
Kubernetes学习记录(五):深入理解controller
1. Contriller简介
1.1 什么是控制器
- controllers:在集群上管理和运行容器对象
- 通过label-selectors关联
- Pod通过控制器实现应用的运维,如伸缩和回滚
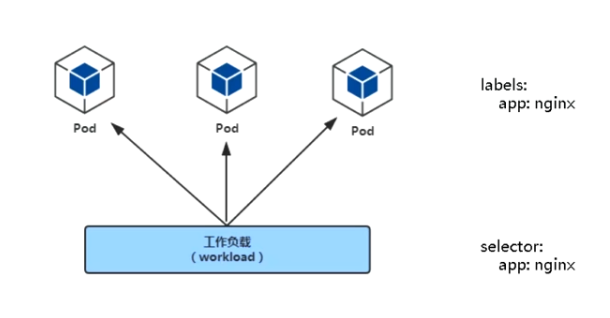
k8s中常见的控制器主要有:
- deployment
- job
- cronjob
- daemon
- statefulset
1.2 控制器思想
目录下所有的控制器都遵循一个通用的编排模式——控制循环
比如,现在有一个待编排的对象x,它有一个对应的控制器,那么我们就可以用一段伪代码来描述这个控制循环:
for { 实际状态 := 获取集群中对象x的实际状态 期待状态 := 获取集群中对象x的期待状态 if 实际状态 == 期待状态{ nothing } else { 执行编排动作,将实际状态调整为期待状态 } }
实际状态往往来自于k8s集群本身,比如kubelet的心跳信息和节点状态、监控数据等
期望状态就是用户提交的yaml文件,比如replicas=3,就是一种期待状态,控制器要保证实际状态向期待状态转变
这篇博客不会介绍StatefulSet,后续会单独开一个博客,结合官网的部署案例详细介绍这个k8s项目中最复杂的编排对象
2. Deployment
2.1 Deployment功能
- 部署无状态应用
- 管理Pod和ReplicaSet
- 具有上线部署、副本设定、滚动更新、回滚等功能
- 提供声明式更新,例如只更新一个新的image
应用场景:web服务、微服务
2.2 深入理解deployment
比如我们现在有一个deployment控制器,其中的replicas字段为3
这个deployment控制器就可以保证一个最基本的事实:我们需要携带app:nginx标签的Pod数量永远等于3
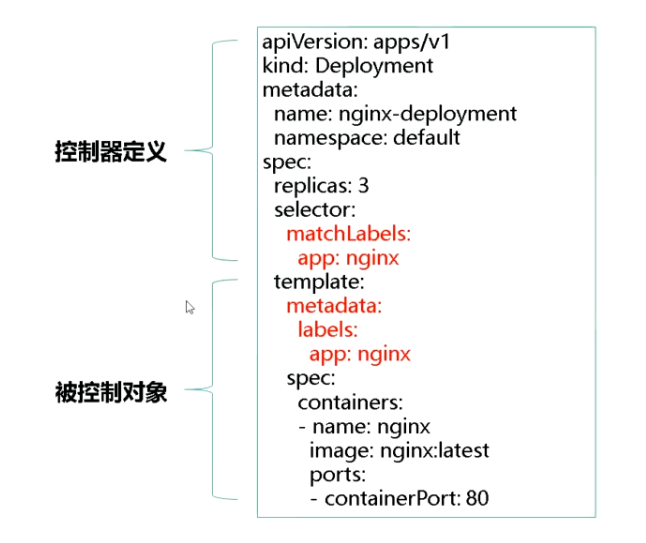
deployment是如何保证实际状态和期望状态相同呢?
- deployment控制器从etcd中获取所有携带app:nginx标签的Pod,然后统计它们的数量,这就是实际状态
- deployment控制器对象的replicas字段就是期望状态
- deployment控制器比较两个状态,然后根据结果选择创建pod还是删除pod
关于deployment控制器非常重要的一点是:deployment操纵的是ReplicaSet对象,而不是Pod对象
所以对于deployment管理的pod,它的ownerReference是ReplicaSet
似乎看起来deployment、replicaset、pod之间的关系非常混乱,其实三者的关系关系到了扩容、更新和回滚的操作
我们首先来模拟一下滚动升级的实现,比如现在我要把nginx版本降为1.7.9,如何修改?
k8s主要是提供了两种修改方式:
- 修改YAML文件之后,apply
- 直接使用edit指令编辑etcd中的API对象,保存后自动apply
现在我们使用edit将nginx版本修改为1.7.9
kubectl edit deployment/nginx
其实edit看似方便,它和我们自己修改YAML然后apply是一样的流程,只不过是合并在一起了
现在我们处于第二个版本

那么ReplicaSet在其中扮演什么角色?似乎我们看不到它的身影
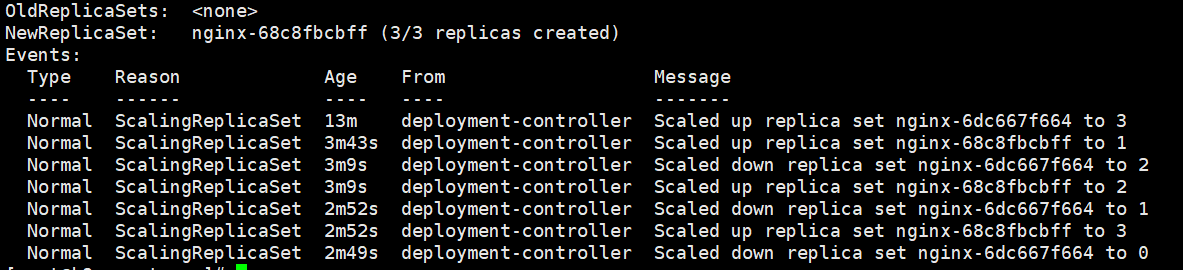
我们打开滚动升级的events,可以看到是存在两个ReplicaSet的,分别为:
replica set nginx-6dc667f664 就是第一个版本的rs
replica set nginx-68c8fbcbff 第二个版本的rs
通过events可以看到rs是如何控制pod数量的,新版本首先创建出pod资源,然后旧版本再慢慢退出旧的Pod,就这样完成了滚动更新
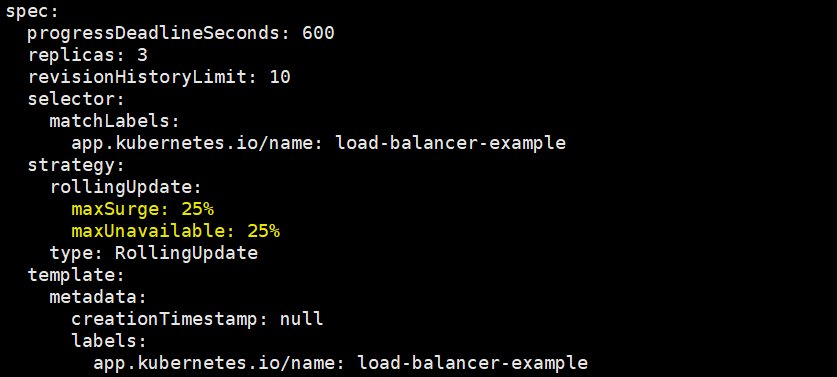
值得一提的是,在这个deployment中有3个pod副本,它会默认在滚动更新时至少确保2个pod处于可用状态,至多有4个pod同时存在于集群中
我们在编写资源文件时并没有指明这一点,可以通过kubectl edit看到
如果我们现在再做一次扩容操作,将nginx副本数量升级为4个
在查看events时就会发现第二个版本的rs被扩容到了4个副本
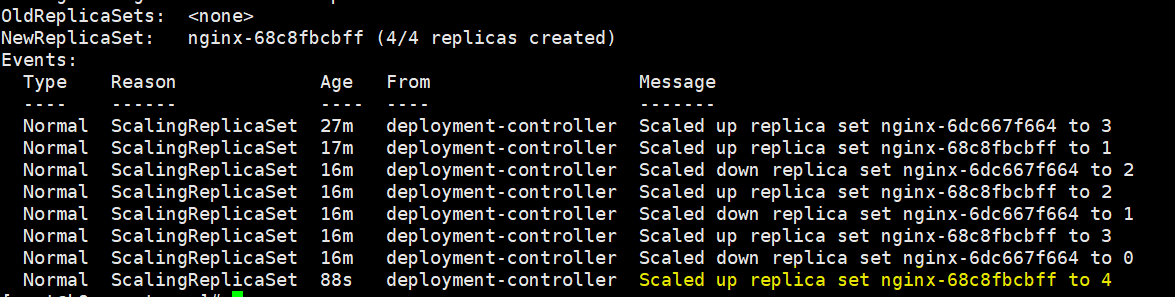
如果此时我们回滚到第一个版本,会发生什么?
最明显的一个区别就是,我们的回滚操作是非常快的,是要比升级快,而其次我们会发现其实现在我们处于第三个版本,但仍然是第一个版本的ReplicaSet
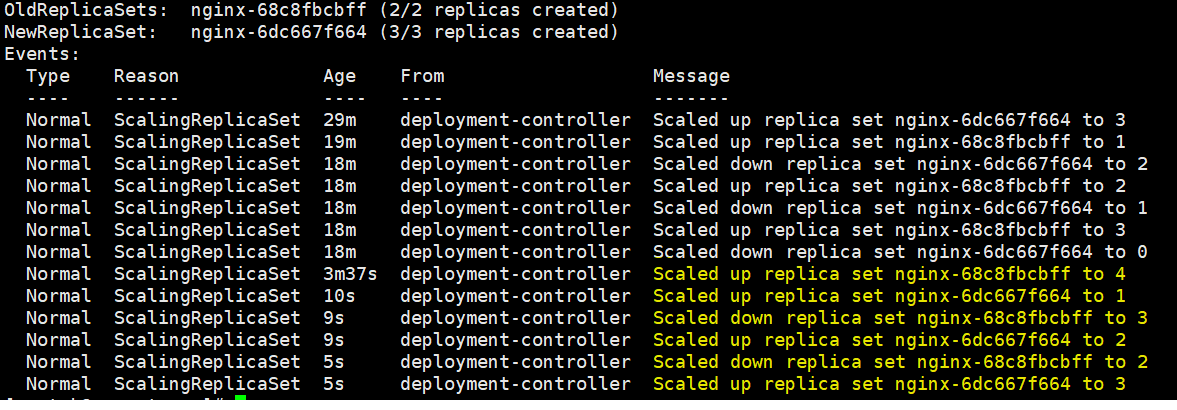
所以我们从中窥探出deployment、replicaset和pod之间的关系了
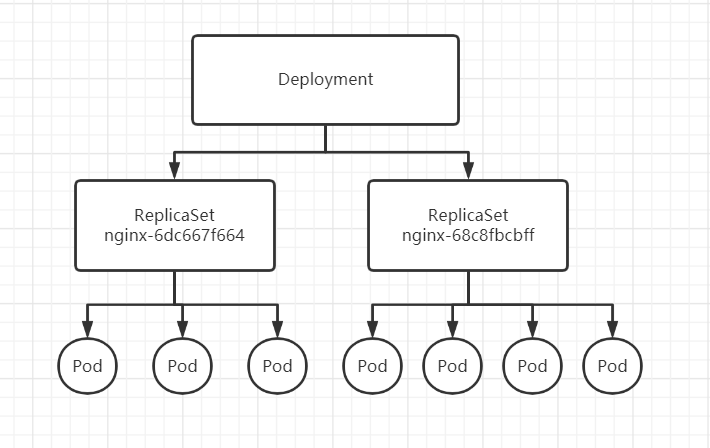
deployment控制器实际上控制的是ReplicaSet的数目,以及每个ReplicaSet的属性
一个应用的版本对应的正是一个ReplicaSet,这个版本应用的Pod数量由ReplicaSet通过它自己的控制器来保证
通过这样的多ReplicaSet对象设计,k8s实现了多个应用版本的快速更新回滚
在k8s中,我们可以通过修改deployment对象的spec.revisionHistoryLimit字段来决定想保留的历史版本的个数,不在历史版本中是不支持回滚的
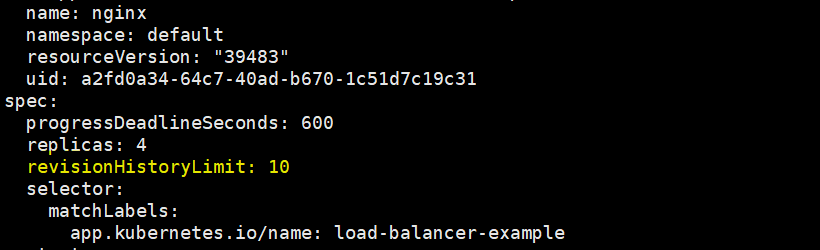
而且这个历史版本是不相同的历史版本,比如像我之前的操作,虽然名义上进入了版本3,但查看历史版本列表只能看到两个版本,因为第一个版本和第三个版本是一样的
3. DaemonSet
3.1 DaemonSet功能
- 在每一个Node上运行一个Pod
- 新加入的Node也会自动运行同一个Pod
应用场景:Agent(监控、IP下发、日志服务等)
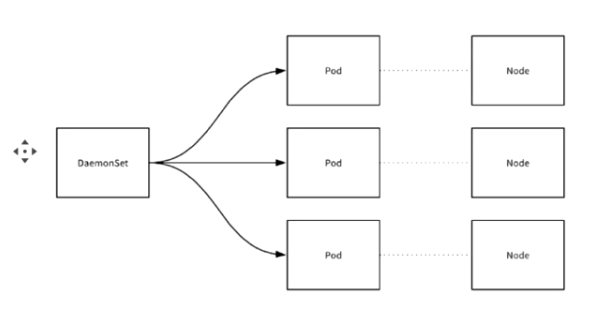
在部署k8s时,就已经部署了DaemonSet了,这三个网络服务就是ds
3.2 深入理解DaemonSet
首先我们可以查看官网上提供的一个DaemonSet YAML示例
编写方式和deplyment控制器大同小异,我们给这个控制器做污点容忍,从而让其可以在master节点上部署
apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-elasticsearch namespace: kube-system labels: k8s-app: fluentd-logging spec: selector: matchLabels: name: fluentd-elasticsearch updateStrategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 template: metadata: labels: name: fluentd-elasticsearch spec: tolerations: # this toleration is to have the daemonset runnable on master nodes # remove it if your masters can't run pods - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd-elasticsearch image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2 volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers
DaemonSet最重要的一个功能就是保证每个节点上有且只有一个pod在运行,那么是如何保证的?
DaemonSet从etcd中获取所有节点列表,然后遍历所有节点,这时就可以去检查节点是否有一个携带了 name: fluentd-elasticsearch 标签的pod在运行
检查的结果有三种情况:
(1)没有这个pod,这意味着需要在这个节点上创建一个Pod
(2)有这种pod,但是数量大于1,这意味着要删除多余的pod
(3)正好有一个pod,这就是正常的状态
需要注意的是,在DaemonSet上一般应该加上resources字段,来限制它的CPU和内存使用,防止占用过多的宿主机资源
Daemon也可以像Deployment那样进行版本管理,但是有一个疑问:Deployment版本控制是通过ReplicaSet实现的,而Daemon直接操作Pod,如何实现版本控制?
k8s中有一个API对象:ControllerRevision,专门用来记录某种Controller对象的版本,可以通过以下指令查看
kubectl get controllerrevision -n kube-system -l name=fluented-elasticsearch
尝试回滚DaemonSet到第一个版本
kubectl rollout undo daemonset fluented-elasticsearch --to-revision=1 -n kube-system
这个回滚操作其实就相当于读取了Revision=1的ControllerRevision对象保存的Data字段,而Data字段就保存了Revision=1时这个DaemonSet的完整API对象
相比于Deployment而言,DaemonSet更简单一些,其主要的特点有以下几点:
- 操作的是Pod
- 通过nodeAffinity和Toleration两个调度功能来完成调度
- 使用ControllerRevision做版本控制
4. Job
主要用于离线数据处理,一次性执行
记得在一次性任务中设置重启策略为Never,实际上在Job中,重启策略只允许设置为Never和OnFailure
在下面这个一次性任务中,我们的目的是计算一个圆周率,并打印到控制台日志,并且允许失败重试4次

在离线任务中,有一个很重要的概念就是Batch Job,当然就是它们可以以并行的方式运行
在Job对象中,负责并行控制的参数有两个:
- spec.parallelism:定义的是一个Job在任意时间最多可以启动多少个Pod同时运行
- spec.completions:定义的是Job至少需要完成的Pod数量,即Job的最小完成数
5. CronJob
垃圾缓存清理,推数据,自动备份等,定时执行
在下面这个YAML文件中,我们可以看到一个之前未出现过的关键字:jobTemplate
也就是说,CronJob是一个Job对象的控制器,通过schedule字段定义的cron表达式来控制Job的执行,保证每个执行周期执行一次Job
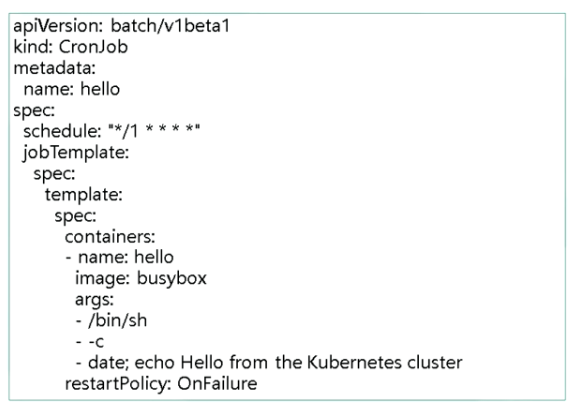
另外,由于定时任务的特殊性,可能存在的情况是一个job还没有执行完,另一个新的job就产生了
这时可以通过spce.concurrencyPolicy字段来定义具体的处理策略:
- concurrencyPolicy = Allow:默认设置,未结束的和新起的Job可以共存
- concurrencyPolicy = Forbid:意味着不会创建新的pod,这个调度周期被跳过
- concurrencyPolicy = Replace:新产生的Job代替未结束的Job
如果某一次Job创建失败,这次创建就会被标记为 miss ,当在指定时间窗口大小内 miss 的次数达到100次,CronJob就会停止创建这个Job
时间窗口可以由 spec.startingDeadlineSeconds字段指定,比如startingDeadlineSeconds = 200,这意味着如果在过去200秒内miss数目达到了100,这个CronJob就不会创建Job了
参考:
K8s -- Deployment - 简书 (jianshu.com)
Kubernetes笔记(六):了解控制器 —— Deployment - 【雨歌】 - 博客园 (cnblogs.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理