Drain算法-笔记
简介
论文链接:https://jiemingzhu.github.io/pub/pjhe_icws2017.pdf
代码实现:https://github.com/logpai/logparser/tree/main/logparser/Drain
算法原理图:
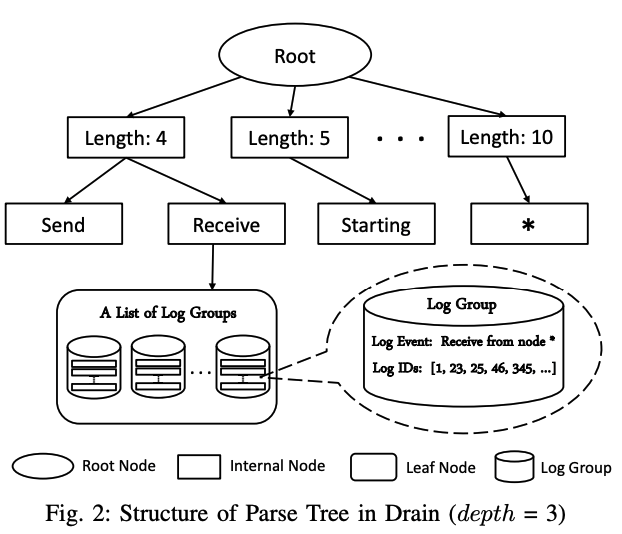
有几点注意:
- 根节点和叶节点实际是一套规则,并不包含日志数据
- 真正的日志数据在叶节点之下的Log Group
- 第一层节点,基于假设: 具有相同日志事件的日志消息可能具有相同的日志消息长度
- 第二层节点,基于假设: 日志消息开始位置的token更有可能是常量
Leaf Node 的计算
计算日志消息和每个日志组的日志事件之间的序列相似性:
\[\mathrm{sinSeq}=\frac{\sum_{\mathrm{i}=1}^\mathrm{n}\mathrm{equ}(\mathrm{seq}_1(\mathrm{i}),\mathrm{seq}_2(\mathrm{i}))}{\mathrm{n}}
\]
seq分别是同一组内,两个日志的序列(以空格划分的字符串数组):
\[\text{equ}(\mathrm t_1 ,\mathrm t_2 )=\begin{cases}1&\text{if} \mathrm t_1 ==\mathrm t_2\\0&\text{otherwise}\end{cases}
\]
如果stsimSeq≥st(阈值),那么Drain就会返回该组作为最佳匹配,否则返回一个标志位表示没有合适的。
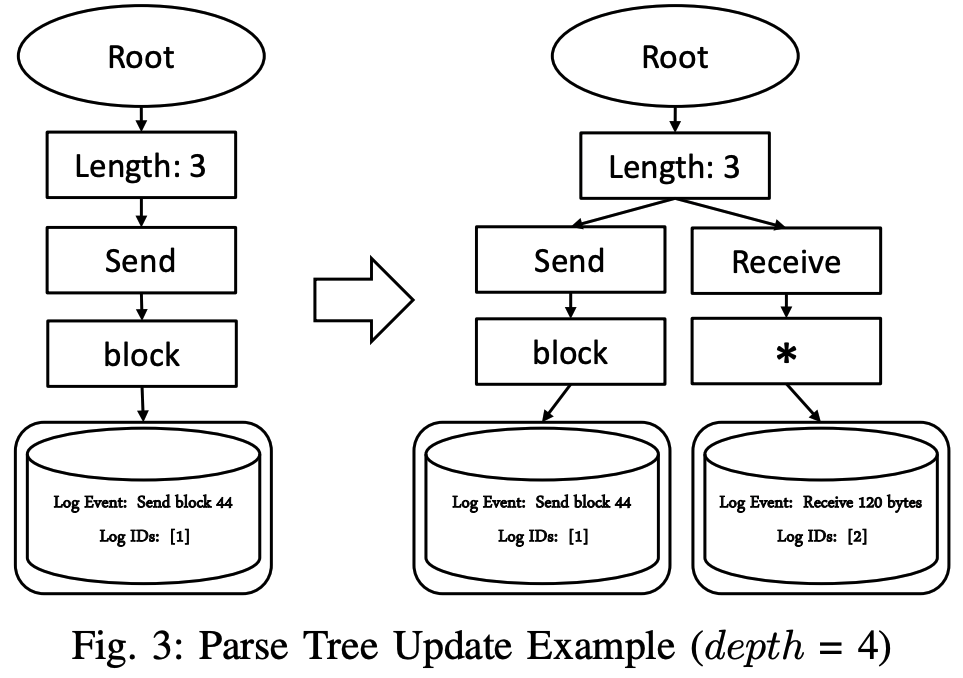
更新解析树
如果在返回了合适的日志组,则Drain将当前日志消息的日志ID添加到返回的日志组中的日志ID中。此外,将更新返回日志组中的日志事件。
扫描日志消息和日志事件相同位置的token,如果两个token相同,则不修改该token位置上的token。否则,在日志事件中通过通配符*更新该token位置上的token。
如果无法找到合适的日志组,则根据当前日志消息创建一个新的日志组。
本文来自博客园,作者:漫漫长夜何时休,转载请注明原文链接:https://www.cnblogs.com/ag-chen/p/18441976

 浙公网安备 33010602011771号
浙公网安备 33010602011771号