Hashicorp Raft实现和API分析
1. Hashicorp Raft实现分析
在raft算法中,典型的领导者选举在本质上是节点状态的变更。具体到raft源码中,领导者选举的入口函数就是run(),在raft.go中以一个单独的协程运行,来实现节点状态的变更
在下面的实现代码中,可以看到Follower、Candidate和Leader三个节点状态对应的功能都被抽象为了一个函数runXxx()
func (r *Raft) run() {
for {
select {
case <-r.shutdownCh:
r.setLeader("")
return
default:
}
switch r.getState() {
case Follower:
r.runFollower()
case Candidate:
r.runCandidate()
case Leader:
r.runLeader()
}
}
}
1.1 数据结构
每个节点都有其自己的状态,也就是三种角色。节点状态相关的数据结构和定义,在state.go中实现的,定义为数据结构RaftState,是一个32位只读整型:
type RaftState uint32
const (
Follower RaftState = iota
Candidate
Leader
Shutdown
)
需要注意的是,也存在一些需要使用字符串格式的节点状态的场景,比如在日志输出中,这时可以使用RaftState.String()函数来实现
在raft中,每个节点都需要维护自己的信息,比如任期编号、索引值等
raftState是一个结构体,是表示节点信息的一个大数据结构,里面包含了只属于本节点的信息,比如节点的当前任期号、最新提交的日志项的索引值、存储中最新日志项的索引值和任期编号、当前节点的状态等:
type raftState struct {
// 当前任期编号
currentTerm uint64
// 最大被提交的日志项的索引值
commitIndex uint64
// 最新被应用到状态机的日志项的索引值
lastApplied uint64
// 存储中最新的日志项的索引值和任期编号
lastLogIndex uint64
lastLogTerm uint64
// 当前节点的状态
state RaftState
......
}
在分布式系统中要实现领导者选举,最重要的内容是实现RPC消息,因为领导者选举的过程就是一个RPC通信的过程
RPC消息相关的数据结构是在commands.go中定义的,比如日志复制RPC的请求消息,对应的数据结构为AppendEntriesRequest,里面包含了raft算法论文中约定的字段,比如以下内容:
Term:当前的任期编号PrevLogEntry:当前要复制的日志项,前面一条日志项的索引值PrevLogTerm:当前要复制的日志项,前面一条日志项的任期编号Entries:新日志项
type AppendEntriesRequest struct {
// 当前的任期编号,和领导者信息(包括服务器ID和地址信息)
Term uint64
Leader []byte
// 当前要复制的日志项,前面一条日志项的索引值和任期编号
PrevLogEntry uint64
PrevLogTerm uint64
// 新日志项
Entries []*Log
// 领导者节点上的已提交的日志项的最大索引值
LeaderCommitIndex uint64
}
1.2 领导选举
首先,在初始状态下,集群中所有的节点都处于跟随者状态,函数runFollower()运行,大致的执行步骤为:
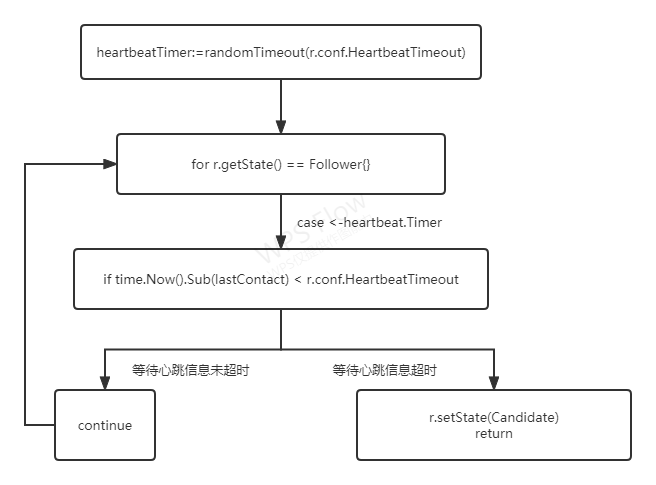
- 根据配置中心的心跳超时时长,调用
randomTimeout()函数来获取一个随机值,用以设置心跳超时时间间隔 - 进入到for循环中,通过select实现多路IO复用,周期性获取消息和处理。如果步骤1中设置的心跳计时器发生超时,执行步骤3
- 如果等到信条信息未超时,执行步骤4,如果等待心跳信息超时,执行步骤5
- 执行continue语句,开始一次新的for循环
- 设置节点状态为候选人,并退出
runFollower()函数
当节点推举自己为候选人之后,执行runCandidate()函数,大致的执行步骤如下所示:
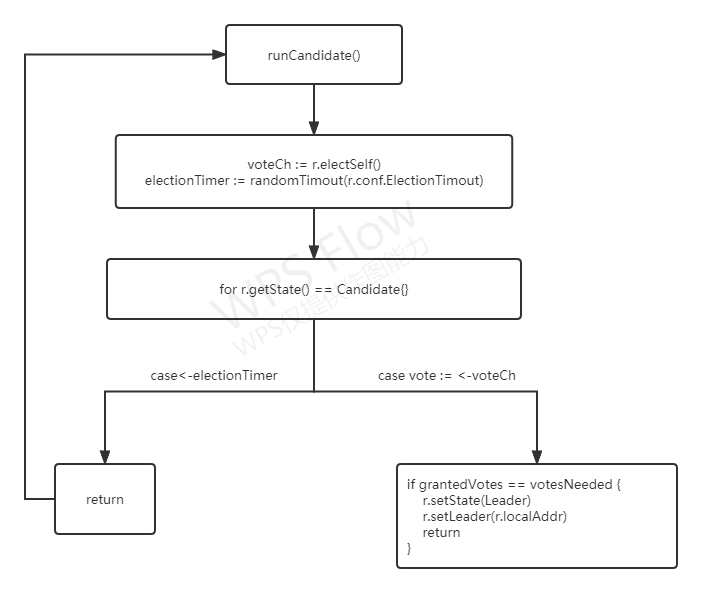
- 首先调用
electSelf()发起选举,给自己投一张选票,并向其他节点发送请求投票RPC消息,请求他们选举自己为领导者。然后调用randomTimeout()函数,获取一个随机值,设置选举超时时间 - 进入到for循环中,通过select实现多路IO复用,周期性获得消息和处理。如果发生了选举超时,执行步骤3,如果得到了投票信息,执行步骤4
- 发现了选举超时,退出
runCandidate()函数,然后再重新执行runCandidate()函数,发起新一轮的选举 - 如果候选人在执行时间内赢得了大多数选票,那么候选人将当选为领导者,调用
setState()函数,将自己的状态变更为领导者,并退出runCandidate()函数
当节点当选为候选人之后,函数runLeader()就执行了,大致的执行步骤如下所示:
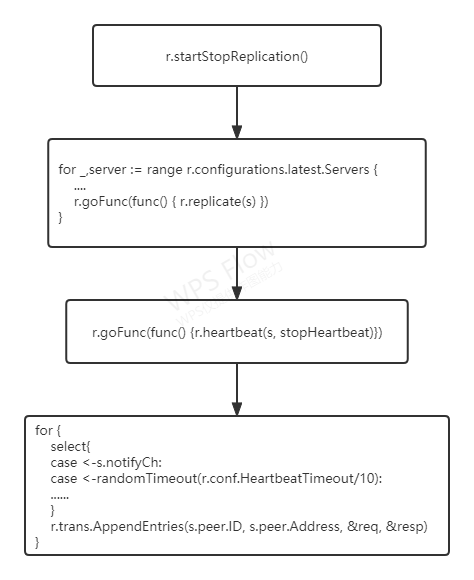
- 调用
startStopReplication(),执行日志复制功能 - 启动新的协程,调用
replicate()函数,执行日志复制功能 - 接着在
replicate()函数中,启动一个新的协程,调用heartbeat()函数,执行心跳功能 - 在
heartbeat()函数中,周期性地发送心跳消息,通知其他节点我是领导者,不需要新的选举
其实,实现raft的领导者选举并不难,领导选举的本质就是节点的状态变更
1.3 日志复制
首先应该明确日志复制是由领导者发起的,跟随者来接收的
领导者复制日志和跟随者接收日志的入口函数,分别应该在runLeader()和runFollower()函数中调用的
- 领导者日志复制的入口函数为
startStopReplication(),在runLeader()中,以r.startStopReplication()形式被调用,作为一个单独的协程运行 - 跟随者接收日志的入口函数为
processRPC(),在runFollower()中以r.processRPC(rpc)的形式被调用,用来处理日志复制RPC的消息
一条日志项主要包含了三种信息,分别是指令、索引值、任期编号,而在Hashicorp Raft的实现中,日志对应的数据结构和函数接口是在log.go中实现的。其中,日志项对应的数据结构是结构体类型的,就像下面的样子:
type Log struct {
Index uint64 // 索引值
Term uint64 // 任期编号
Type LogType // 日志项类别
Data []byte // 指令
Extensions []byte // 扩展信息
}
与协议中的定义不同,日志项对应的数据结构中,包含了LogType和Extensions两个额外的字段:
LogType可用于标识不同用途的日志,比如使用LogCommand标识指令对应的日志项,使用LogConfiguration表示成员变更配置对应的日志项Extensions可用于在指定日志项中存储一些额外的信息
日志复制是由领导者发起的,在runLeader()函数中直行,主要有如下几个步骤:
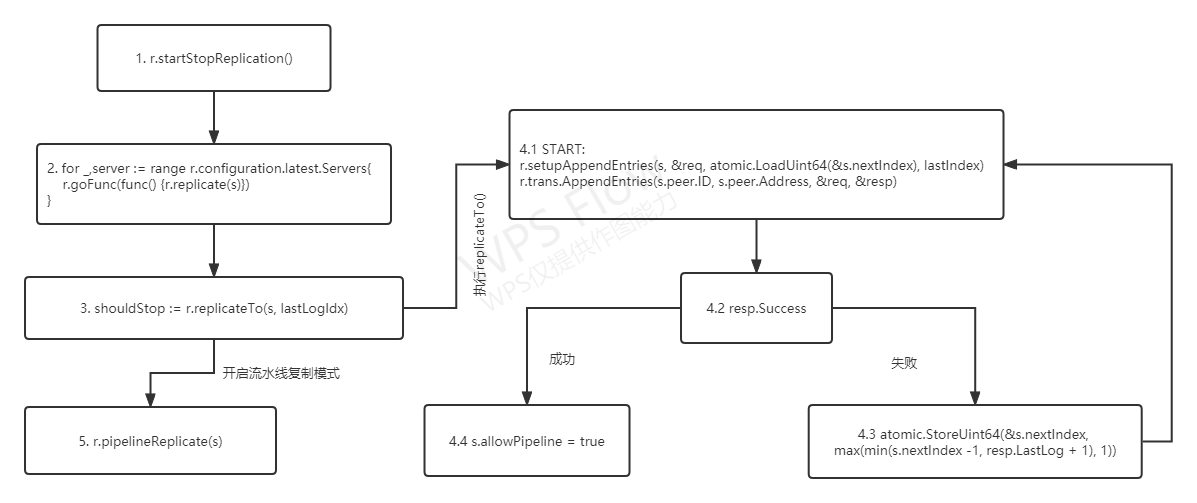
- 在
runLeader()函数中,调用startStopReplication()函数,执行日志复制功能 - 启动一个新协程,调用
replicate()函数,执行日志复制相关的功能 - 在
replicate()函数中,调用replicateTo()函数,执行步骤4,如果开启了流水线复制模式,执行步骤5 - 在
replicateTo()函数中,进行日志复制和日志一致性检测,如果日志复制成功,则设置s.allowPipeline = true,开启流水线复制模式 - 调用
pipelineReplicate()函数,采用更搞笑的流水线方式进行日志复制
在不需要进行日志一致性检测,复制功能已经正常运行的时候,开启流水线复制模式,目标是在环境正常的情况下,提升日志复制性能
如果在日志复制的过程中出错了,就进入RPC复制模式,继续调用replicateTo()函数,进行日志复制
领导者完成日志复制之后,跟随者会接收日志并开始处理日志
跟随者处理日志是在runFollower()函数中执行的,主要有这样几个步骤:
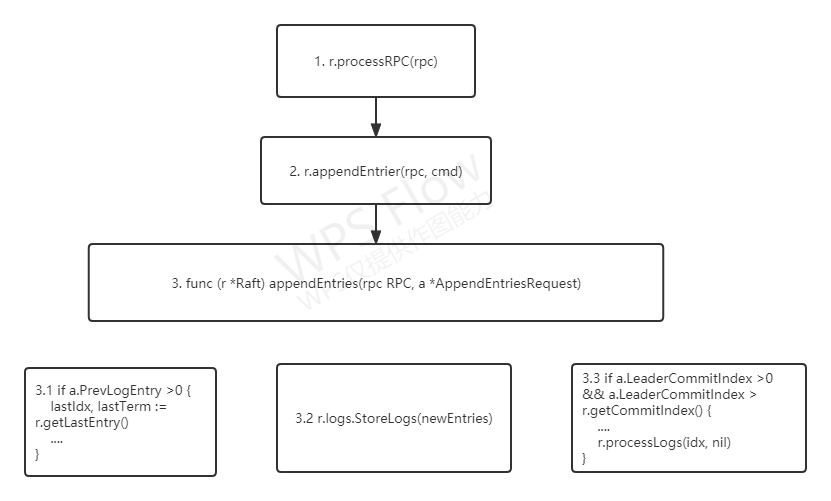
- 在
runFollower()函数中,调用processRPC()函数,处理接收到的RPC消息 - 在
processRPC()函数中,调用appendEntries()函数,处理接收到的日志复制RPC请求 appendEntries()函数,是跟随者处理日志的核心函数。在步骤3.1中,比较日志一致性;在步骤3.2中,将新日志项存放到本地;在步骤3.3中,根据领导者最新提交的日志项索引值,来计算当前需要被应用的日志项,并应用到本地状态机
2. Hashicorp Raft API
API手册:https://pkg.go.dev/github.com/hashicorp/raft
2.1 创建Raft节点
在Hashicorp Raft中,可以通过NewRaft()函数来创建一个raft节点
NewRaft()是非常核心的函数,是raft节点的抽象实现,其函数签名如下:
func NewRaft(
conf *Config,
fsm FSM,
logs LogStore,
stable StableStore,
snaps SnapshotStore,
trans Transport) (*Raft, error)
从这段代码中,可以看到我们创建一个raft节点所需要的参数:
Config:节点的配置信息FSM:有限状态机LogStore:用来存储raft的日志StableStore:稳定存储,用来存储raft集群的节点信息SnapshotStore:快照存储,用来存储节点的快照信息Transport:raft节点之间的通信通道
这六种参数决定了raft节点的配置、通信、存储、状态机操作等核心信息,所以要注意是如何创建这些参数信息的
2.1.1 Config
Config是节点的配置信息,可以通过DefaultConfig()来创建默认配置信息,然后按需修改对应的配置项
有时候需要根据使用场景来调整配置,比如:
- 在生产环境下,可以将
LogLevel从DEBUG调整为WARN或者ERROR - 如果部署环境中网络拥堵,可以适当调大
HeartbeatTimeout的值,比如从1s调整为1.5s,避免频繁的领导者选举
2.1.2 FSM
FSM是日志处理的核心实现,借助Golang Interface的泛型编程能力,应用程序可以实现自己的Apply(*Log)、Snapshot()、Restore(io.ReadCloser)这三个函数,分别实现将日志应用到本地状态机、生成快照和根据快照恢复数据的功能
2.1.3 LogStore
LogStore存储的是raft日志,可以利用raft-boltdb来实现底层存储,持久化存储数据
raft-boltdb:https://github.com/hashicorp/raft-boltdb
NewBoltStore()函数只支持一个参数,也就是文件路径
logStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-log.db"))
2.1.4 StableStore
StableStore同样存储的节点的关键状态信息,比如当前任期号、最新投票时的任期号等,同样可以使用boltdb来实现底层存储
stableStore, err := raftboltdb.NewBoltStore(filepath.Join(raftDir, "raft-stable.db"))
2.1.5 SnapshotStore
SnapshotStore存储的是快照信息,也就是压缩后的日志数据
在Hashicorp Raft中提供了三种快照的存储方式,它们分别是:
- DiscardSnapshotStore:不存储,忽略快照,一般用于测试
- FileSnapshotStore:文件持久化存储
- InmemSnapshotStore:内存存储,不持久化,重启程序数据丢失
一般建议选择文件持久化存储,也就是使用NewFileSnapshotStore()函数
其支持三个参数,也就是说,除了指定存储路径raftDir,还需要指定需要保留的快照副本的数量retainSnapshotCount以及日志输出的方式
snapshots, err := raft.NewFileSnapshotStore(raftDir, retainSnapshotCount, os.Stderr)
2.1.6 Transport
Transport指的是raft集群内部节点之间的通信机制,节点之间需要通过这个通道来进行日志同步、领导者选举等
Hashicorp Raft支持两种方式:
- 基于TCP协议的TCPTransport,可以跨机器跨网络通信
- 基于内存的InmemTransport,在内存中通过Channel来通信
NewTCPTransport()函数支持 5 个参数,也就是,指定创建连接需要的信息。比如,要绑定的地址信息(raftBind、addr)、连接池的大小(maxPool)、超时时间(timeout),以及日志输出的方式,一般而言,将日志输出到标准错误 IO 就可以了
addr, err := net.ResolveTCPAddr("tcp", raftBind)
transport, err := raft.NewTCPTransport(raftBind, addr, maxPool, timeout, os.Stderr)
2.2 增加集群节点
集群最开始的时候,只有一个节点,让第一个节点通过bootstrap的方式启动,它启动后成为领导者:
raftNode.BootstrapCluster(configuration)
BootstrapCluster()函数只支持一个参数,也就是raft集群的配置信息,因为此时只有一个节点,所以配置信息为这个节点的地址信息
后续节点在启动的时候,可以通过向第一个节点发送加入集群的请求,然后加入集群中
具体来说,先启动的节点收到请求后,获取对方的地址然后调用AddVoter()把新节点加入到集群就可以了
raftNode.AddVoter(id, addr, prevIndex, timeout)
AddVoter()函数支持四个参数,使用时一般只需要设置服务器ID信息和地址信息,其他参数使用默认值就可以
id:服务器ID信息addr:地址信息prevIndex:前一个集群配置的索引值,一般设置为0,使用默认值timeout:在完成集群配置的日志项添加前,最长等待多久,一般设置为0,使用默认值
也可以通过AddNonvoter(),将一个节点加入到集群中,但是不赋予它投票权,让它只接收日志记录
2.3 移除集群节点
通过RemoveServer()函数来移除节点,具体代码如下:
raftNode.RemoveServer(id, prevIndex, timeout)
RemoveServer()函数支持三个参数,使用时一般只需要设置服务器ID信息,其他参数使用默认值就可以:
id:服务器ID信息prevIndex:前一个集群配置的索引值,一般设置为0,使用默认值timeout:在完成集群配置的日志项添加前,最长等待多久,一般设置为0,使用默认值
RemoveServer()函数必须运行在领导者节点上,否则会报错
2.4 查看节点状态
通过Raft.Leader()函数,查看当前领导者的地址
通过Raft.State()函数,查看当前节点的状态(leader/candidate/follower)
比如通过下面的代码判断当前节点是不是领导者:
func isLeader() bool {
return raft.State() == raft.Leader
}
参考:
https://time.geekbang.org/column/article/213872
https://time.geekbang.org/column/article/217049

 浙公网安备 33010602011771号
浙公网安备 33010602011771号