
Kubernetes学习记录(四):深入理解Pod
1. 什么是Pod
1.1 Pod的基本概念
Pod就是一组共享了某些资源的容器
Pod的设计是为了亲密性应用可以共享存储和网络而设计
什么是亲密性应用场景:
- 两个应用之间发生文件交互
- 两个应用需要通过127.0.0.1或者socket通信
- 两个应用需要发生频繁调用
1.2 pod的实现机制和设计模式
共享网络
容器实现了namesapce隔离,那么pod是怎么打破这种隔离的?
实际上,在k8s中,pod的实现需要一个中间容器,这个容器叫做Infra容器
在一个pod中,Infra容器永远都是第一个被创建的容器,用户定义的其它容器则通过JoinNetworkNamespace的方式与Infra关联在一起
我们可以在node节点中找到这个容器,就是pause容器

在一个pod中共享网络,这意味着对于pod中的两个容器来说:
- 它们可以使用localhost进行通信
- 它们看到的网络设备和Infra容器看到的完全一样
- 一个pod只有一个IP地址,也就是这个pod的Network Namespace对应的地址
- Pod的生命周期和Infra容器一致,而与其他业务容器无关
共享存储
pod使用数据卷的方式实现数据共享,k8s只需要把所有的volume定义在pod层级即可
这样,一个volume对应的宿主机目录对于pod来说就只有一个,pod内容器只需要声明挂载这个volume,就可以实现数据共享
我们可以在一个具体的YAML文件中观察到这一点
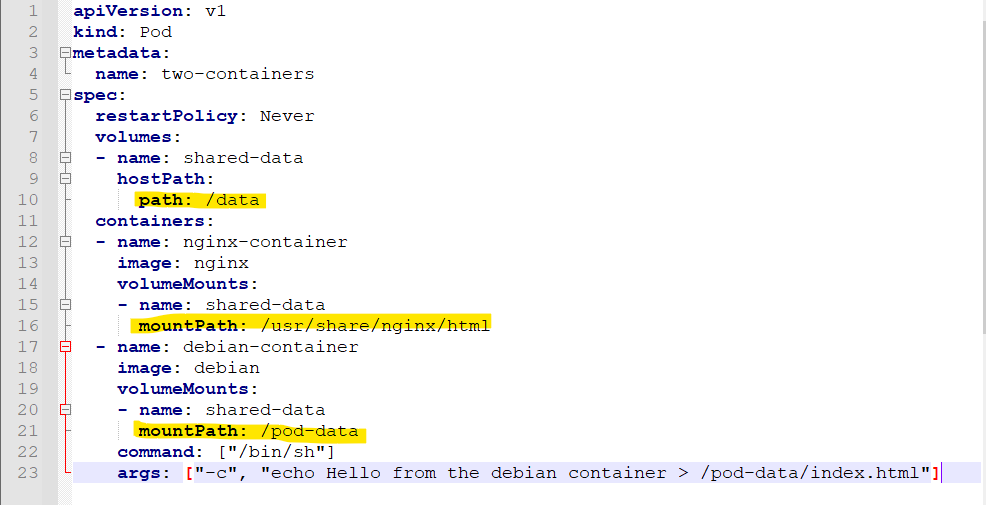
在这个例子中,debian和nginx都声明挂载了shared-data这个数据卷,而shared-data是hostPath类型,所以它在宿主机上对应的目录就是 /data
从而nginx可以在它的/usr/share/nginx/html目录中读取到debian生成的index.html文件
1.3 Pod的状态
Pod的生命周期主要体现在Pod API对象的Status部分,这是它除了Metadata和Spec外的第三个重要字段
其中pod.status.phase就是Pod当前的状态,它有下面五种可能的情况:
- Pending
这个状态意味着Pod的YAML文件已经提交给了k8s,API对象已经被创建并保存到etcd中
但是,这个Pod里有些容器可能因为某种原因不能够被顺序创建,比如无法调度
- Running
这个状态下,Pod已经被调度成功,跟一个具体节点绑定
它包含的容器都已经被创建,并且至少有一个在正在运行
- Succeeded
Pod里所有的容器都运行完毕,并且成功退出,常见于一次性任务
- Failed
Pod里至少有一个容器以不正常的状态退出,遇到这个状态需要查看events
- Unknown
异常状态,意味着kubelet不能上报情况,可能是master和node之间的通信出问题
2. Pod的调度策略
k8s的调度策略分为两个部分:predicates预选策略和priorites优选策略
- 预选策略:predicates是强制性规则,遍历所有的node节点,按照具体的预选策略筛选出所有符合要求的node,如果没有node符合要求,pod将会被挂起
- 优选择略:在预选的基础之上,按照优选策略为待选的node打分,获取更优者部署pod
预选策略必须全部满足
(1)CheckNodeCondition:检测node是否正常
(2)GeneralPredicates:普通判断策略
HostName: 检测pod对象是否定义了pod.spec.hostname
PodFitsHostPorts:检测pods.spec.containets.ports.hostPort是否定义
MatchNodeSelector:检测pod是否设置了pods.spec.nodeSelector
PodFitsResources:检测pod的资源需求是否能被节点所满足
(3)NoDiskConflict:检测pod依赖的存储卷是否能满足需求
(4)PodToleratesNodeTaints: 检测pod上的spec.tolerations可容忍的污点是否完全包含节点上的污点
(5)PodToleratesNodeNoExecuteTaints: 检测pod上是否启用了NoExecute级别的污点
(6)CheckNodeLabelPresence: 检测node上的标签的存在与否
(7)CheckServiceAffinity:将相同service pod的对象放到一起
(8)CheckVolumeBinding:检测节点上已绑定和未绑定的volume
(9)NoVolumeZoneConflict:检测区域,是否有pod volume的冲突
(10)CheckNodeMemoryPressure:检测内存节点是否存在压力
(11)CheckNodePIDPressure:检测pid资源的情况
(12)CheckNodeDiskPressure:检测disk资源压力
(13)MatchInterPodAffity:检测pod的亲和性
优选择略
优选函数的评估:如果一个pod过来,会根据启用的全部函数的得分相加得到评估
(1)LeastRequested:最少请求,与节点的总容量的比值
(2)BalancedResourceAllocation:cpu和内存资源被占用的比率相近程度,越接近,比分越高,平衡节点的资源使用情况
(3)NodePreferAvoidPods:在这个优先级中,优先级最高,得分非常高
(4)TaintToleration:将pod对象的spec.tolertions与节点的taints列表项进行匹配度检测,匹配的条目越多,得分越低
(5)SeletorSpreading:尽可能的把pod分散开,也就是没有启动这个pod的node,得分会越高
(6)InterPodAffinity:遍历pod的亲和性,匹配项越多,得分就越多
(7)NodeAffinity:节点亲和性,亲和性高,得分高
(8)MostRequested:空闲量越少的,得分越高,与LeastRequested不能同时使用,集中一个机器上面跑pod
(9)NodeLabel:根据node上面的标签来评估得分,有标签就有分,没有标签就没有分
(10)ImageLocality:一个node的得分高低,是根据node上面是否有镜像,有镜像就有得分,反之没有。根据node上已有满足需求的image的size的大小之和来计算
2.1 镜像拉取策略
在创建pod时,有三种不同的镜像拉取策略
- IfNotPresent:默认值,镜像在宿主机上不存在时才会拉取
- Always:每次创建pod时都会重新拉取镜像
- Never:Pod永远不会主动拉取这个镜像
关于拉取策略的使用,可以在YAML文件中看到其使用的位置

上面也同样展示了关于一些需要认证的私有仓库,应该怎么加认证去访问,这个和secret有关
2.2 资源限制
Pod和Container的资源请求和限制:
- spec.containers[].resources.limits.cpu:实际使用最大CPU配额
- spec.containers[].resources.limits.memory:实际使用最大内存配额
- spec.containers[].resources.requests.cpu:调度时请求的CPU配额参考
- spec.containers[].resources.requests.memory:调度时请求的内存配额参考

资源限制有什么用处?
最重要的一点就是避免某个容器资源利用率异常突发影响其它容器,从而造成雪崩
2.3 重启策略
pod中的容器有三种重启策略:
- Always:默认策略,当容器终止退出后,总是重启
- OnFailure:当容器异常退出(退出状态码非0)时,才会重启容器
- Never:当容器终止退出时,从不重启容器

2.4 健康检查
Probe有以下两种类型:
- livenessProbe(存活检查):如果检查失败,将杀死容器,根据重启策略来决定是否重启
- readinessProbe(就绪检查):如果检查失败,k8s会将Pod从service endpoints中删除
Probe支持以下三种检查方法:
- httpGet:发送HTTP请求,返回200-400范围状态码为成功
- exec:执行shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
比如在下面这个Pod中,健康检查的机制就是通过在Pod内创建一个healthy文件的方式来进行健康检查
因为sleep了30s后删除了文件,所以会执行重启Pod
同样可以通过生成一个PID或者UUID来检查

我们可以观察到liveness测试Pod已经重启了一次,说明其因为没有通过健康检查而重启

通过 kubectl describe pod liveness-exec 查看这个容器的Events
可以发现其就是因为没有通过健康检查而重启的,因为healthy文件被删除了,cat时返回非0状态码

2.5 标签选择器
为node设置标签,让pod调度到指定标签的node上
为节点打标签
kubectl label nodes [node] key=value
为节点删除标签
kubectl label nodes [node] key-
在YAML中使用节点选择器选择对应标签的节点即可
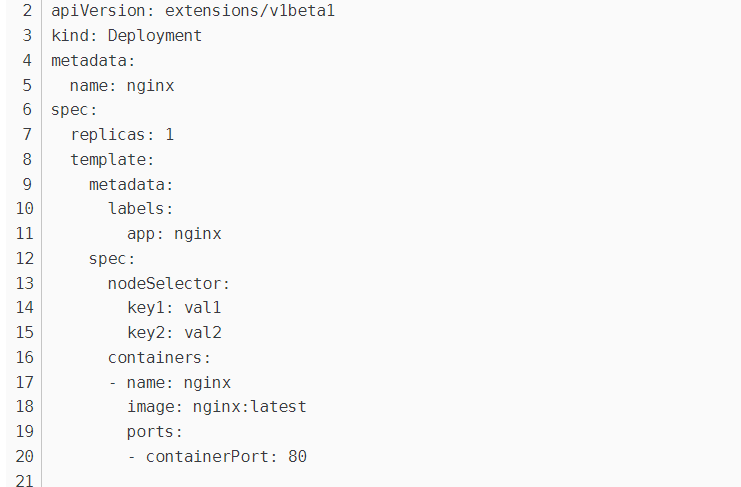
2.7 节点亲和性
节点亲和性用于替换节点标签选择器,有两种亲和性表达:
- RequiredDuringSchedulingIgnoredDuringExecution:硬限制,必须满足条件
- PreferrefDuringSchedulingIgnoredDuringExecution:软限制,可以按权重优先

2.8 污点和污点容忍
首先区分一下污点是node的污点,污点容忍是pod对node上污点的容忍程度
关于污点,常见的污点应用场景为节点独占或者有特殊硬件的节点
给一个node设置污点:
kubectl taint node [node] key=valie[effect]
删除污点:
kubectl taint node [node] key:[effect]-
其中[effect]可取值:
- NoSchedule:不可能被调度,比如master节点在初始化时已经被打上不可调度标签
- PreferNoSchedule:尽量不要被调度
- NoExecute:不仅不会被调度,还会驱逐Node上已有的Pod
污点容忍是在构建Pod时,YAML文件中的一个字段
比如下面这个Pod,它可以忍受NoSchedule污点的node

3. Pod的创建
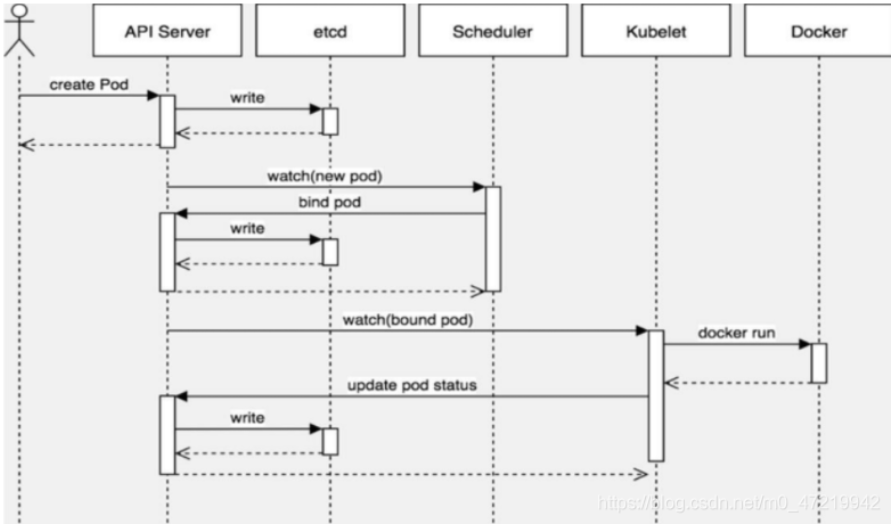
- 用户创建pod的信息通过API Server存储到etcd中,etcd记录pod的元信息并将结果返回给API Server
- API Server告知调度器请求资源调度,调度器通过调度算法计算,将优先级高的node与pod绑定并告知API Server
- API Server将此信息写入etcd,得到etcd回复后调用kubelet创建pod
- kubelet使用docker run创建pod内容器,得到反馈后将此信息告知API Server
- API Server将收到的信息写入etcd
- kubectl get pods 可以查到pod信息了
参考:
【Kubernetes】Pod学习(八)Pod调度:定向调度与亲和性调度_刺眼的宝石蓝的博客-CSDN博客
pod调度策略,一篇就够_Mr-Liuqx的博客-CSDN博客_pod调度策略
kube-scheduler :调度 Pod 流程-江哥架构师笔记 (andblog.cn)
干货!K8S之pod创建流程+调度约束_时光慢旅的博客-CSDN博客_k8s创建pod的详细过程
这应该是最全的K8s-Pod调度策略了 - 云+社区 - 腾讯云 (tencent.com)
k8s之pod调度 - 路过的柚子厨 - 博客园 (cnblogs.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理