降低损失:梯度下降法和随机梯度下降法
Reference: https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent
Gradient Descent
迭代方法图 包含一个标题为“计算参数更新”的华而不实的绿框。现在,我们将用更实质的方法代替这种华而不实的算法。
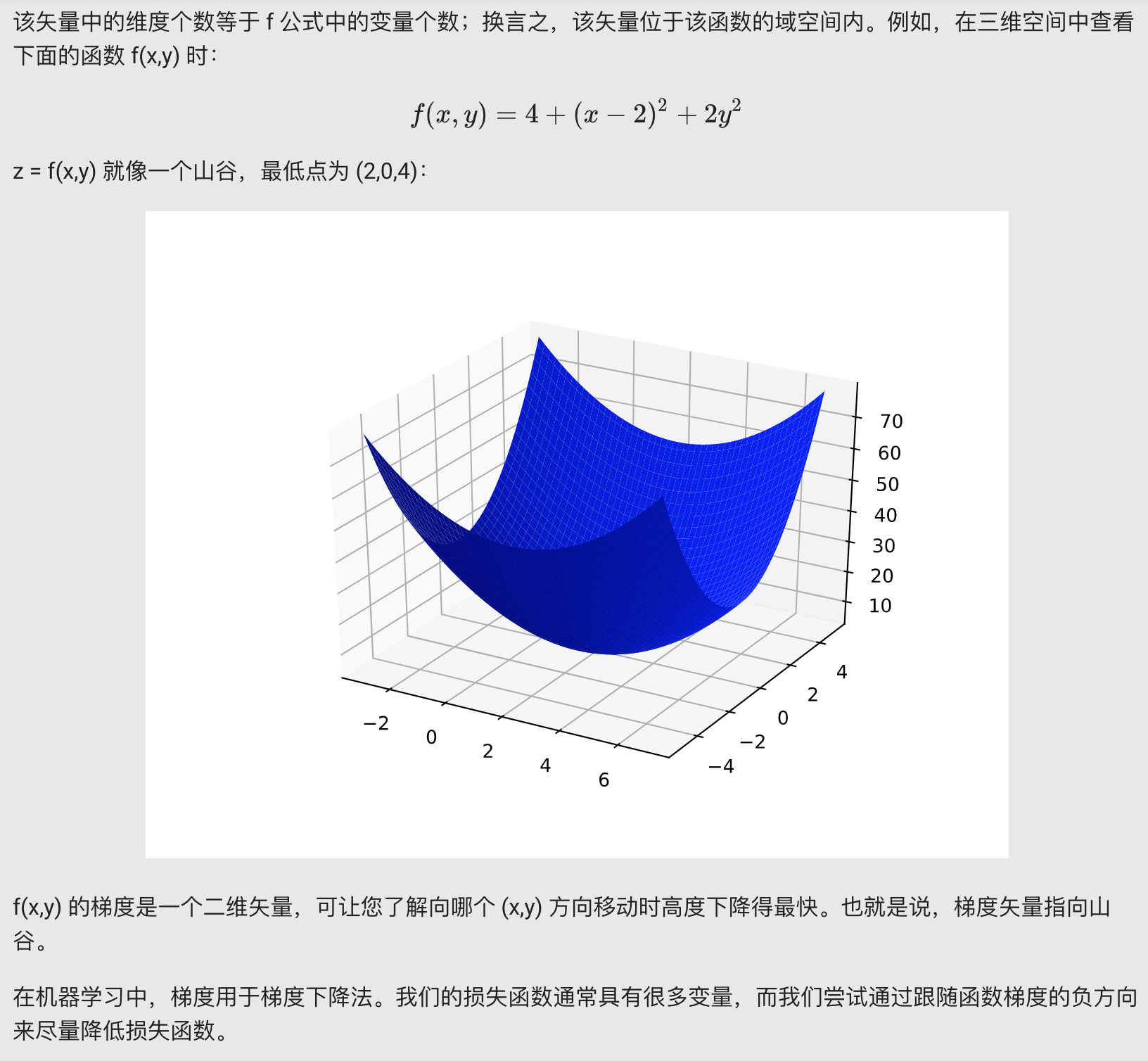
假设我们有时间和计算资源来计算 w1 的所有可能值的损失。对于我们一直在研究的回归问题,所产生的损失与 w1 的图形始终是凸形。换言之,图形始终是碗状图,如下所示:
回归问题产生的损失与权重图为凸形

凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置。这个最小值就是损失函数收敛之处。
通过计算整个数据集中 w1 每个可能值的损失函数来找到收敛点这种方法效率太低。我们来研究一种更好的机制,这种机制在机器学习领域非常热门,称为梯度下降法。
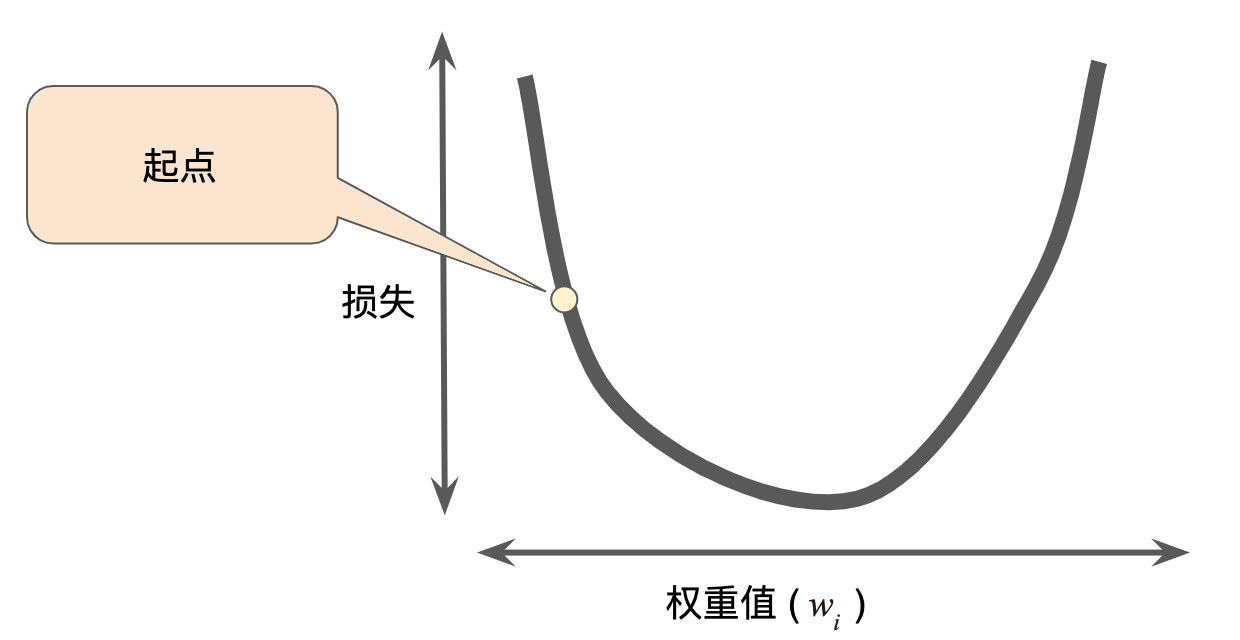
梯度下降法的第一个阶段是为 w1 选择一个起始值(起点)。起点并不重要;因此很多算法就直接将 w1 设为 0 或随机选择一个值。下图显示的是我们选择了一个稍大于 0 的起点:
梯度下降法的起点
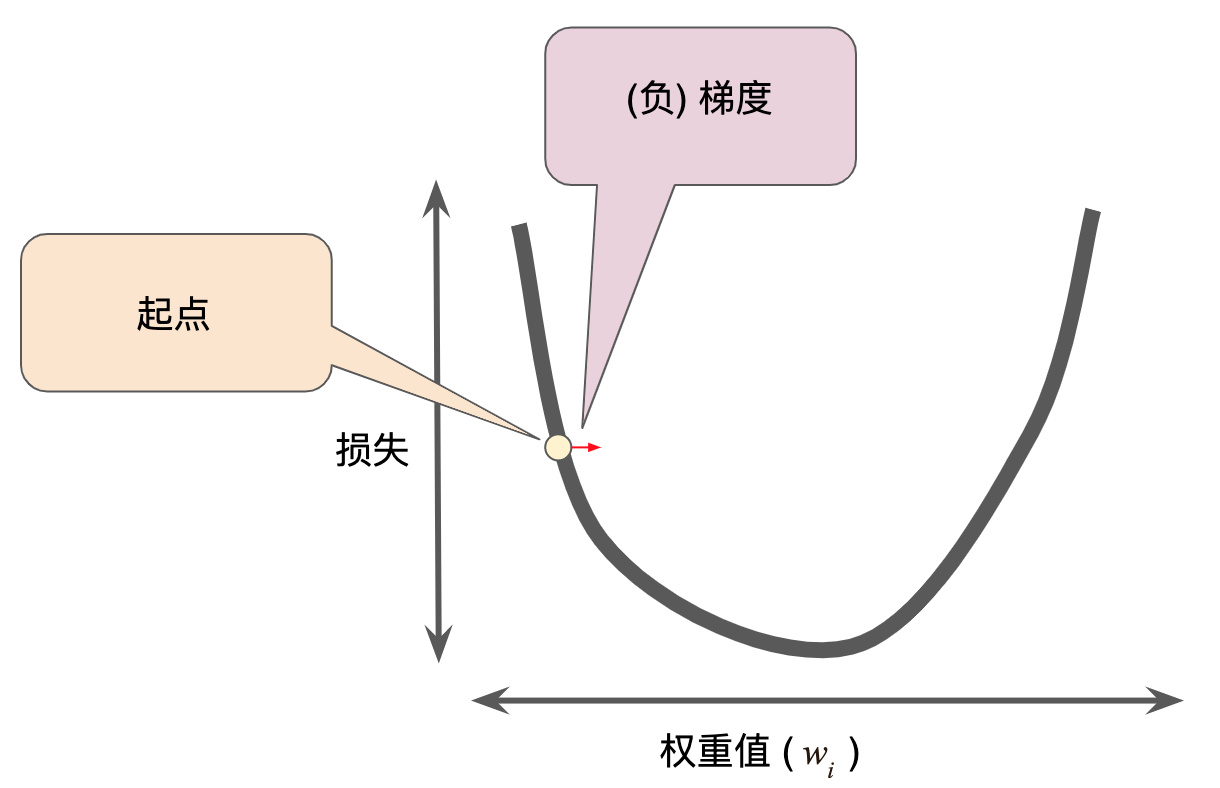
然后,梯度下降法算法会计算损失曲线在起点处的梯度。简而言之,梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”。请注意,损失相对于单个权重的梯度(如上图所示)就等于导数。
偏导数和梯度


请注意,梯度是一个矢量,因此具有以下两个特征:
- 方向
- 大小
梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。
梯度下降法依赖于负梯度
为了确定损失函数曲线上的下一个点,梯度下降法算法会将梯度大小的一部分与起点相加,如下图所示
一个梯度步长将我们移动到损失曲线上的下一个点
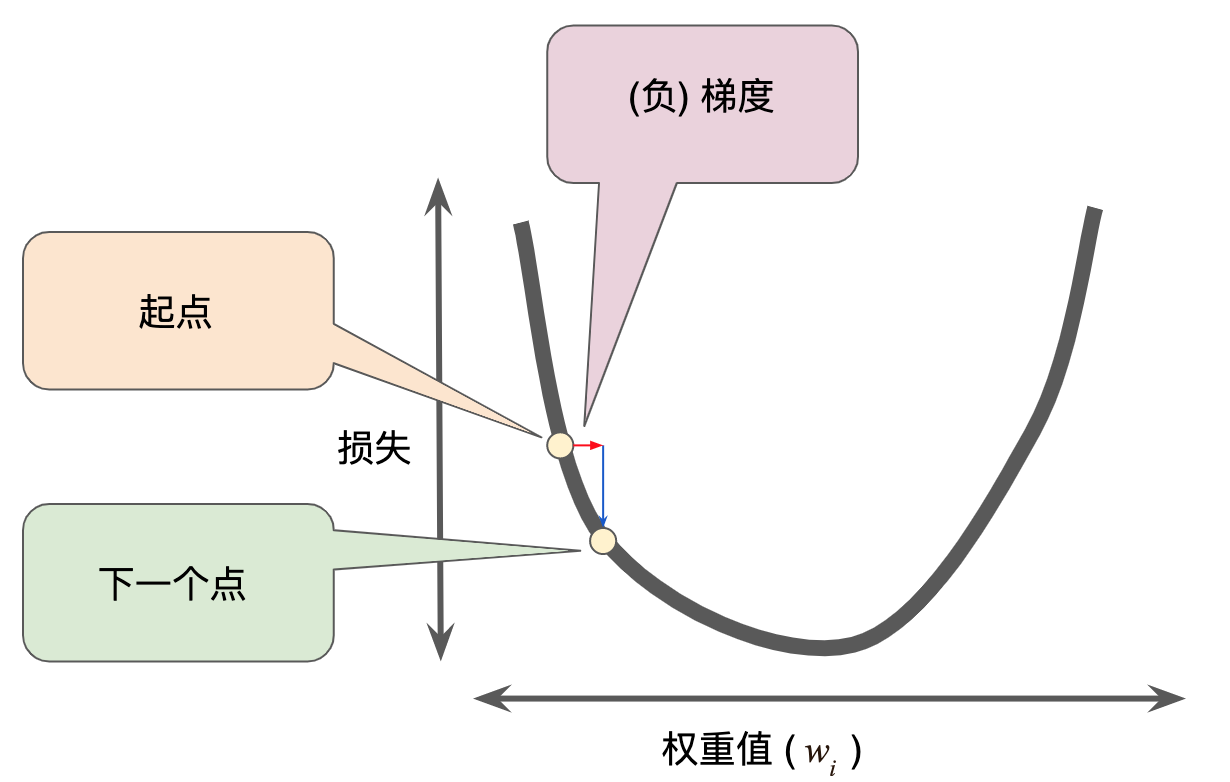
然后,梯度下降法会重复此过程,逐渐接近最低点。
Stochastic Gradient Descent
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数。到目前为止,我们一直假定批量是指整个数据集。就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本。此外,Google 数据集通常包含海量特征。因此,一个批量可能相当巨大。如果是超大批量,则单次迭代就可能要花费很长时间进行计算。
包含随机抽样样本的大型数据集可能包含冗余数据。实际上,批量大小越大,出现冗余的可能性就越高。一些冗余可能有助于消除杂乱的梯度,但超大批量所具备的预测价值往往并不比大型批量高。
如果我们可以通过更少的计算量得出正确的平均梯度,会怎么样?通过从我们的数据集中随机选择样本,我们可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。 随机梯度下降法 (SGD) 将这种想法运用到极致,它每次迭代只使用一个样本(批量大小为 1)。如果进行足够的迭代,SGD 也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。
小批量随机梯度下降法(小批量 SGD)是介于全批量迭代与 SGD 之间的折衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
为了简化说明,我们只针对单个特征重点介绍了梯度下降法。请放心,梯度下降法也适用于包含多个特征的特征集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号