分布式事务
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11480407.html
CAP定律

Note:
zookeeper是按照CP原则构建的
NoSQL按数据模型存储性质 分4类
- 键值存储(Key-Value stores) —— Redis(适合Session信息、用户配置信息、购物车数据)
- 面向表(Table-oriented) —— BigTable、Cassandra、HBase(适合事件记录、CMS、博客平台、计数器、不适合ACID、查询模式变化频繁的场合)
- 面向文本(Document-oriented) —— MongoDB(适合事件记录、CMS、博客平台、网站分析、实时分析、电子商务应用)
- 面向图(Graph-oriented) —— Neo4j(适合互联网数据,推荐引擎,基于位置的服务)
与传统的关系型数据库相比,HBase有更好的伸缩能力,跟适合海量数据的存储和处理,并且HBase能够支持多个Region Server的写入,并发写入性能十分出色。但是HBase本身所支持的查询维度有限,难以支持复杂的条件查询,如group by、order by、join等,这些特点是它的应用场景受到了限制。
对于Redis来说,它拥有更好的读写吞吐能力,能够支撑更高的并发数,而相较于其他的key-value类型的数据库,Redis能够提供更为丰富的数据类型支持,能更灵活地满足业务需求。
在分布式系统中,同时满足“CAP定律”中的“一致性”、“可用性”和“分区容错性”三者是不可能的,这比现实中找对象需同时满足“高、富、帅”或“白、富、美”更加困难。在互联网领域的绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。

需要明确的一点是,对于一个分布式系统而言,分区容错性可以说是一个最基本的要求。因为既然是一个分布式系统,那么分布式系统中的组件必然需要被部署到不同的节点,否则也就无所谓分布式系统了,因此必然出现子网络。而对于分布式系统而言,网络问题又是一个必定会出现的异常情况,因此分区容错性也就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构师往往需要把精力花在如何根据业务特点在C(一致性)和A(可用性)之间寻求平衡。
BASE理论
BASE是 Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致性)三个 短语的简写。BASE是对CAP中一致性和可用性权衡的结果,其来源于大规模互联网系统分布式实践的总结,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventually consistency)。
基本可用

弱状态

最终一致性

总的说来,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计中,ACID特性与BASE理论往往又会结合在一起使用。
分布式事务的服务架构部署
以商城为例,通常,都是基于第二种架构部署实现的
- 同服务不同数据库

- 不同服务不同数据库

分布式事务处理模式
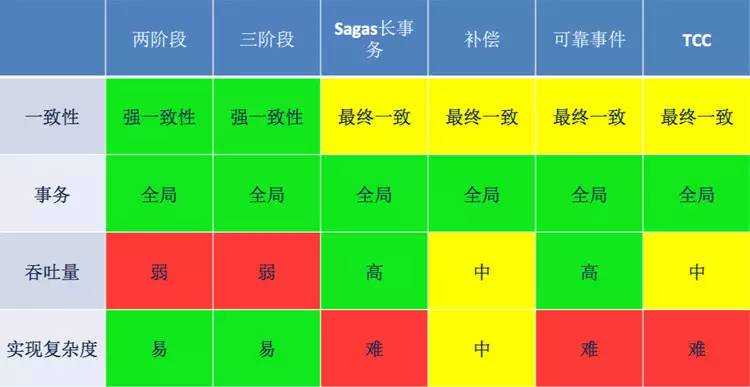
涉及分布式数据库,则要考虑使用分布式事务,最常见的如两阶段提交、三阶段提交协议,这种方式实现事务回滚难度较低,但是对性能影响比较大,因为在大多数场景中需要的是最终一致性,而不是强一致性。因此,可以考虑事务表、消息队列、补偿机制(执行/回滚)、TCC模式(预占/确认/取消)、Sagas模式(拆分事务+补偿机制)等实现最终一致性。
Reference
https://www.infoq.cn/article/solution-of-distributed-system-transaction-consistency/
https://www.open-open.com/lib/view/open1473404638516.html
https://yq.aliyun.com/articles/599997
https://time.geekbang.org/column/article/127527

 浙公网安备 33010602011771号
浙公网安备 33010602011771号