InnoDB索引存储结构
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/11429438.html
InnoDB默认创建的主键索引是聚簇索引(Clustered Index),其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚簇索引。
接下来通过一个简单的例子,说明下这两种索引在存储数据中的具体实现。
首先创建一张商品表,如下:
1 CREATE TABLE `merchandise` ( 2 `id` int(11) NOT NULL, 3 `serial_no` varchar(20) DEFAULT NULL, 4 `name` varchar(255) DEFAULT NULL, 5 `unit_price` decimal(10, 2) DEFAULT NULL, 6 PRIMARY KEY (`id`) USING BTREE 7 ) CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
然后新增了以下几行数据,如下:
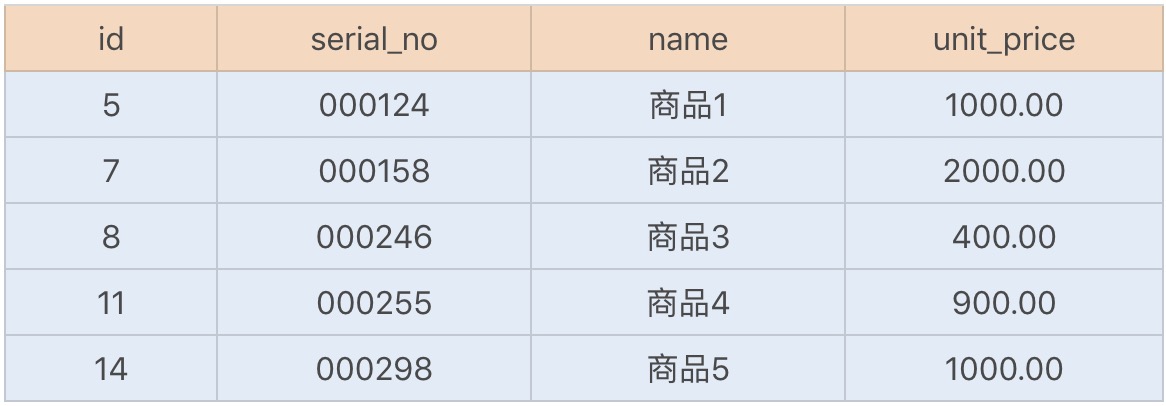
使用的是InnoDB存储引擎,由于InnoDB使用的是聚簇索引,聚簇索引中的叶子节点则记录了主键值、事务id、用于事务和MVCC的回流指针以及所有的剩余列,如下图所示:
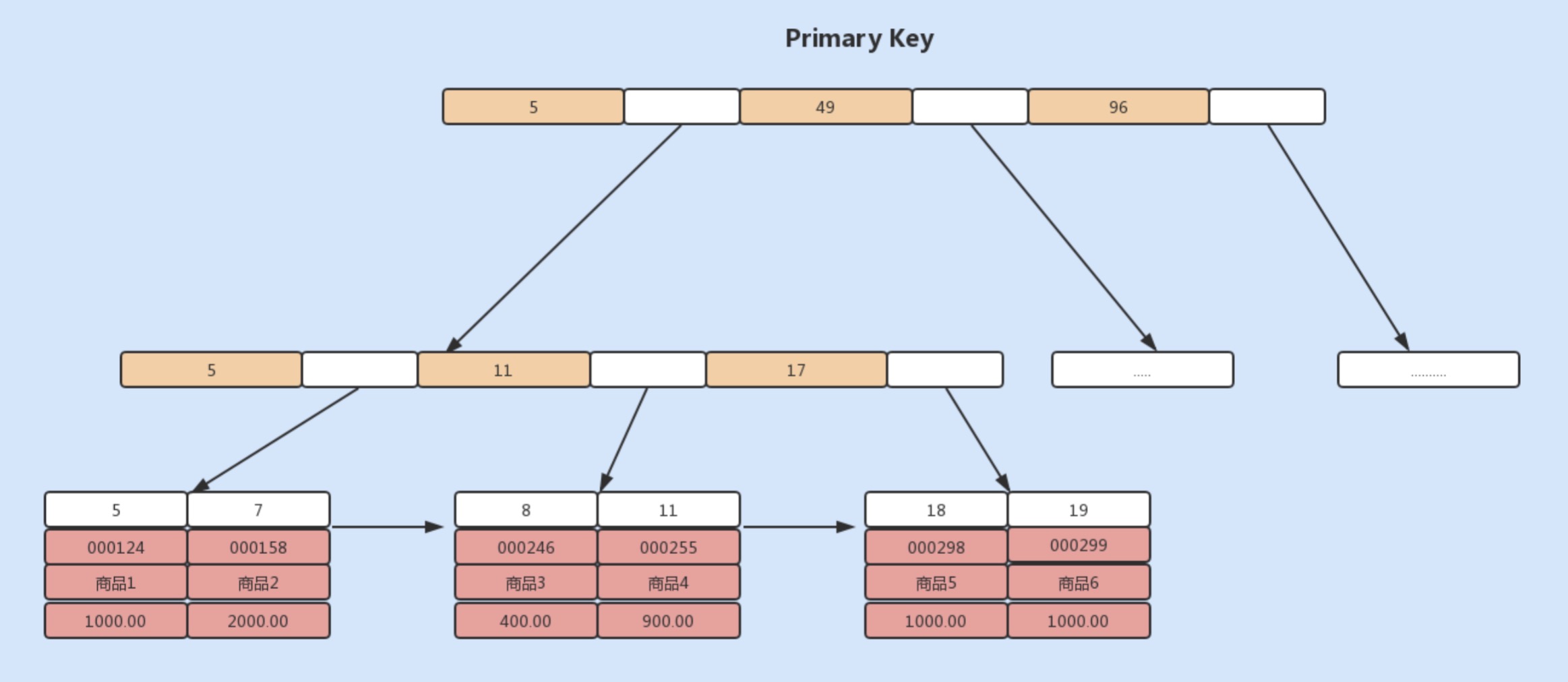
基于上面的图示,如果需要根据商品编码serial_no查询商品,就需要将商品编码serial_no列作为一个索引列。此时创建的索引是一个辅助索引,但叶子节点存储的就不是行指针了,而是主键值,并以此来作为指向行的指针。这样的好处就是当行发生移动或者数据分裂时,不用再维护索引的变更。
回表
如果使用主键索引查询商品,则会按照B+树的索引找到对应的叶子节点,直接获取到行数据:
1 select * from merchandise where id = 7
如果使用serial_no查询商品,即使用辅助索引进行查询,则会先检索辅助索引中的B+树的serial_no,找到对应的叶子节点,获取主键值,然后再通过聚簇索引中的B+树检索到对应的叶子节点,然后获取整行数据。这个过程叫做回表。
回表就是先通过辅助索引扫描出数据所在的行,再通过行主键id取出索引中未提供的数据,即基于非主键索引的查询需要多扫描一棵索引树。
覆盖索引
假设只需要查询商品的名称、价格信息,有什么方式来避免回表呢?可以建立一个组合索引,即商品编码、名称、价格作为一个组合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
从辅助索引中查询得到记录,而不需要通过聚簇索引查询获得,MySQL中将其称为覆盖索引。使用覆盖索引的好处很明显,不需要查询出包含整行记录的所有信息,因此可以减少大量的I/O操作。
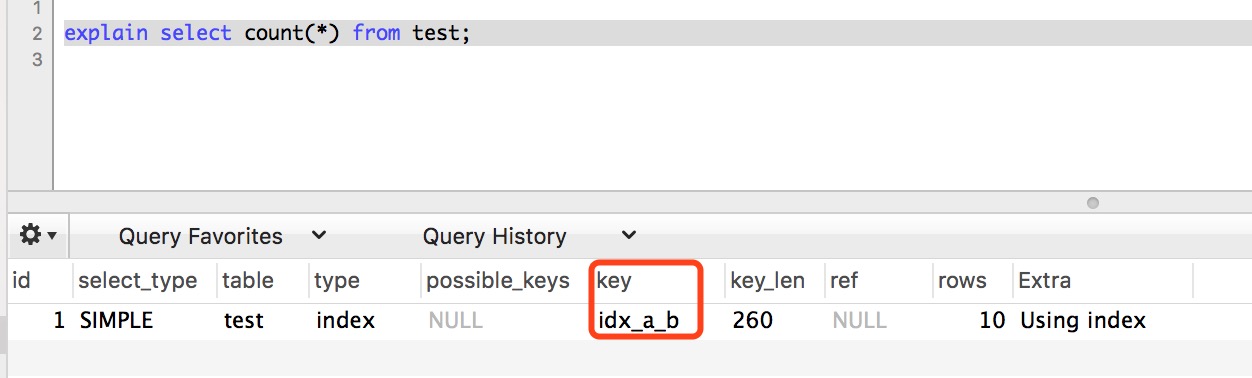
通常在InnoDB中,除了查询部分字段可以使用覆盖索引来优化查询性能之外,统计数量也会用到。例如, SELECT COUNT(*)时,如果不存在辅助索引,此时会通过查询聚簇索引来统计行数,如果此时正好存在一个辅助索引,则会通过查询辅助索引来统计行数,减少I/O操作。
1 CREATE TABLE `test` ( 2 `id` int(10) unsigned NOT NULL AUTO_INCREMENT, 3 `a` varchar(32) NOT NULL, 4 `b` varchar(32) NOT NULL, 5 `c` varchar(64) NOT NULL, 6 `d` varchar(128) NOT NULL, 7 `e` varchar(256) NOT NULL, 8 `create_time` timestamp(3) NOT NULL DEFAULT current_timestamp(3), 9 `update_time` timestamp(3) NOT NULL DEFAULT current_timestamp(3) ON UPDATE current_timestamp(3), 10 PRIMARY KEY (`id`), 11 KEY `idx_a_b` (`a`,`b`) 12 ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号