Transformer笔记
整体结构
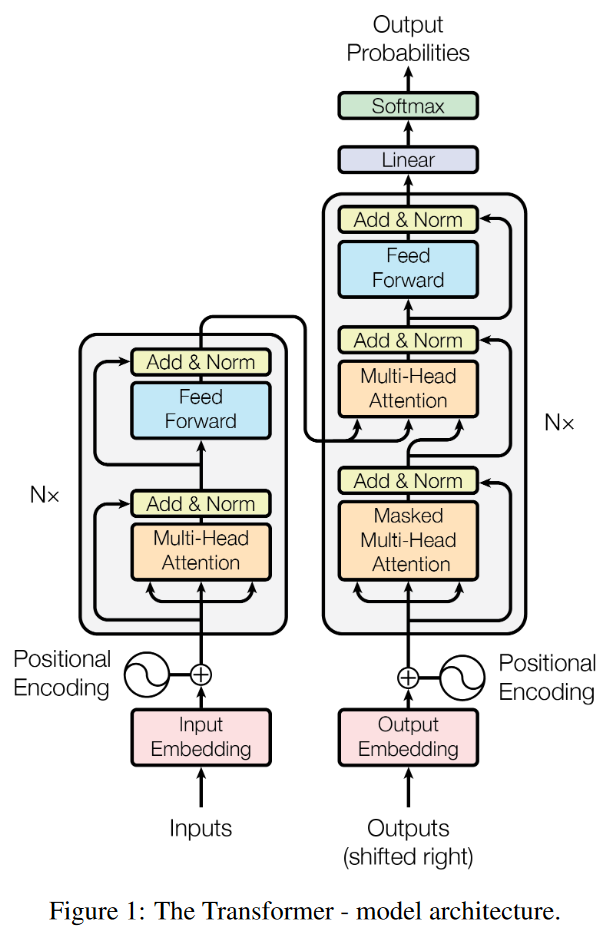
注意: 原始论文中的 自注意力 和 多头注意力的 Q, K, V矩阵的位置是不一样的

自注意力

初始的Q, K, V矩阵都是一样的数据: 文本的embedding矩阵, 只是通过了不同的Linear处理.
- Self-Attention的作用:捕捉序列内部各个元素之间的依赖关系,无论它们之间的距离有多远。比如在一个句子中,两个词可能离得很远,但它们的关联性很强,这时候自注意力就能捕捉到这种长距离依赖,而传统的RNN或者LSTM可能因为序列过长而遗忘前面的信息。
- 计算注意力分数,通常是Query和Key的点积,再除以一个缩放因子(比如键向量维度的平方根),这样可以避免点积过大导致梯度消失的问题。接着,应用Softmax函数得到权重,最后用这些权重对Value向量进行加权求和,得到自注意力的输出。
多头注意力

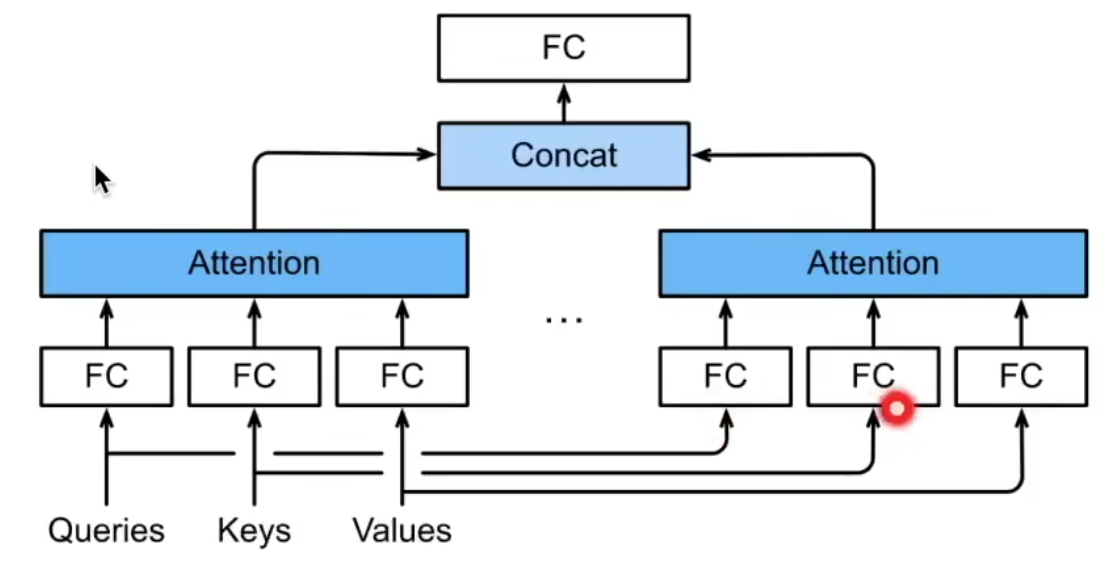
让模型在不同的子空间中学习到不同的信息,增强模型的表达能力。比如,有的头关注局部信息,有的头关注长距离依赖,这样结合起来能更好地捕捉复杂的模式。
def forward(self, q, k, v, mask=None):
"""
q, k, v: (128, 30, 512) => batch, seq len, dim
"""
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
# q, k, v: (128, 30, 512) => (128, 8, 30, 64)
# 512 拆成 8 x 64, 8 是多头注意力的数量
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
# out => new v (softmax(q @ k.T) @ v): (128, 8, 30, 64)
# attention (没用到) => score (q @ k.T): (128, 8, 30, 30)
out, attention = self.attention(q, k, v, mask=mask) # v, score
# 4. concat and pass to linear layer
out = self.concat(out) # 变换回去; (128, 8, 30, 64) => (128, 30, 512)
out = self.w_concat(out) # Linear
return out
残差接收Encoder数据的部分:Q矩阵是Decoder的数据, K, V矩阵是Encoder的输出
Masked Self-Attention
传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入t时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当t时刻运算结束了,才能看到t+1时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。


torch.triu 是 PyTorch 中的一个函数,用于生成一个上三角矩阵。这个函数可以对输入的张量进行操作,并返回一个新的张量,其中指定对角线以上的元素保持不变,而对角线以下的元素被置为零。
input (Tensor): 输入的张量。
diagonal (int, optional): 指定从哪个对角线开始保留元素。默认值为0,表示主对角线。如果 diagonal 为正数,则保留主对角线以上(包括)的元素;如果为负数,则保留主对角线以下(包括)的元素。
# 创建一个全零矩阵
matrix = torch.zeros((n, n))
# 将上三角部分设置为负无穷
matrix = matrix - torch.triu(torch.full((n, n), float('inf')), diagonal=1)
Position Encoding
Transformer模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下
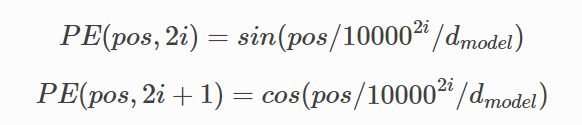
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码.
自注意力本身是不考虑序列顺序的,所以在Transformer中需要通过位置编码来注入位置信息。位置编码可以是固定的,比如正弦余弦函数,也可以是可学习的参数。这样,模型在处理序列时,除了内容信息,还能利用位置信息来理解顺序关系。
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]
层归一化
d:特征向量;b:batch;len: 序列长度
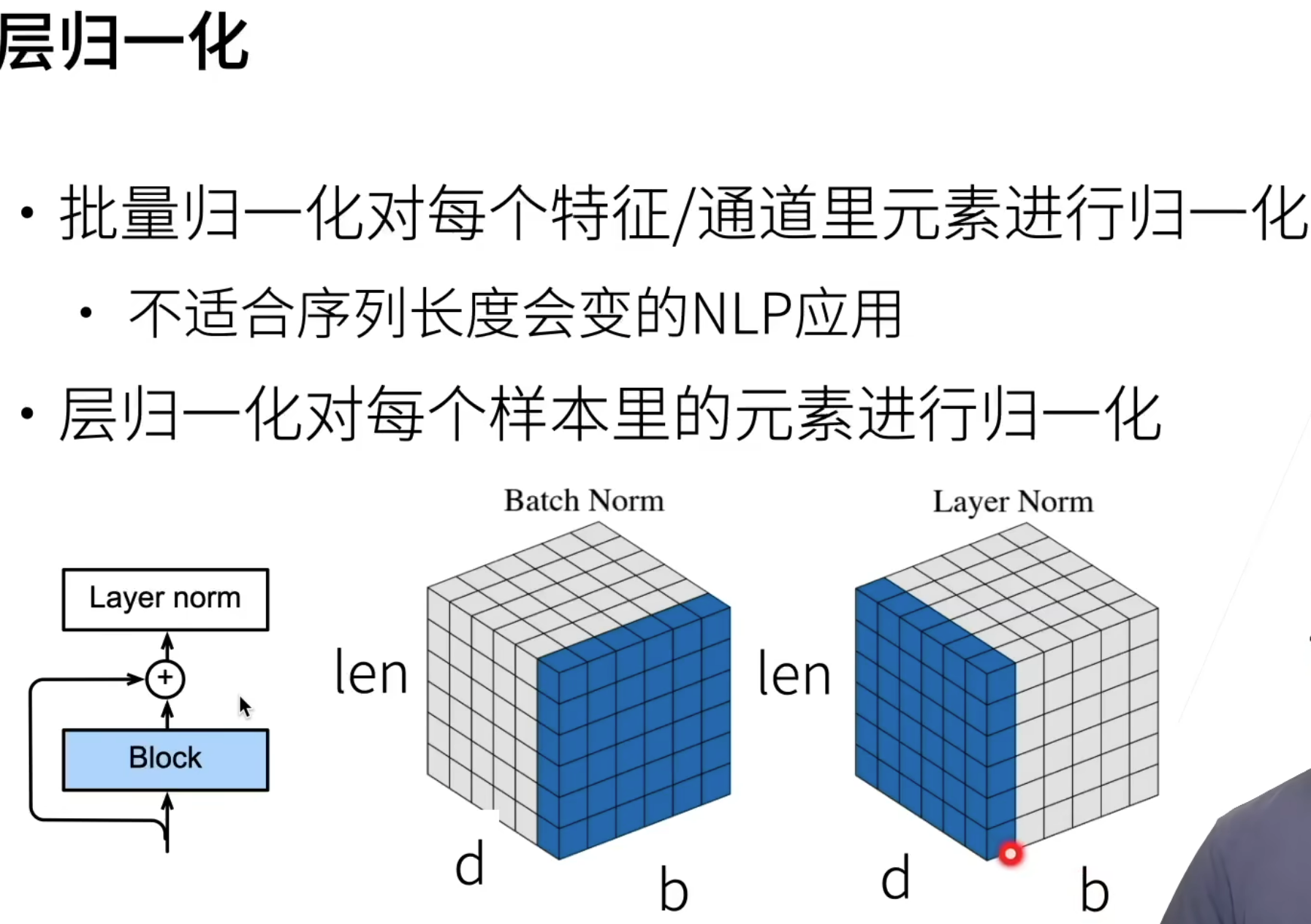
对样本归一化而不是特征, 因为样本是不固定的。
因为每句话的长度不一样即每个b对应的len是会变的,不是一个完整的魔方,而是凹凸不平的。
有b句话,每句话有len个词,每个词由d个特征表示,BN是对所有句子所有词的某一特征做归一化,LN是对某一句话的所有词所有特征做归一化
Feed Forward (Position wise Feed Forward)
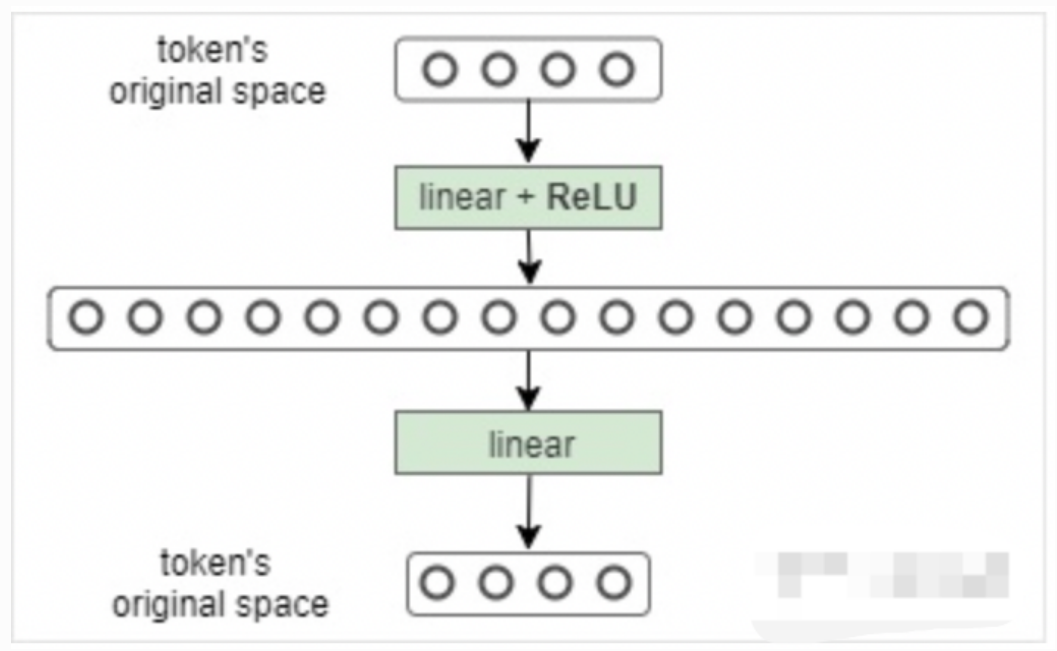
将Multi-Head Attention得到的向量再投影到一个更大的空间(论文里将空间放大了4倍)在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间。
借鉴SVM来理解:SVM对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里token向量里的信息通过Feed Forward Layer被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。
注意区别: 原始的MLP处理的是二维数据例如(128,512),而这个PositionwiseFeedForward 中的Position体现在此处输入的不是二维的数据而是三维的例如(128, 30, 512), 30就是序列的长度。其本质依然是对512的特征维度进行MLP但是输入数据不同。
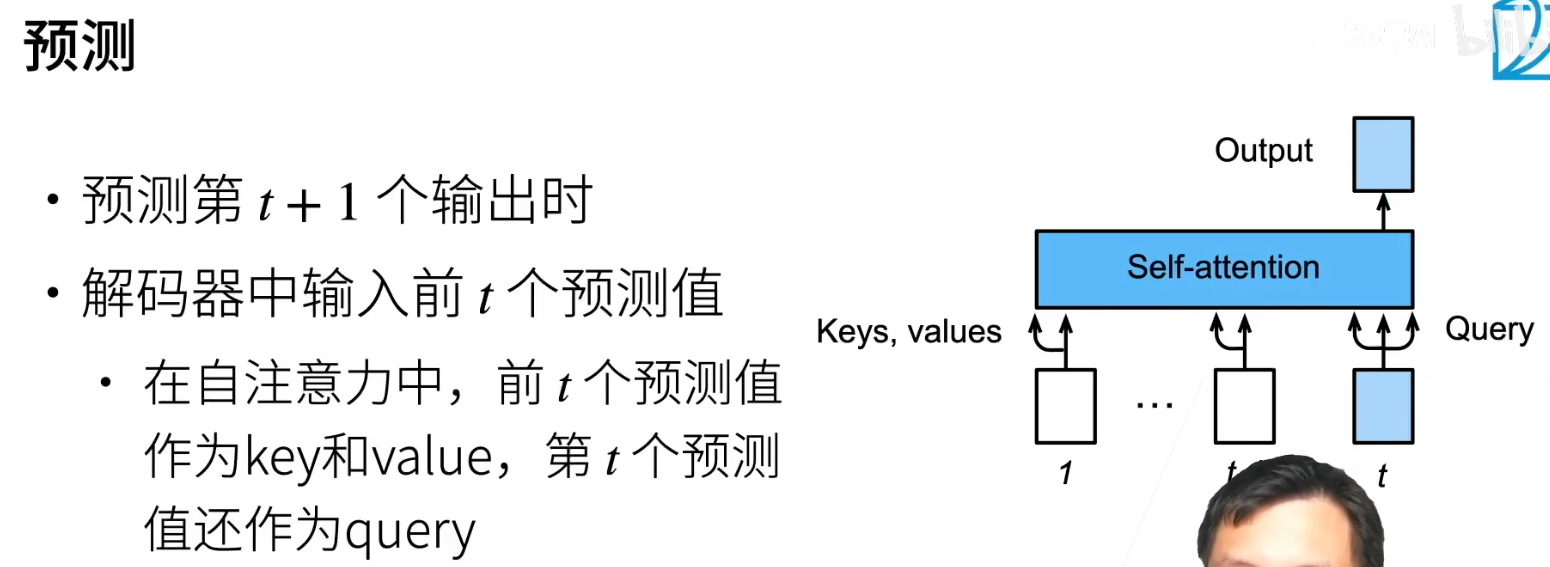
预测(推理)
参考
原论文:Attention Is All You Need
paddle: transformer tutorials
B站跟李沐学AI: Transformer论文逐段精读【论文精读】
知乎
本文来自博客园,作者:漫漫长夜何时休,转载请注明原文链接:https://www.cnblogs.com/ag-chen/p/18148195

 浙公网安备 33010602011771号
浙公网安备 33010602011771号