
雪崩:限流算法的golang实现
1. 什么是服务器雪崩
雪崩是由于局部故障被正反馈循环,从而导致的不断放大的连锁故障,雪崩通常是由于整个系统中,一个很小的部分出现故障,进而导致整个系统不可用
雪崩出现的根本原因就是系统过载,如果在系统过载的情况下,不进行任何控制,那么会导致系统雪崩
想要避免雪崩有几种常见的方式,第一种就是快速减少系统负载,即熔断、降级、限流等方式;第二种就是通过增加系统服务能力来避免雪崩,就是弹性扩容
这篇只讨论限流的具体原理及实现
2. 常见限流算法原理及其实现
2.1 固定窗口
固定窗口就是定义一个固定的统计周期,比如10s,然后在每个周期内统计当前周期中被接收到的请求数量,经过计数器累加后,如果超过设定的阈值就触发限流,直到进入下一统计周期,计数器清零,重新统计
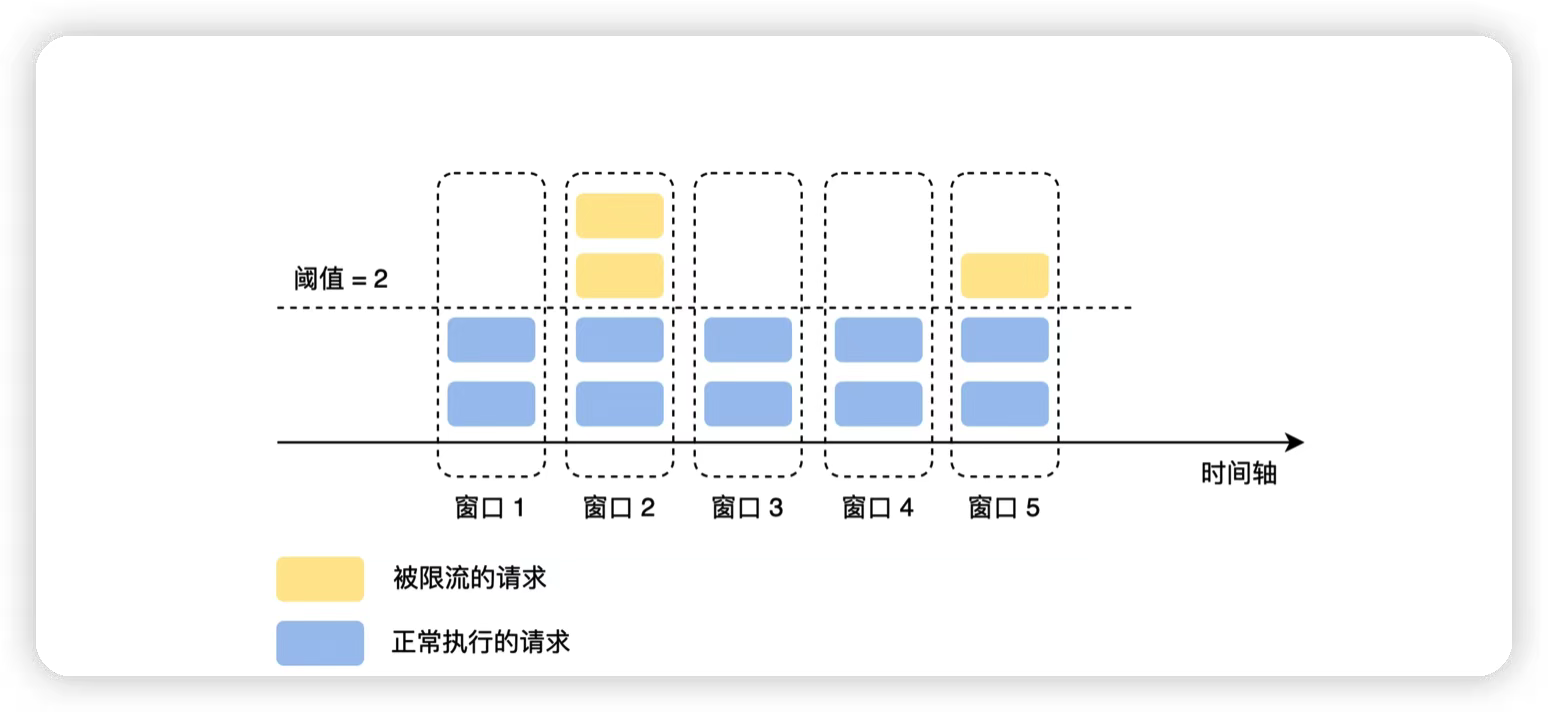
假设我们现在设置的是2s内不能超过100次请求,但是因为流量的进入往往都是不均匀的,所以固定窗口会存在以下两个问题:
- 抗抖动性差。由于流量突增使请求超过预期,导致流量可能在一个统计周期的前10ms内就达到了100次,给服务处理造成一定的压力,同时后面的1990ms内的请求都会被限流。如果尝试使用减小窗口值的方法来解决这个问题,那么对应的每个窗口的阈值也将会变小,一个小的流量抖动就可能导致限流,系统抗抖动性极差
- 如果上一个统计周期的流量集中在最后10ms,而这个统计周期集中在前10ms,那么在这个20ms内系统就有可能收到200次请求,这违背了我们2s不超过100次请求的目的
2.2 滑动窗口
滑动窗口就是固定窗口的优化,它对固定窗口做了进一步的切分,将统计周期的粒度切分的更细,比如1min的固定窗口,切分为60个1s的滑动窗口,然后统计的范围随着时间的推移而同步后移
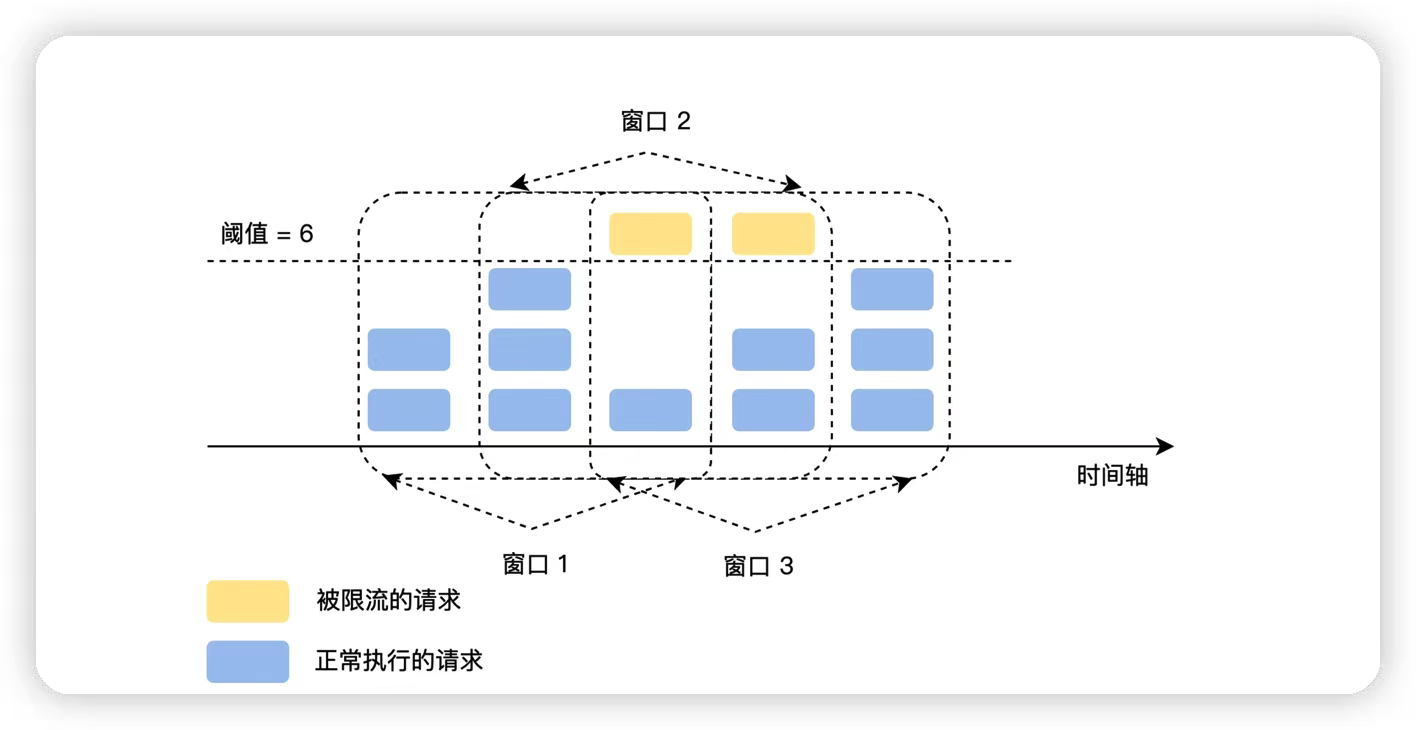
使用普通时间窗口时,我们会为每个user_id/ip维护一个KV: uidOrIp: timestamp_requestCount。假设限制1秒1000个请求,那么第100ms有一个请求,这个KV变成 uidOrIp: timestamp_1,递200ms有1个请求,我们先比较距离记录的timestamp有没有超过1s,如果没有只更新count,此时KV变成 uidOrIp: timestamp_2。当第1100ms来一个请求时,更新记录中的timestamp并重置计数,KV变成 uidOrIp: newtimestamp_1
普通时间窗口有一个问题,假设有500个请求集中在前1s的后100ms,500个请求集中在后1s的前100ms,其实在这200ms没就已经请求超限了,但是由于时间窗每经过1s就会重置计数,就无法识别到此时的请求超限。
对于滑动时间窗口,我们可以把1ms的时间窗口划分成10个time slot, 每个time slot统计某个100ms的请求数量。每经过100ms,有一个新的time slot加入窗口,早于当前时间100ms的time slot出窗口。窗口内最多维护10个time slot,储存空间的消耗同样是比较低的。
但是要注意的是,如果滑动窗口的统计窗口切分的过细,会增加系统性能和资源损耗的压力
同时,滑动窗口和固定窗口一样存在抗抖动性差的问题
golang实现滑动窗口限流:
var winMu map[string]*sync.RWMutex func init() { winMu = make(map[string]*sync.RWMutex) } type timeSlot struct { timestamp time.Time // 这个timeSlot的时间起点 count int // 落在这个timeSlot内的请求数 } func countReq(win []*timeSlot) int { var count int for _, ts := range win { count += ts.count } return count } type SlidingWindowLimiter struct { SlotDuration time.Duration // time slot的长度 WinDuration time.Duration // sliding window的长度 numSlots int // window内最多有多少个slot windows map[string][]*timeSlot maxReq int // win duration内允许的最大请求数 } func NewSliding(slotDuration time.Duration, winDuration time.Duration, maxReq int) *SlidingWindowLimiter { return &SlidingWindowLimiter{ SlotDuration: slotDuration, WinDuration: winDuration, numSlots: int(winDuration / slotDuration), windows: make(map[string][]*timeSlot), maxReq: maxReq, } } // 获取user_id/ip的时间窗口 func (l *SlidingWindowLimiter) getWindow(uidOrIp string) []*timeSlot { win, ok := l.windows[uidOrIp] if !ok { win = make([]*timeSlot, 0, l.numSlots) } return win } func (l *SlidingWindowLimiter) storeWindow(uidOrIp string, win []*timeSlot) { l.windows[uidOrIp] = win } func (l *SlidingWindowLimiter) validate(uidOrIp string) bool { // 同一user_id/ip并发安全 mu, ok := winMu[uidOrIp] if !ok { var m sync.RWMutex mu = &m winMu[uidOrIp] = mu } mu.Lock() defer mu.Unlock() win := l.getWindow(uidOrIp) now := time.Now() // 已经过期的time slot移出时间窗 timeoutOffset := -1 for i, ts := range win { if ts.timestamp.Add(l.WinDuration).After(now) { break } timeoutOffset = i } if timeoutOffset > -1 { win = win[timeoutOffset+1:] } // 判断请求是否超限 var result bool if countReq(win) < l.maxReq { result = true } // 记录这次的请求数 var lastSlot *timeSlot if len(win) > 0 { lastSlot = win[len(win)-1] if lastSlot.timestamp.Add(l.SlotDuration).Before(now) { lastSlot = &timeSlot{timestamp: now, count: 1} win = append(win, lastSlot) } else { lastSlot.count++ } } else { lastSlot = &timeSlot{timestamp: now, count: 1} win = append(win, lastSlot) } l.storeWindow(uidOrIp, win) return result } func (l *SlidingWindowLimiter) getUidOrIp() string { return "127.0.0.1" } func (l *SlidingWindowLimiter) IsLimited() bool { return !l.validate(l.getUidOrIp()) }
func main() { limiter := NewSliding(100*time.Millisecond, time.Second, 10) for i := 0; i < 5; i++ { fmt.Println(limiter.IsLimited()) } time.Sleep(100 * time.Millisecond) for i := 0; i < 5; i++ { fmt.Println(limiter.IsLimited()) } // 这个请求触发限流 fmt.Println(limiter.IsLimited()) for _, v := range limiter.windows[limiter.getUidOrIp()] { fmt.Println(v.timestamp, v.count) } fmt.Println("one thousand years later ...") time.Sleep(time.Second) for i := 0; i < 7; i++ { fmt.Println(limiter.IsLimited()) } for _, v := range limiter.windows[limiter.getUidOrIp()] { fmt.Println(v.timestamp, v.count) } }
2.3 漏桶
漏桶就像是一个漏斗,进来的水量就像访问流量一样,而出去的水量就像我们的系统处理请求一样
当访问量较大时,这个漏斗就会积水,如果水量太多就会溢出(抛弃请求)
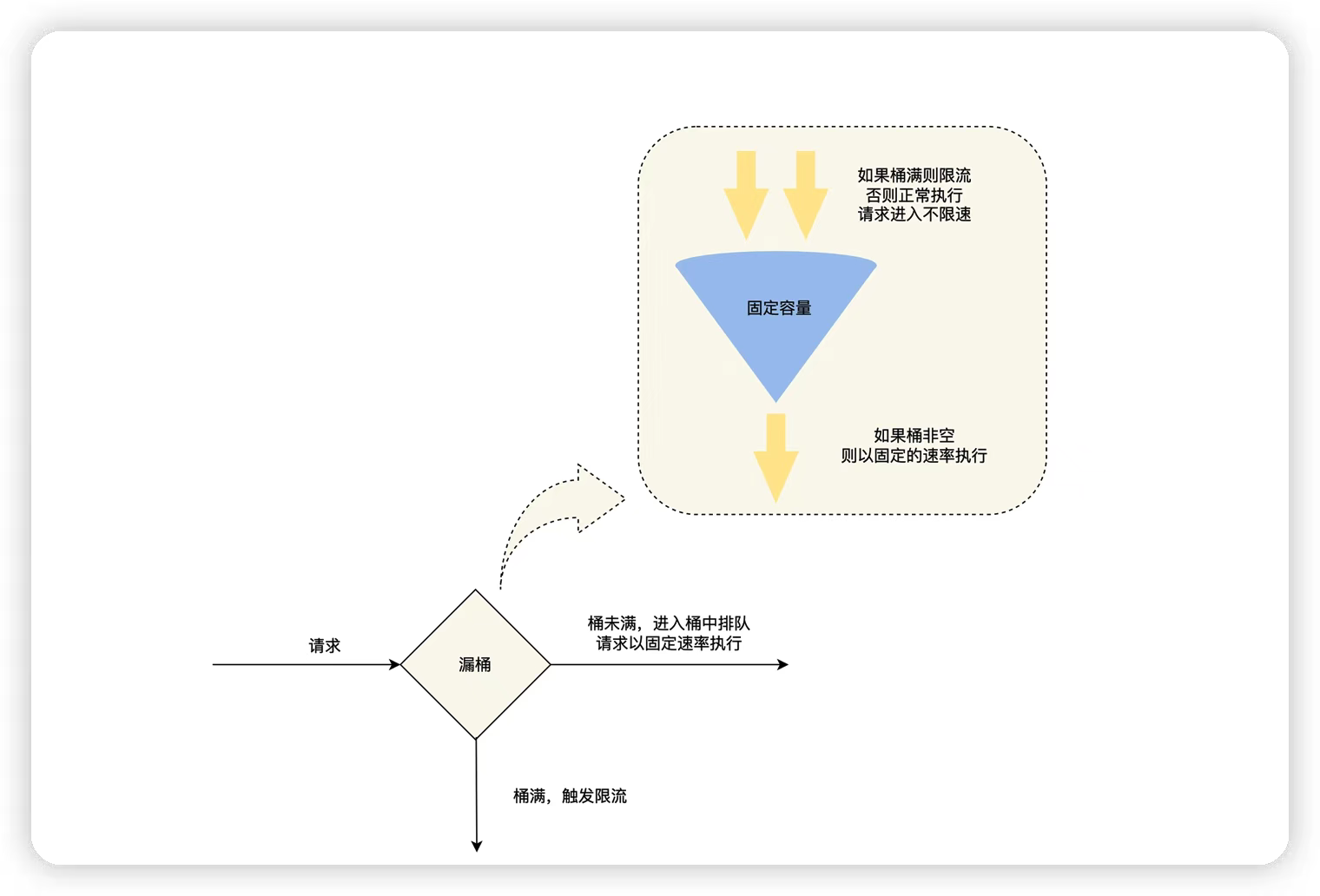
相对于滑动窗口来说,漏桶有两个改进点:
- 增加了一个桶来缓存请求,在流量突增时,可以先缓存起来,直到超过桶的容量才触发限流
- 对出口的流量上限做了限制,使上游流量的抖动不会扩散到下游服务
但是漏桶提供的流量整形能力有一定的代价,超过漏桶流出速率的请求,需要先在漏桶中排队等待
其中流出速率是漏桶限流的防线,一般会设置的相对保守,可是这样就无法完全利用系统的性能,增加了请求的排队时间
golang实现漏桶:
// Task 每个请求到来,需要把执行的业务逻辑封装成Task,放入漏桶,等待worker取出执行 type Task struct { handler func() Result // worker从漏桶取出请求对象后要执行的业务逻辑函数 resChan chan Result // 等待worker执行并返回结果的channel taskID int } // Result 封装业务逻辑的执行结果 type Result struct{} // handler 模拟封装业务逻辑的函数 func handler() Result { time.Sleep(300 * time.Millisecond) return Result{} } func NewTask(id int) Task { return Task{ handler: handler, resChan: make(chan Result), taskID: id, } } // 漏桶的具体实现 type LeakyBucket struct { BucketSize int // 漏桶大小 NumWorker int // 同时从漏桶中获取任务执行的worker数量 bucket chan Task // 存放任务的漏桶 } func NewLeakyBucket(bucketSize int, numWorker int) *LeakyBucket { return &LeakyBucket{ BucketSize: bucketSize, NumWorker: numWorker, bucket: make(chan Task, bucketSize), } } func (b *LeakyBucket) validate(task Task) bool { // 如果漏桶容量达到上限,返回false select { case b.bucket <- task: default: fmt.Printf("request[id=%d] is refused!\n", task.taskID) return false } // 等待worker执行 <-task.resChan fmt.Printf("request[id=%d] is running!\n", task.taskID) return true } func (b *LeakyBucket) Start() { // 开启worker从漏桶中获取任务并执行 go func() { for i := 0; i < b.NumWorker; i++ { go func() { for { task := <-b.bucket result := task.handler() task.resChan <- result } }() } }() }
func main() { bucket := NewLeakyBucket(10, 4) bucket.Start() var wg sync.WaitGroup for i := 0; i < 20; i++ { wg.Add(1) go func(id int) { defer wg.Done() task := NewTask(id) bucket.validate(task) }(i) } wg.Wait() }
2.4 令牌桶
令牌桶算法的核心是固定“进口”速率,限流器在一个一定容量的桶内,按照一定的速率放入Token,然后在处理程序在处理请求的时候,需要拿到Token才能处理
当大量流量进入时,只要令牌的生成速度大于等于请求被处理的速度,那么此时系统的处理能力就是极限的
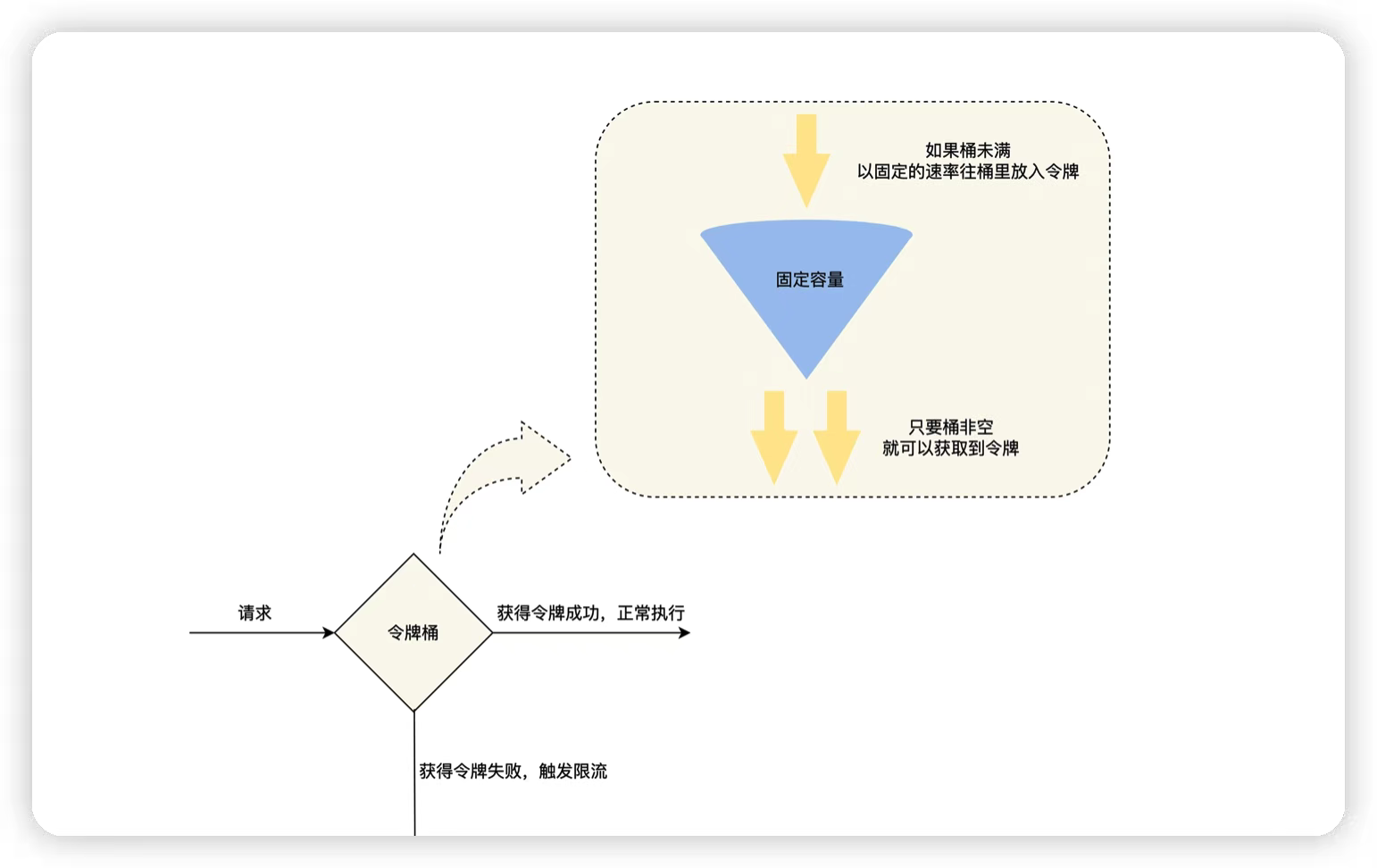
根据漏桶和令牌桶的特点,我们可以看到这两种算法都有一个恒定速率和一个可变速率:
- 令牌桶以恒定速率生产令牌,请求令牌的速率是可变的
- 漏桶以恒定速率处理请求,但是流入速率是可变的
我们可以看到,令牌桶相对于漏桶提升了系统利用率,减少请求排队时间,但是失去了一定的流量整形能力,使得上游抖动可能会扩散到下游服务
golang实现令牌桶:
// 并发访问同一个user_id/ip需要加锁 var recordMu map[string]*sync.RWMutex func init() { recordMu = make(map[string]*sync.RWMutex) } func max(a, b int) int { if a > b { return a } return b } // record 上次访问时的时间戳和令牌数 type record struct { last time.Time token int } // TokenBucket 令牌桶的具体实现 type TokenBucket struct { BucketSize int // 令牌桶的容量,最多可以存放多少个令牌 TokenRate time.Duration // 多长时间生成一个令牌 records map[string]*record // 报错user_id/ip的访问记录 } func NewTokenBucket(bucketSize int, tokenRate time.Duration) *TokenBucket { return &TokenBucket{ BucketSize: bucketSize, TokenRate: tokenRate, records: make(map[string]*record), } } // getUidOrIp 获取请求用户的user_id/ip func (t *TokenBucket) getUidOrIp() string { return "127.0.0.1" } // getRecord 获取这个user_id/ip上次访问的时间戳和令牌数 func (t *TokenBucket) getRecord(uidOrIp string) *record { if r, ok := t.records[uidOrIp]; ok { return r } return &record{} } func (t *TokenBucket) storeRecord(uidOrIp string, r *record) { t.records[uidOrIp] = r } func (t *TokenBucket) validate(uidOrIp string) bool { rl, ok := recordMu[uidOrIp] if !ok { var mu sync.RWMutex rl = &mu recordMu[uidOrIp] = rl } rl.Lock() defer rl.Unlock() r := t.getRecord(uidOrIp) now := time.Now() if r.last.IsZero() { // 第一次访问初始化为最大令牌数 r.last, r.token = now, t.BucketSize } else { if r.last.Add(t.TokenRate).Before(now) { // 如果与上一次请求隔了token rate // 增加令牌,更新last r.token += max(int(now.Sub(r.last)/t.TokenRate), t.BucketSize) r.last = now } } var result bool // 如果令牌数大于1,取走一个令牌,validate结果为true if r.token > 0 { r.token-- result = true } // 保存最新的record t.storeRecord(uidOrIp, r) return result } // IsLimited 是否被限流 func (t *TokenBucket) IsLimited() bool { return !t.validate(t.getUidOrIp()) }
func main() { tokenBucket := NewTokenBucket(5, 100*time.Millisecond) for i := 0; i < 6; i++ { fmt.Println(tokenBucket.IsLimited()) } time.Sleep(100 * time.Millisecond) fmt.Println(tokenBucket.IsLimited()) }
3. 分布式限流
我们上面讨论的几种限流算法在单机场景下都可以实现理想的限流效果,但是如果考虑分布式场景下,限流策略又需要什么改变呢?
让我们先来讨论一下单节点限流和分布式限流的区别,再针对分布式限流来分析几种限流方式
在单节点场景下,限流机制作用的位置是客户端还是服务端?
一般来说,熔断机制作用在客户端,限流机制更多在服务端,因为熔断更强调自适应能力,让作用点分布在客户端是没问题的,而限流机制更强调控制
如果将限流器作用在服务端,将会给服务端带来额外的压力,但是作用在客户端,这就是一个天然的分布式限流场景了
我们可以考虑的一个策略是,在客户端实现限流策略的底线,比如让一个客户端对一个接口的调用不能超过10000并发,这是一个正常情况下不可能达到的阈值,如果超过就进行客户端限流,避免客户端异常流量冲击服务端,进而在服务端实现精细粒度的限流功能
其次,在触发限流之后,我们应该抛弃请求还是阻塞等待?
一般来说,如果我们可以控制流量产生的速率,阻塞式限流就是一种更好的选择
如果我们无法控制流量产生的速率,大量请求积压造成系统资源不可用,那么否决式限流是更好的选择
对于在线业务来讲,否决式限流触发之后,用户会在客户端进行重试,所以不会对服务带来明显影响
对于想消息队列这种请求,为了避免打挂下游服务,通常都会对push进行限速处理,这时候我们就可以采用阻塞等待,同时自适应调节消息队列的限速水平
如何实现分布式限流?
最直观的一个想法是进行集中式限流。系统提供一个外部存储来做集中限流(令牌桶),但这会给分布式系统带来脆弱性:
- 外部存储成为性能瓶颈
- 限流器故障导致服务不可用
- 增加调用时延
另一个想法就是将分布式限流进行本地化处理。限流器在获得一个服务限额的总阈值之后,按照权重分配给不同的实例,但是这样最大的问题是没有一个合理的分配比例模型,因为这种限流策略不能动态变化,而导致某些实例在触发限流时可能会路由到其他实例,增大其处理压力
一个折中的方案是采用集中式限流的基础上,增加本地化处理。客户端只有在令牌数不足时,才会通过限流器获取令牌,而每次都会获取一批令牌。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)