

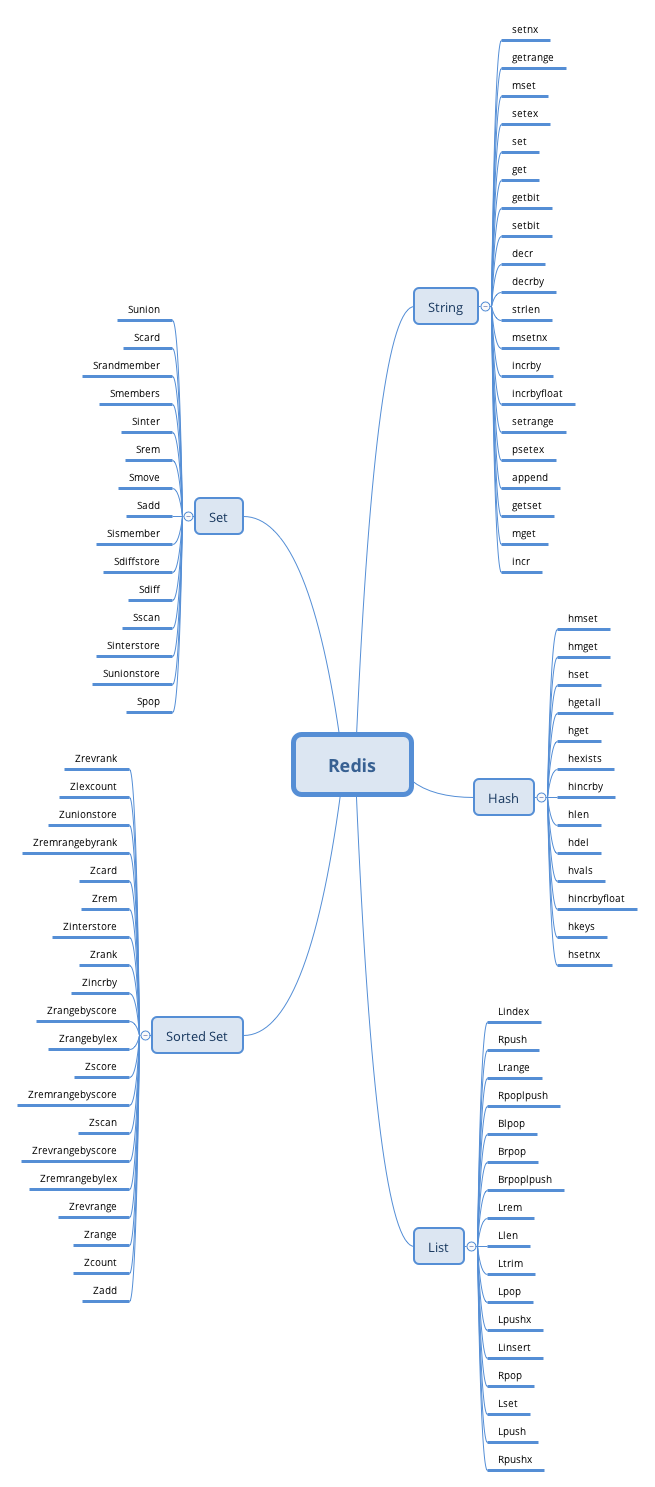
Redis五种数据类型及应用场景
原创转载请注明出处: https://www.cnblogs.com/agilestyle/p/11532375.html
String: 一般做一些复杂的计数功能的缓存
List: 做简单的消息队列的功能
Hash: 单点登录
Set: 做全局去重的功能
SortedSet: 做排行榜应用,取TopN操作;延时任务;做范围查找
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
|
String (字符串) |
Redis的字符串是动态字符串,是可以修改的字符串,它的内部表示就是一个字符数组, 内部结构的实现类似于Java的ArrayList 它的内部结构是一个带长度信息的字节数组 |
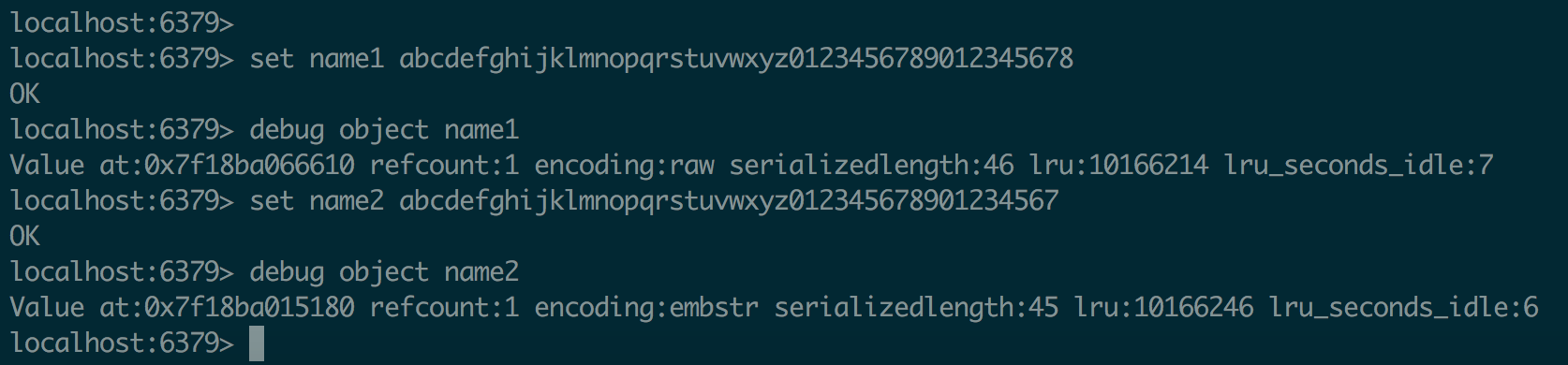
可以包含任何数据,比如jpg图片或者序列化的对象,规定字符串的长度不得超过512MB。 Redis的字符串有两种存储方式,在长度特别短时,使用embstr形势存储,而长度超过44字节时候,使用raw形势存储 |
1、访问量统计:每次访问博客和文章使用 INCR 命令进行递增 2、将数据以二进制序列化的方式进行存储 |
|
Hash (字典) |
Redis的字典相当于Java语言里面的HashMap 字典结构内部包含了两个Hashtable,通常情况下只有一个Hashtable是有值的, 但是在字典扩容缩容时候,需要重新分配新的Hashtable,然后进行渐进式搬迁,这时候两个Hashtable存储的分别是旧的Hashtable和新的Hashtable;待搬迁结束后,旧的Hashtable被删除,新的Hashtable取而代之 |
适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去)。 大字典的扩容是比较耗时的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个O(n)级别的操作,作为单线程的Redis很难承受这样耗时的过程,所以Redis使用渐进式rehash小步搬迁虽然慢一点,但是肯定可以搬完。 |
1、存储、读取、修改对象属性,比如:用户(姓名、性别、爱好),文章(标题、发布时间、作者、内容) |
|
List (列表) |
Redis的列表相当于Java的LinkedList List的结构底层实现不是一个简单的LinkedList,而是快速链表(quicklist)。 首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存;当数据量比较多的时候才会改成quicklist。 |
增删快,提供了操作某一段元素的API 普通的链表需要的附加指针空间太大,会浪费空间,加重内存的碎片化。Redis将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串联起来使用,既满足了快速的插入删除性能,又不会出现太大的空间冗余 |
1、最新消息排行等功能(比如朋友圈的时间线) 2、消息队列 |
|
Set (集合) |
Redis的集合相当于Java语言里面的HashSet,内部的键值对是无须的、唯一的 Set的结构底层实现是字典,只不过所有的value都是NULL,其他的特性和字典一摸一样。 |
1、添加、删除、查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 当set集合容纳的元素都是整数并且元素个数较少时,Redis会使用intset来存储集合元素。intset是紧凑的数组结构,同时支持16位,32位和64位整数 |
1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
|
Sorted Set (有序集合) |
Redis有序列表类似于Java的SortedSet和HashMap的结合体, 一方面是一个set,保证内部value的唯一性,另一方面可以给每个value赋予一个score,代表这个value的排序权重。 它的内部实现是一个Hash字典 + 一个跳表。 |
数据插入集合时,已经进行天然排序 Redis的跳表共有64层,能容纳2的64次方个元素。 Redis之所以用跳表来实现有序集合 1. 插入、删除、查找以及迭代输出有序序列这几个操作,红黑树都能完成,时间复杂度跟跳表是一样的。但是按照区间来查找数据,红黑树的效率就没有跳表高 2. 跳表更容易代码实现,比起红黑树来说还是好懂、好写很多,可读性好,不容易出错 3. 跳表更加灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗 |
1、排行榜,取TopN操作 2、带权重的消息队列 |
Note:
可以使用debug object key_name来查看内部结构
string内部结构,在长度特别短时,使用embstr形势存储(embeded),而当长度超过44字节时,使用raw形势存储
set内部结构,当set放进去了非整数值时,存储形势立即从intset转变成了hashtable

Redis为了节约内存空间使用,zset和hash容器对象在元素个数较少的时候,采用压缩列表(ziplist)进行存储。压缩列表是一块连续的存储内存空间,元素之间紧挨存储,没有任何冗余空隙。
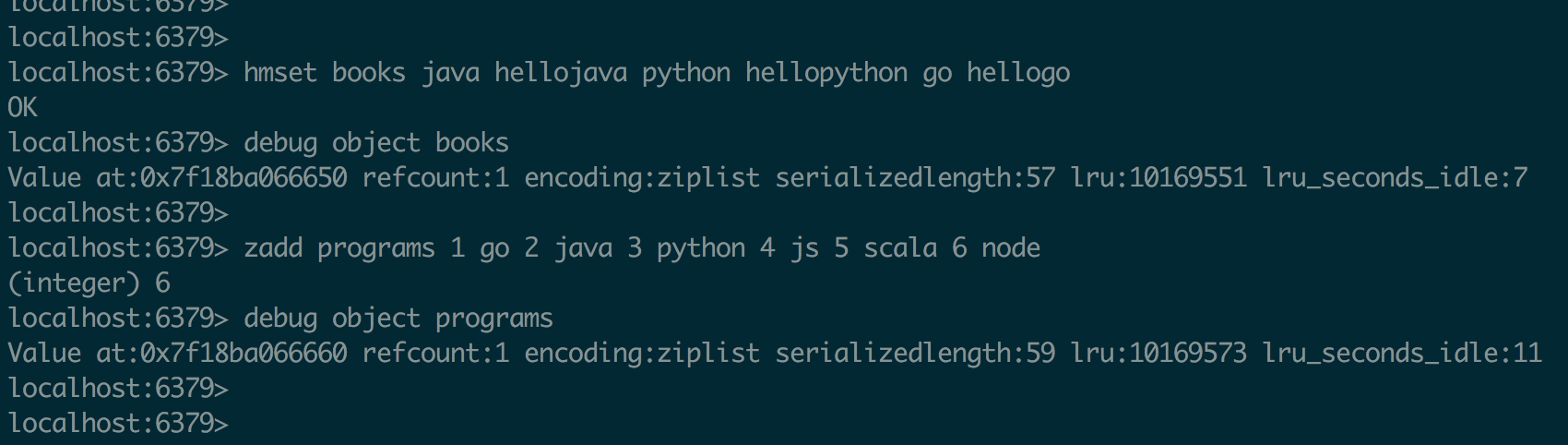
list内部结构,注意观察encoding的值,quicklist是ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用ziplist让存储紧凑,多个ziplist之间使用双向指针串接起来。

Reference
https://www.redis.net.cn/order/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix