
Spark Streaming Demo
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/14701977.html
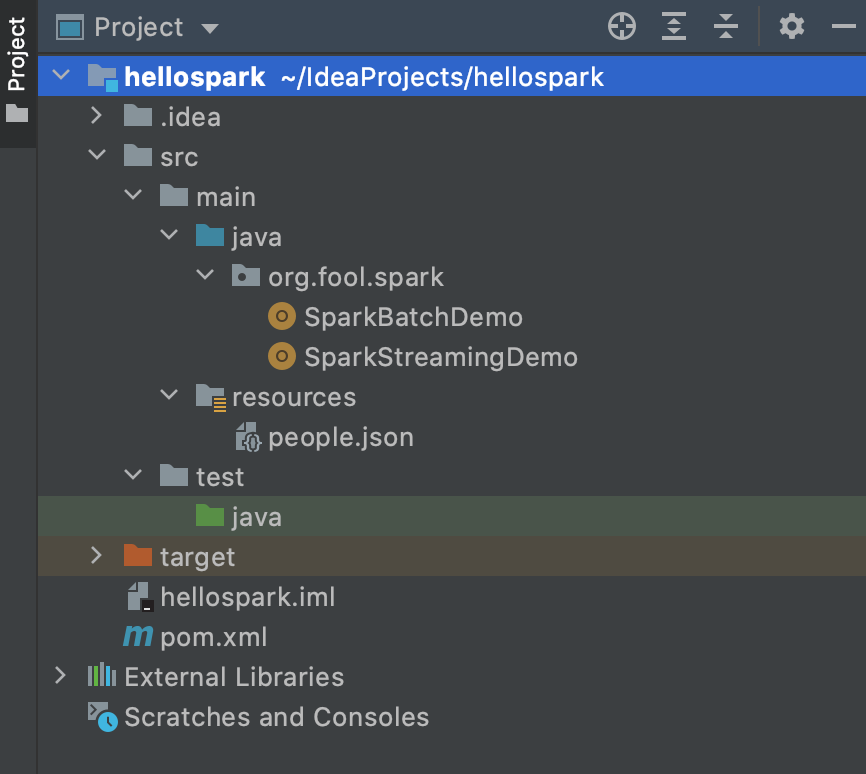
Project Directory
Maven Dependency
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.fool</groupId> <artifactId>hellospark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.1.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.1.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.1.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>3.1.1</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> </plugin> </plugins> </pluginManagement> </build> </project>
Kafka Setup
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.12-2.8.0.tgz tar zxvf kafka_2.12-2.8.0.tgz -C ~/app cd kafka_2.12-2.8.0 # start the zookeeper service bin/zookeeper-server-start.sh config/zookeeper.properties # start the Kafka broker service bin/kafka-server-start.sh config/server.properties # create topic bin/kafka-topics.sh --create --topic spark_topic --bootstrap-server localhost:9092 # describle message bin/kafka-topics.sh --describe --topic spark_topic --bootstrap-server localhost:9092 # produce message bin/kafka-console-producer.sh --topic spark_topic --bootstrap-server localhost:9092 # consumer message bin/kafka-console-consumer.sh --topic spark_topic --from-beginning --bootstrap-server localhost:9092
Note:Spark Streaming 需要用到Kafka
SparkStreamingDemo.scala
package org.fool.spark import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.util.parsing.json.JSON object SparkStreamingDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("SparkStreamingDemo").setMaster("local") val streamingContext = new StreamingContext(sparkConf, Seconds(30)) val checkPointDirectory = "hdfs://127.0.0.1:9000/spark/checkpoint" streamingContext.checkpoint(checkPointDirectory) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "localhost:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "spark_streaming", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) val topics = Array("spark_topic") val stream = KafkaUtils.createDirectStream[String, String]( streamingContext, PreferConsistent, Subscribe[String, String](topics, kafkaParams) ) val etlResultDirectory = "hdfs://127.0.0.1:9000/spark/etl/" val etlResult = stream.map(record => record.value()).filter(message => JSON.parseFull(message).isDefined) etlResult.count().print() etlResult.saveAsTextFiles(etlResultDirectory) streamingContext.start() streamingContext.awaitTermination() } }
Note:程序是30s 一次的微批处理
Run Test
在kafka producer端输入message
{"name":"Caocao","create_time":"2021-06-22 01:45:52.478","update_time":"2021-06-22 02:45:52.478"}

Console Output

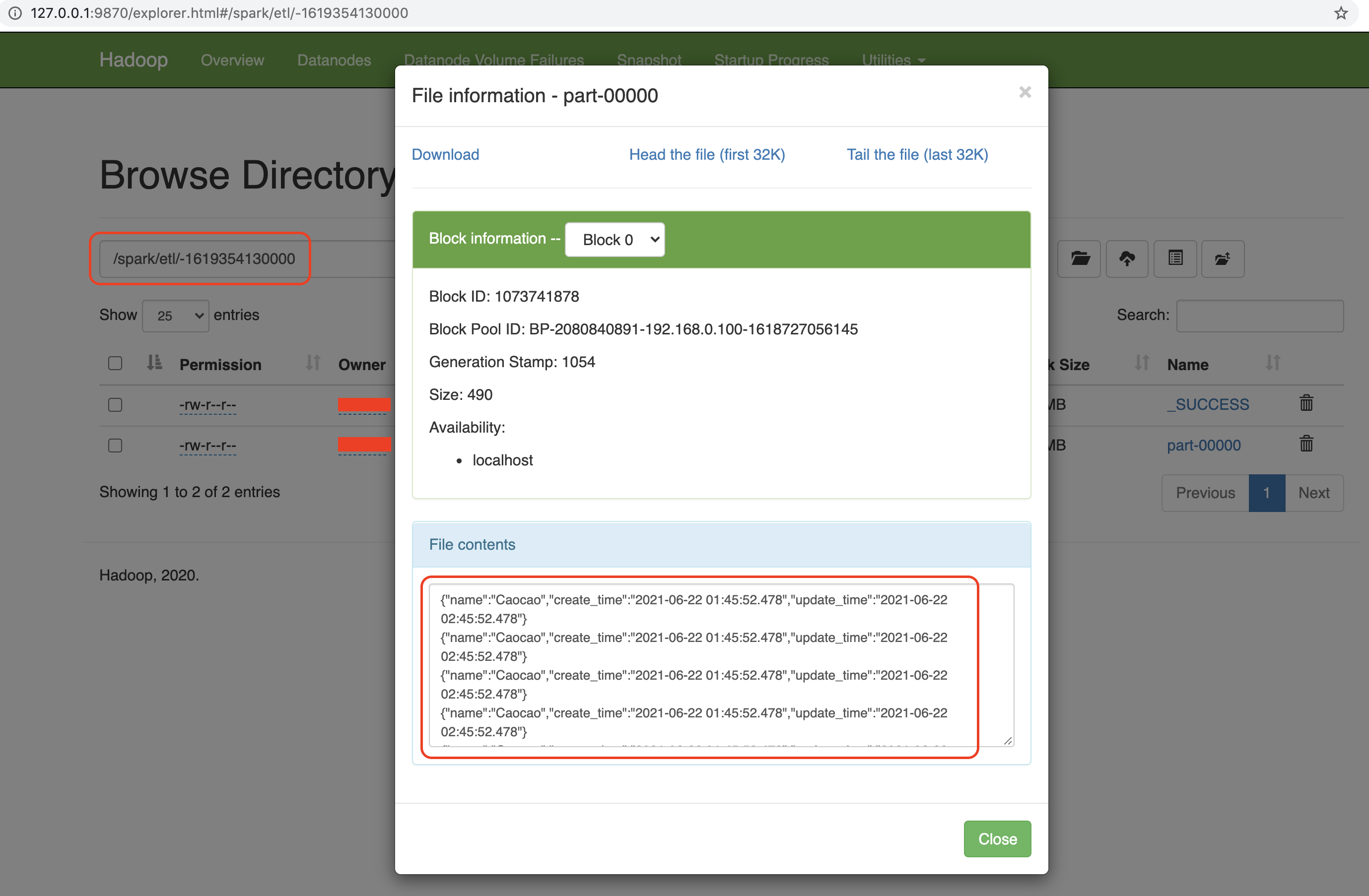
HDFS Output
强者自救 圣者渡人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号