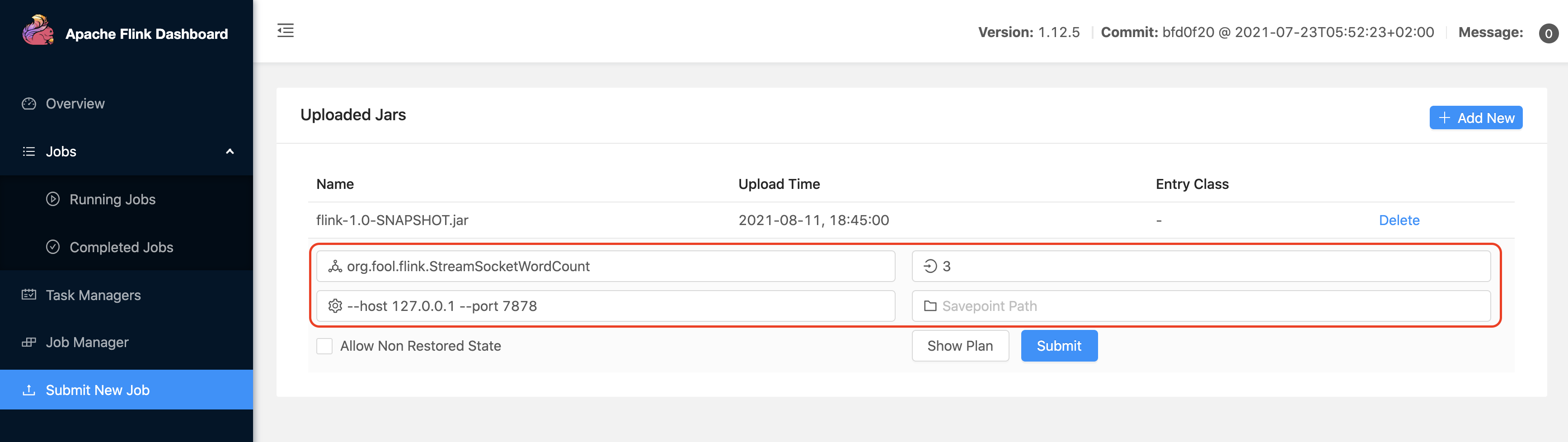
设置 并行度为 3,点击 Show Plan
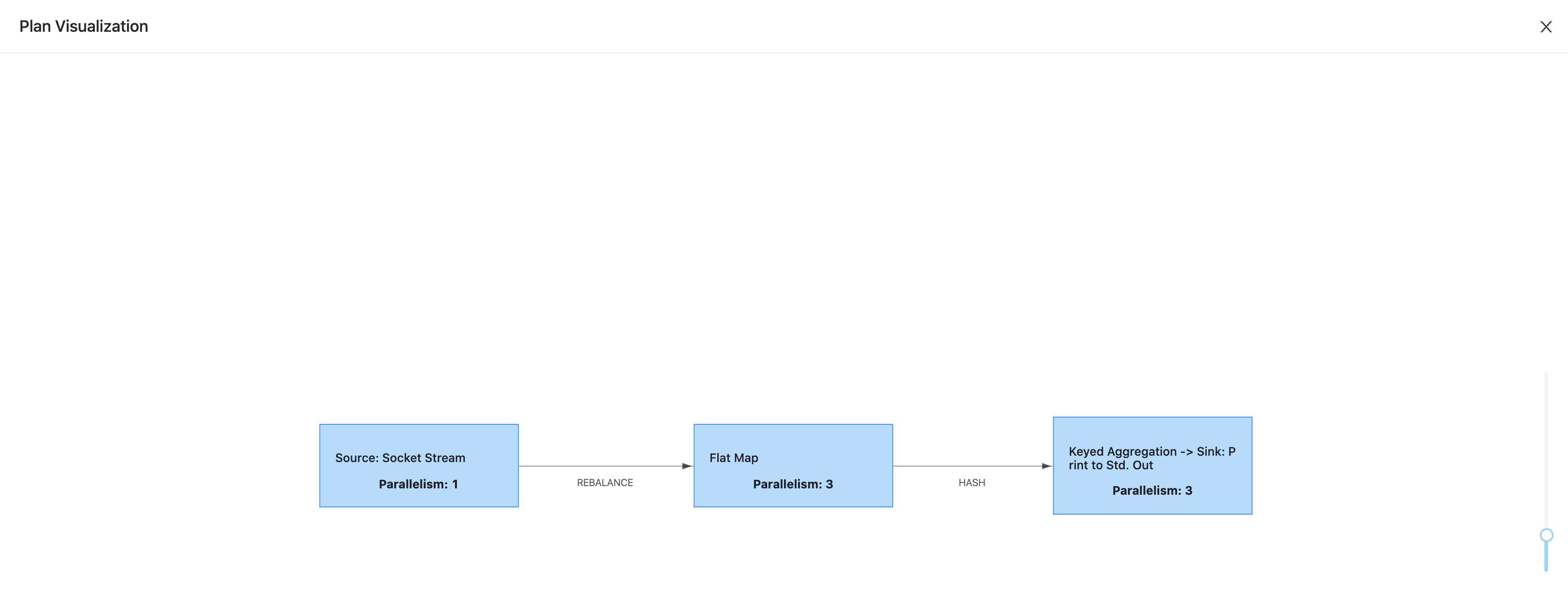
关闭后,点击 Submit
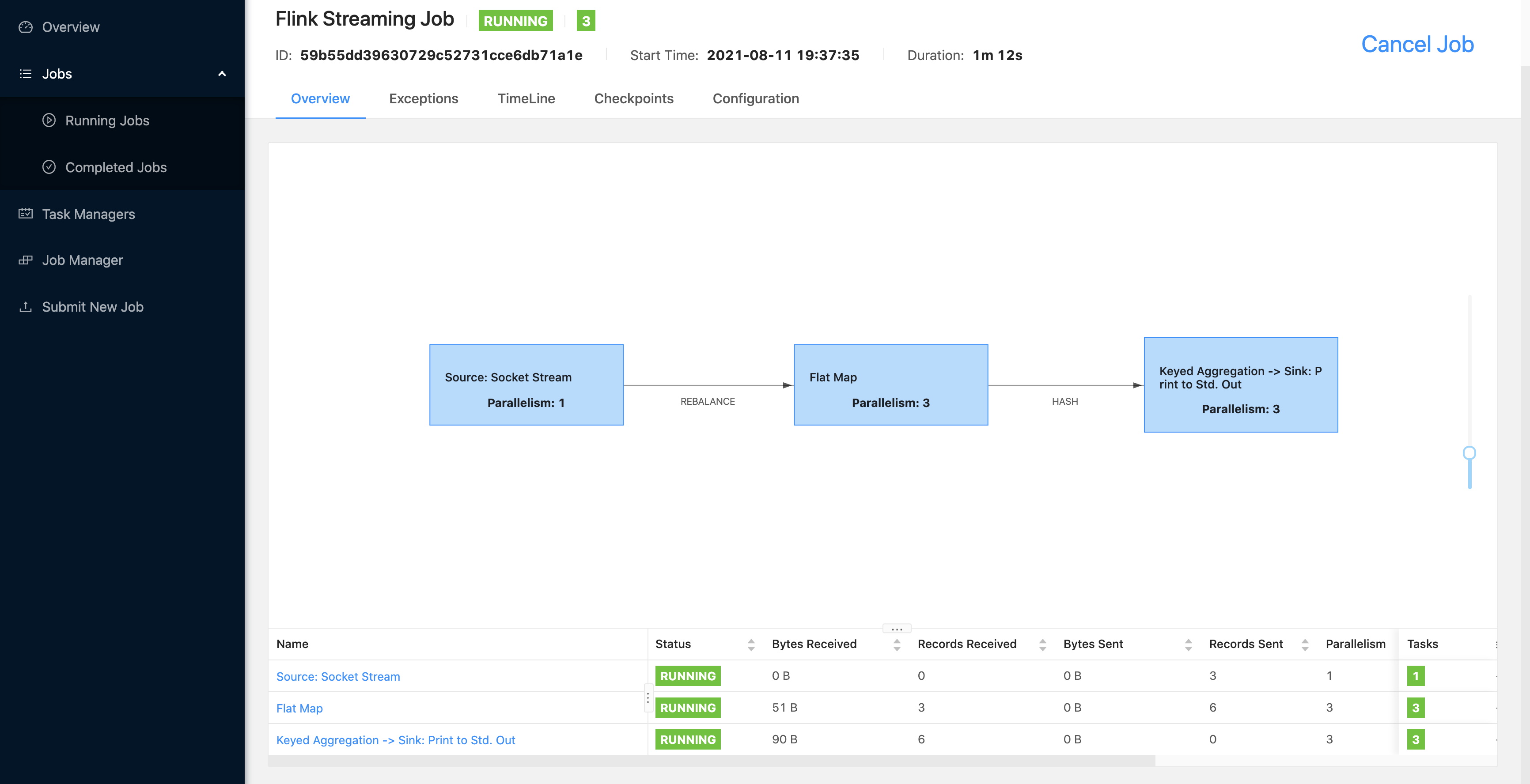
查看 Stdout
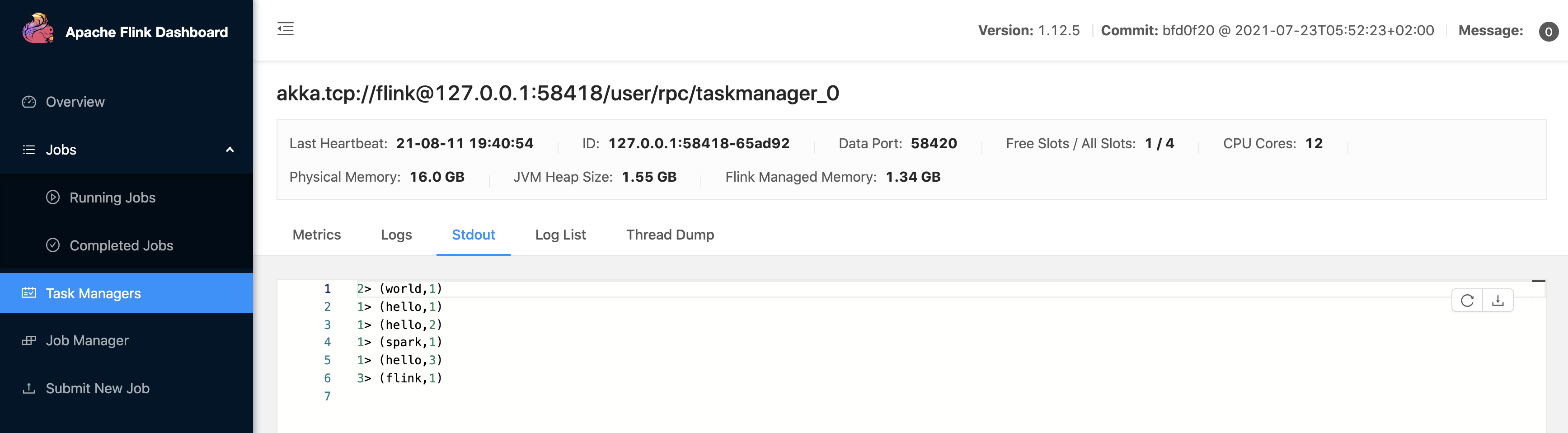
使用 命令行 提交
cd 到 flink 的 bin 目录
cd ~/app/flink-1.12.5/bin

flink run job
flink run -c org.fool.flink.StreamSocketWordCount -p 3 ~/IdeaProjects/helloflink/target/flink-1.0-SNAPSHOT.jar --host 127.0.0.1 -port 7878

flink list job
flink list

flink cancel job
flink cancel 8ba760464860d28fe4e30109a721be93

flink list
flink list -a

Note: 可以看到 使用 命令行提交 job 比操作 UI 提交更高效和方便。
欢迎点赞关注和收藏

强者自救 圣者渡人

