Kubernetes学习记录(八):深入理解StatefulSet
1. StatefulSet为什么而生
在之前的Deployment中,已经可以看到这个控制器有多强大了,对于无状态应用可以做到滚动更新、回滚、扩容等一系列操作
但是对于有状态应用呢?
首先需要明确一个概念,什么是有状态应用?
有状态应用:实例之间有不对等关系、对实例外部数据有依赖关系的应用。最典型的就是mysql主从等一系列分布式集群
1.1 拓扑状态
应用的多个实例之间不是不是完全对等的,这些应用实例必须按照某种顺序启动
如果删除A和B两个pod,它们再次被创建出来时必须也按照同样的先后顺序
新创建出来的pod必须和原来pod网络标识一样,这样原先的访问者才可以使用同样的方式来访问这个新的pod
这个典型示例就是mysql主从节点的创建
1.2 存储状态
应用的多个实例分别绑定了不同的存储数据
假设pod A 第一次读取到的数据和隔了10分钟之后再次读取到的数据应该是同一份,不论其中间有没有被重新创建过
这种典型的例子就是数据库应用的多个存储实例,比如mysql的高可用
2. Headless Service
在之前已经说过了service这个概念,它定义了一组pod的访问规则,将pod暴露给外界
service有两种访问方式:
- VIP
- DNS
2.1 Service DNS
VIP的方式之前已经说过了,这里重点说一下DNS
比如,此时我只要访问 "my-svc.my-namespace.svc.cluster.local"这条DNS记录,就可以访问到名为 my-svc 的Service代理的某个Pod上
而在Service DNS下,又有两种处理方式:
- Normal DNS:访问"my-svc.my-namespace.svc.cluster.local"这条DNS记录,解析到的就是 my-svc 这个service的VIP,后面的流程就和VIP一致了
- Headless DNS:访问 "my-svc.my-namespace.svc.cluster.local" 解析到的直接就是my-svc代理的一个pod的ip地址
二者的区别在于 Headless 不需要分配一个VIP,而直接可以以DNS记录的方式解析出被代理的pod的IP地址

2.2 Headless Service
这是一个Headles Service对应的YAML文件:
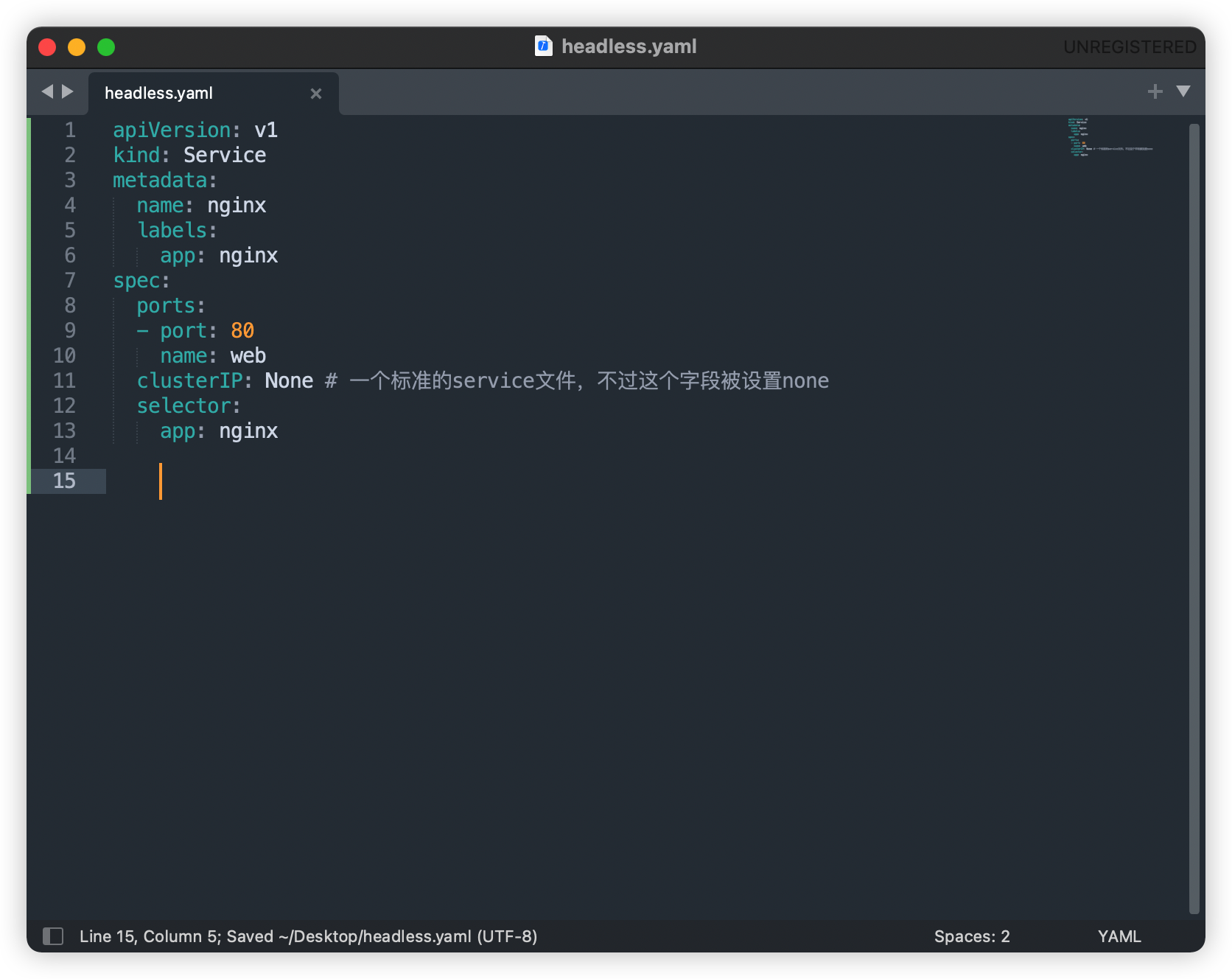
这个service没有一个VIP作为head,这就是headless的含义
当按照这样的方式创建一个headless service之后,它所代理的所有pod的p地址都会被绑定一个如下格式的DNS记录:
<pod-name>.<svc-name>.<namespace>.svc.cluster.local
这个DNS记录,正是k8s为pod分配的一个唯一的可解析身份,pod-name+svc-name+namespace保证了这个DNS记录的唯一性
3. 深入理解StatefulSet
3.1 拓扑状态
在拓扑状态下,pod之间有严格的创建顺序,并且要保证一个pod挂掉重启之后,其他pod仍能够按照之前的访问策略来访问这个pod
我们来编写一个StatefulSet的YAML文件:
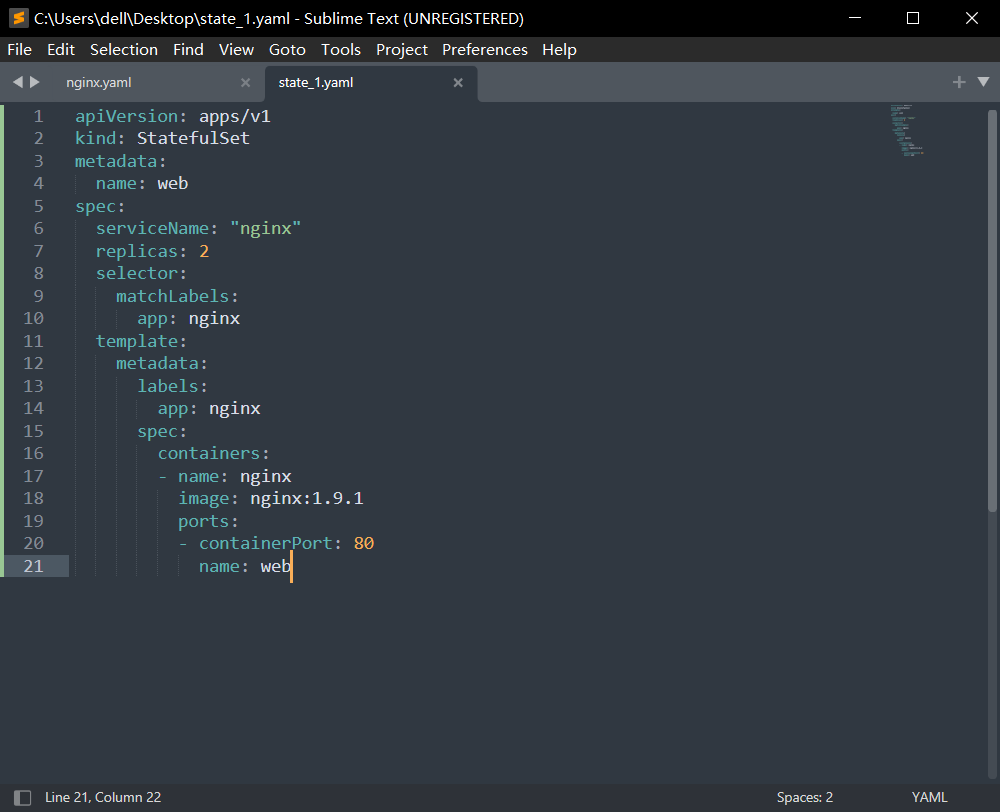
这个YAML文件与deployment的区别不大,只是可以明显的看到一个字段:serviceName: "nginx"
这个字段的作用就是告诉StatefulSet控制器,要是用nginx这个Headless Service
现在我们创建这个svc和statefulset
kubectl apply -f headless.yaml
kubectl apply -f state_1.yaml
那么statefulset的拓扑状态又是怎么保证的呢?
我们可以通过查看nginx pod创建的events,观察到statefulset控制器是怎么创建pod的
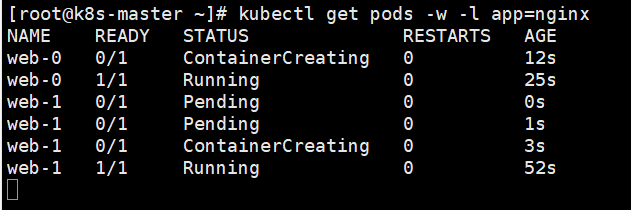
可以看到,我们创建了两个名为web的pod,statefulset为它们增加了一个明确的编号,而不是向deploy一样为其增加随机的编码
我们可以看到在web-0创建完毕ready之前,web-1是不会被创建的,这就是pod创建时的拓扑顺序
现在的问题是,DNS是如何访问的?
我们创建一个一次性的busybox pod,尝试通过nslookup命令来解析pod对应的Headless Service
kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
通过nslookup来访问web-0和web-1时,最后解析到的就是其对应的ip地址
如果我们删除这两个pod,并在另一个终端观察这一组pod的变化
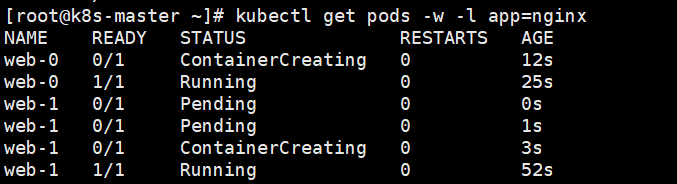
k8s在删除pod之后,按照原有的web-0和web-1标签重新按顺序创建了两个新的pod
如果我们此时再次使用nslookup访问这两个pod,会发现可以得到正确的结果,虽然新创建pod的IP地址与之前完全不同,但我们仍可以通过DNS来访问到正确的pod
通过使用DNS的方法,k8s就成功的将pod的拓扑状态记录了下来
而且DNS还为每个节点提供了一个唯一且固定的访问入口,其不会因为pod的IP地址变化而修改
尽管web-0.nginx这条记录本身不会变化,但其真正容器的IP地址是会变化的
所以对于有状态应用,必须使用DNS或者hostname的方式来访问,而不能直接使用IP地址
3.2 存储状态
PV和PVC为持久化存储提供了一种方式,控制器资源可以通过绑定PVC的方式来实现持久化
PV和PVC的设计类似于接口和实现的思想,开发者只需要使用PVC这个接口即可
StatefulSet保证存储状态最重要的一点就是每个pod有自己的存储单元,而不是像deployment那样多个pod数据同步到一个存储空间
最典型的就是etcd集群的部署,每个节点必须维护自己的存储空间
我们来看一个StatefulSet资源的YAML文件
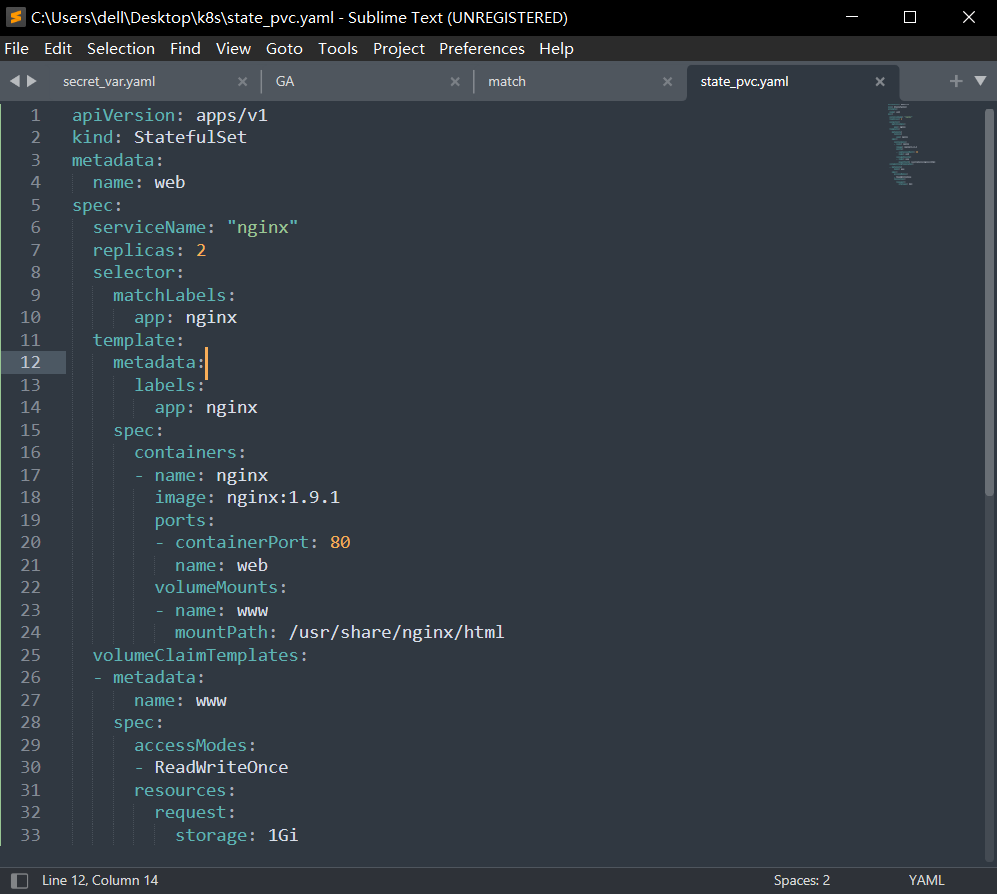
需要重点关注以下几个信息:
- 绑定了一个Headless Service "nginx",这是我们之前创建的
- 绑定一个名为www的volume,持久化容器内部 /usr/share/nginx/html
- 新增一个volumeClaimTemplates字段,StatefulSet的存储卷使用VolumeClaimTemplate创建,称为卷申请模板,只要是被StatefulSet管理的pod,都会声明一个对应的PVC。当StatefulSet使用VolumeClaimTemplate创建一个PersisteneVolume时,同样也会为每个pod分配并创建一个编号的PVC,这个PVC的编号与pod的编号完全一致
- PVC会绑定一个PV,这需要我们提前创建
这些和Pod绑定的PVC命名规则是什么?当我们回看之前的拓扑状态时,也许会从其中找到灵感
这些PVC的名称和DNS规则很类似,命名规则为如下形式:
<PVC name>-<StatefulSet name>-<编号>
在上面这个例子中,PVC的名字为 name: www,StatefulSet的名字为 name: web
所以相对应的两个PVC被命名为:
www-web-0
www-web-1
所以StatefulSet的存储状态是如何做到的?就是通过Pod-PVC-PV的方式实现绑定,完成Pod的独立存储
4. 总结
StatefulSet直接管理的是Pod
因为这里的Pod不像ReplicaSet中那样是一些 "副本" 资源,StatefulSet中的Pod有独立的hostname、编号、存储状态等
k8s通过Headless Service为这些带有编号的Pod在DNS服务器中生成带有编号的DNS记录
StatefulSet保证只要编号不发生变化,就可以通过DNS记录找到正确的Pod,不论Pod的IP地址是否变化
基于编号机制,StatefulSet为每个Pod提供了一个相同编号的PVC,保证了每个Pod都有独立的存储空间
StatefulSet资源的创建是k8s中最复杂的管理,虽然看起来Headless和PVC为我们提供了便利,但是要是真正部署一个分布式集群的困难还是比较大的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号